
 访问官网
访问官网 Github
Github 论文
论文Vid2Avatar: 通过自监督场景分解从野外视频重建3D头像
论文 | YouTube视频 | 项目主页 | SynWild数据集
这是CVPR 2023论文《Vid2Avatar: 通过自监督场景分解从野外视频重建3D头像》的官方代码库。

开始使用
- 克隆此仓库:
git clone https://github.com/MoyGcc/vid2avatar - 创建并激活Python虚拟环境。
conda create -n v2a python=3.7和conda activate v2a - 安装依赖。
cd vid2avatar,pip install -r requirement.txt和cd code; python setup.py develop - 安装 Kaolin。我们使用0.10.0版本。
- 下载 SMPL模型(1.0.0版本,适用于Python 2.7,10个形状主成分),并将它们移动到相应的位置:
mkdir code/lib/smpl/smpl_model/
mv /path/to/smpl/models/basicModel_f_lbs_10_207_0_v1.0.0.pkl code/lib/smpl/smpl_model/SMPL_FEMALE.pkl
mv /path/to/smpl/models/basicmodel_m_lbs_10_207_0_v1.0.0.pkl code/lib/smpl/smpl_model/SMPL_MALE.pkl
下载预处理的演示数据
你可以快速开始尝试Vid2Avatar,使用一个预处理的演示序列,其中包括预训练的检查点。这可以从Google Drive下载,原始视频片段由NeuMan提供。将预处理的演示数据放在data/文件夹下,并将checkpoints文件夹放在outputs/parkinglot/下。
训练
在训练之前,请确保数据配置文件/code/confs/dataset/video.yaml中的metaninfo与预期的训练视频相匹配。你也可以通过更改模型配置文件code/confs/model/model_w_bg中的is_continue标志来继续训练。然后运行:
cd code
python train.py
训练通常需要24-48小时。验证结果可以在outputs/中找到。
测试
运行以下命令以获得最终输出。默认情况下,这会加载最新的检查点。
cd code
python test.py
3D可视化
我们使用AITViewer来可视化3D人体模型。首先安装AITViewer:pip install aitviewer imgui==1.4.1,然后运行以下命令来可视化规范网格(--mode static)或变形网格序列(--mode dynamic):
cd visualization
python vis.py --mode {MODE} --path {PATH}
在自定义视频上使用
- 我们使用ROMP来获取初始SMPL形状和姿势:
pip install --upgrade simple-romp - 安装OpenPose及其Python绑定。
- 将视频帧放在
preprocessing/raw_data/{SEQUENCE_NAME}/frames文件夹下 - 相应地修改预处理脚本
preprocessing/run_preprocessing.sh:数据源、序列名称和性别。数据源默认为"custom",这将估计相机内参。如果已知相机内参,最好提供真实的相机参数。 - 运行预处理:
cd preprocessing和bash run_preprocessing.sh。处理后的数据将存储在data/中。预处理的中间输出可以在preprocessing/raw_data/{SEQUENCE_NAME}/中找到 - 按照上述方式启动训练和测试。数据配置文件
/code/confs/dataset/video.yaml中的metainfo应根据自定义视频进行更改。

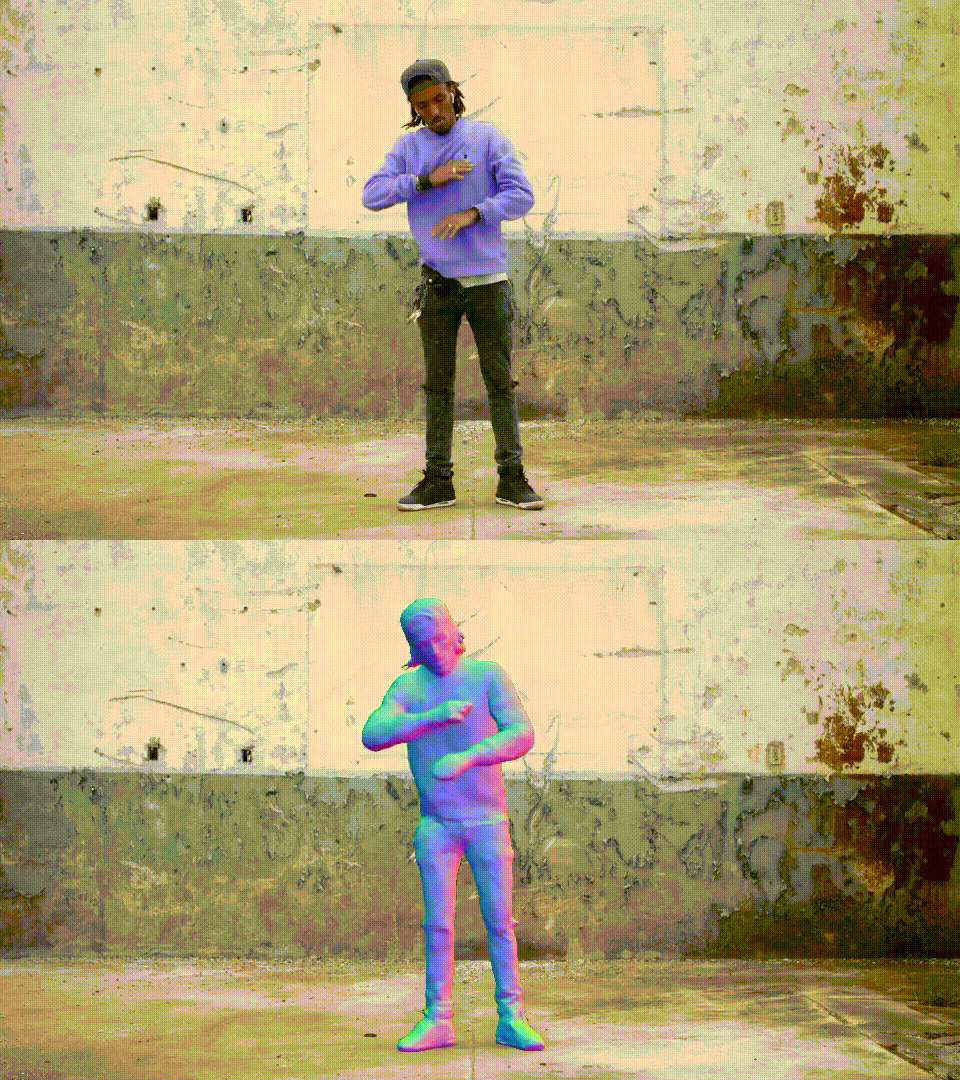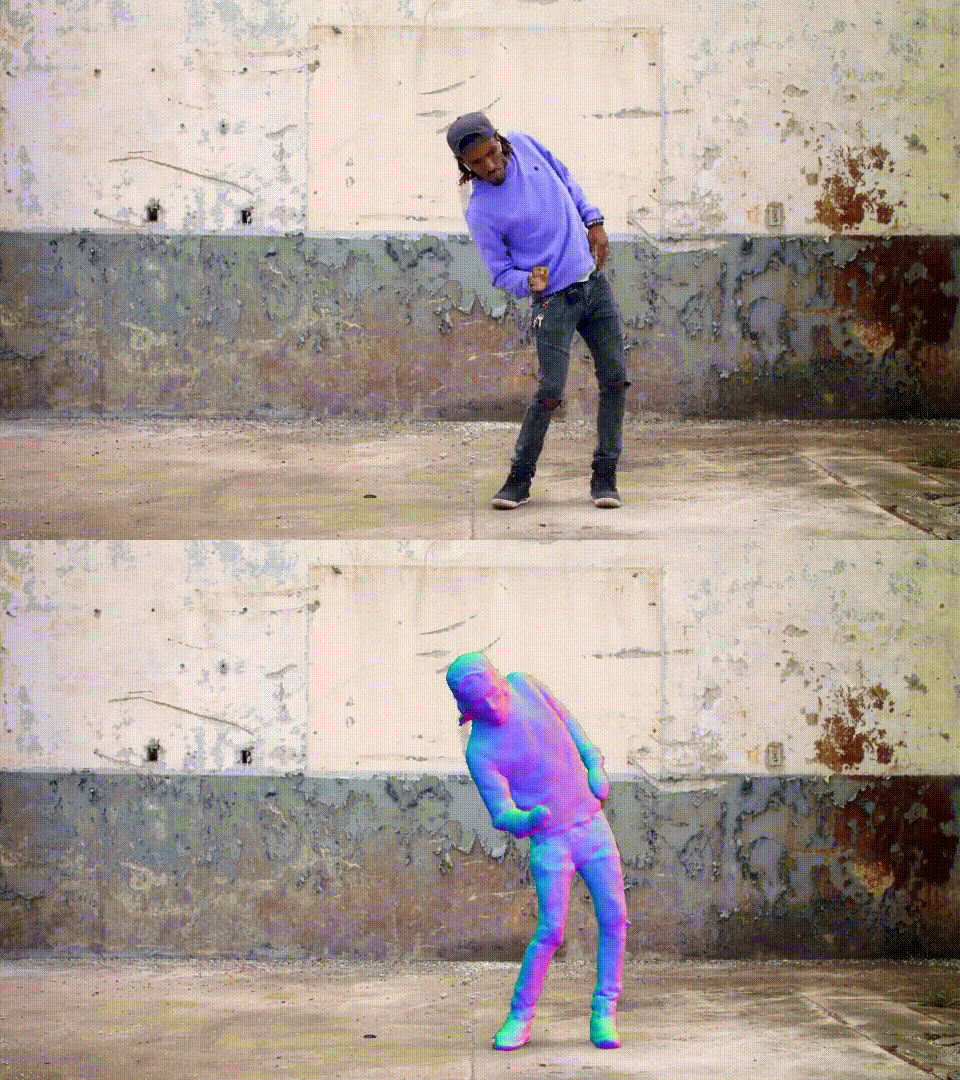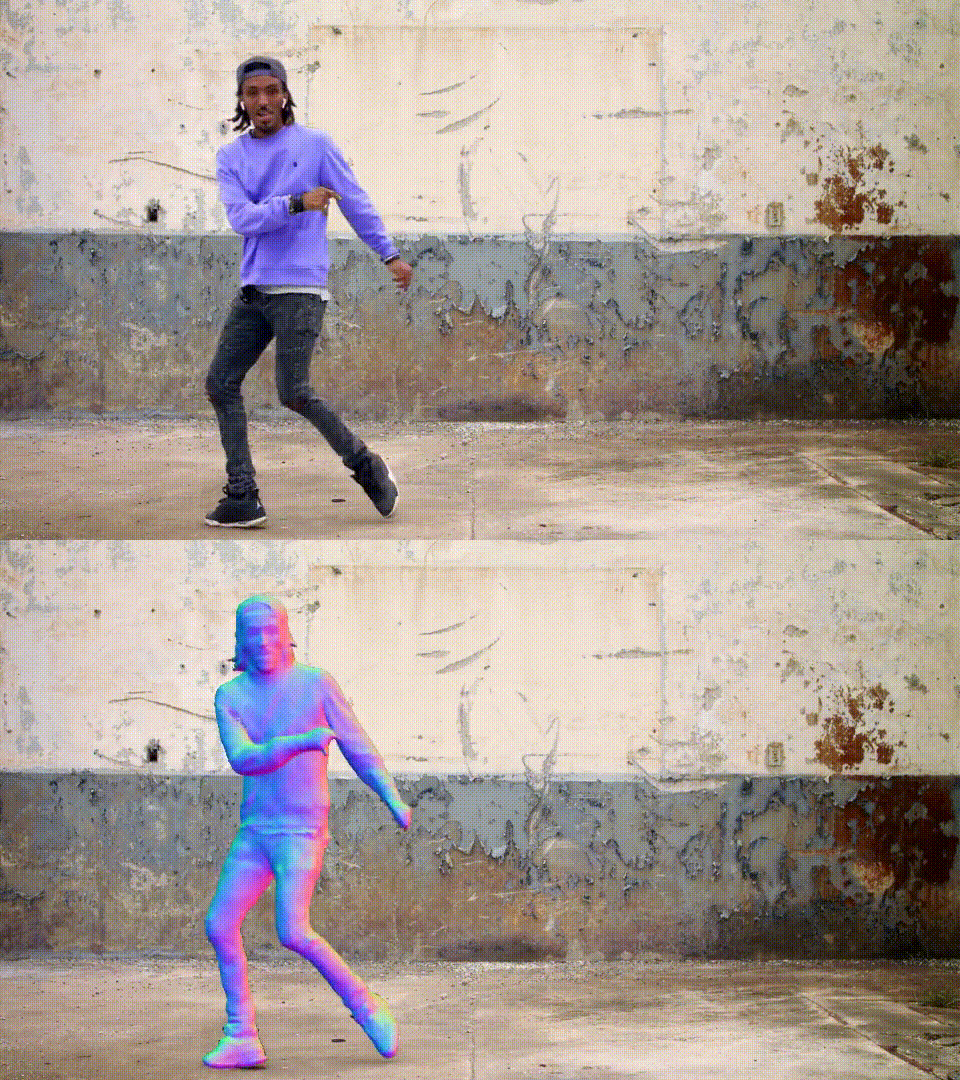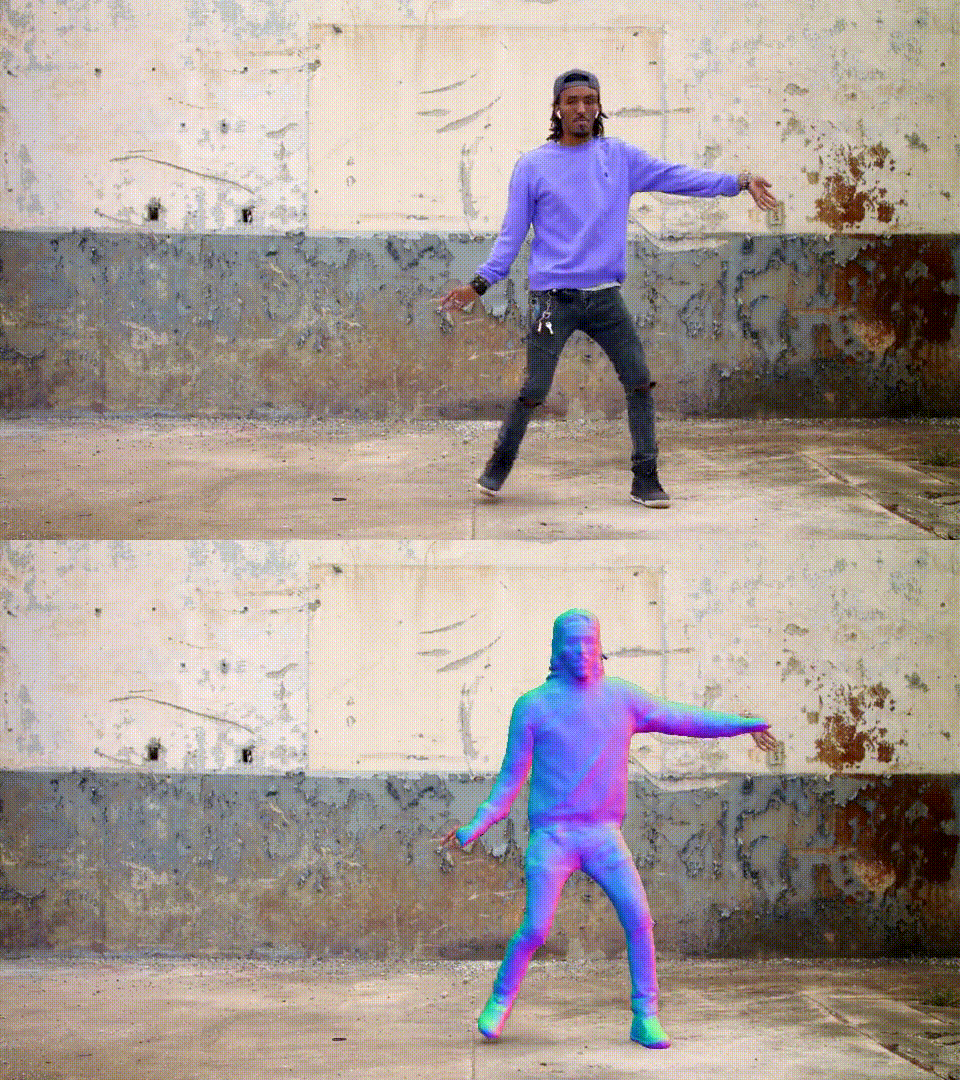

致谢
我们使用了其他优秀研究工作的代码,包括 VolSDF、NeRF++、SMPL-X、Anim-NeRF、I M Avatar 和 SNARF。我们衷心感谢这些作者的杰出工作!我们还要感谢 ICON 和 SelfRecon 的作者讨论实验。
相关工作
以下是我们团队最近的相关人体重建项目:
- Jiang and Chen et. al. - InstantAvatar: 从单目视频中60秒内学习头像
- Shen and Guo et. al. - X-Avatar: 富有表现力的人体头像
- Yin et. al. - Hi4D: 密切人体交互的4D实例分割
@inproceedings{guo2023vid2avatar,
title={Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-supervised Scene Decomposition},
author={Guo, Chen and Jiang, Tianjian and Chen, Xu and Song, Jie and Hilliges, Otmar},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
}











