
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文InternVideo: 多模态理解的视频基础模型
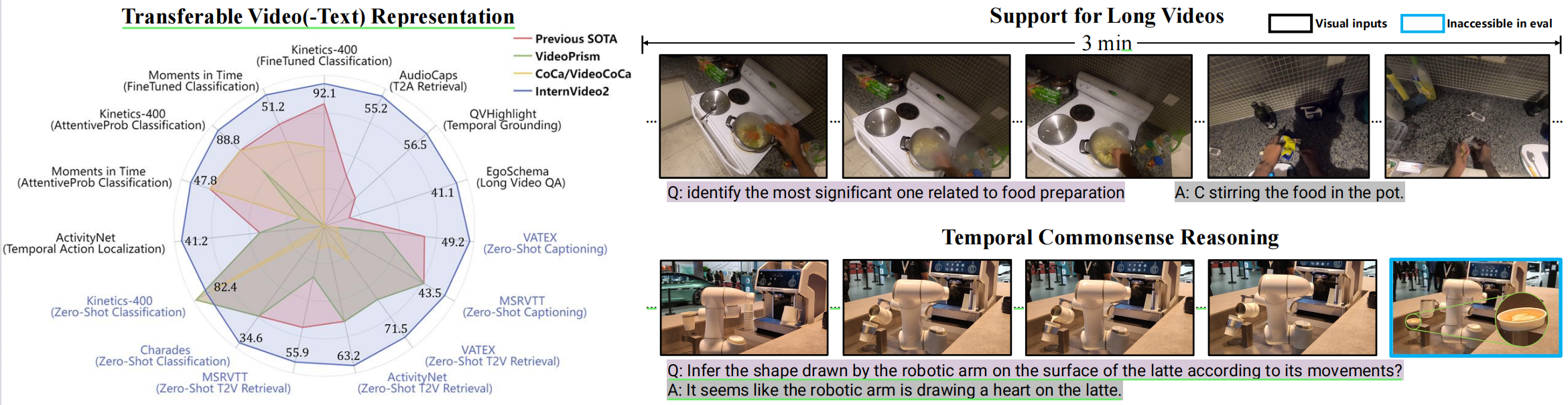
该仓库包含InternVideo系列和相关的视频基础模型工作。
- InternVideo: 通过生成式和判别式学习的通用视频基础模型
- InternVideo2: 扩展多模态视频理解的视频基础模型
- InternVid: 用于多模态理解和生成的大规模视频-文本数据集
更新
2024.08.12: 我们提供了更小的模型,InternVideo2-S/B/L,这些模型是从InternVideo2-1B蒸馏而来。我们还使用MobileCLIP构建了更小的VideoCLIP。2024.08: InternVideo2-Stage3-8B和InternVideo2-Stage3-8B-HD已发布。8B表示使用了InternVideo2-1B和7B LLM。2024.07: InternVid2的视频标注(HuggingFace)已发布。2024.06: InternVid的完整版视频标注(2.3亿视频-文本对)(OpenDataLab | HuggingFace)已发布。2024.04: Intenrvideo2的检查点和脚本已发布。2024.03: InternVideo2的技术报告已发布。2024.01: InternVid(用于视频理解和生成的视频-文本数据集)已被ICLR 2024接受为聚焦展示。2023.07: 在这里发布了视频-文本数据集InternVid,以促进多模态理解和生成。2023.05: 在这里发布了视频指令数据,用于微调端到端视频中心的多模态对话系统,如VideoChat。2023.01: InternVideo的代码和模型已发布。2022.12: InternVideo的技术报告已发布。2022.09: InternVideo的新闻发布(官方 | 网易新闻 | 腾讯新闻)。
联系我们
- 如果您在试用、运行或部署过程中有任何问题,欢迎加入我们的微信群讨论!如果您对项目有任何想法或建议,也欢迎加入我们的微信群讨论!

- 我们正在上海人工智能实验室通用视觉组招聘研究员、工程师和实习生。如果您对与我们一起研究视频基础模型和相关主题感兴趣,请联系王毅(wangyi@pjlab.org.cn)。











