
 PointLLM:赋能大型语言模型理解点云
PointLLM:赋能大型语言模型理解点云
徐润森
王晓龙
王泰
陈亦伦
庞江苗*
林达华
香港中文大学 上海人工智能实验室 浙江大学

🏠 关于

我们推出了PointLLM,这是一个能够理解物体彩色点云的多模态大型语言模型。它可以感知物体类型、几何结构和外观,无需考虑模糊的深度、遮挡或视角依赖性问题。我们收集了一个新颖的数据集,包含66万个简单和7万个复杂的点云-文本指令对,以实现两阶段训练策略。为了严格评估我们模型的感知能力和泛化能力,我们建立了两个基准:生成式3D物体分类和3D物体描述,通过三种不同的评估方法进行评估。
🔥 最新动态
- [2024-07-01] PointLLM已被ECCV 2024接收,获得全部"强烈接受"推荐。🎉 我们正在寻找有动力的学生进行PointLLM相关研究。如果你感兴趣,请发送简历至runsxu@gmail.com!
- [2023-12-29] 我们发布了在线Gradio演示的代码。
- [2023-12-26] 我们发布了模型评估代码,包括ChatGPT/GPT-4评估和传统指标评估。
- [2023-12-08] 我们发布了训练代码和PointLLM-v1.2。在线演示也已升级至v1.2版本。请尽情体验!🎉
- [2023-12-01] 我们发布了论文的更新版本(v2),包含额外的基线比较、改进的人工评估指标、提升的模型性能(PointLLM-v1.2)和其他细节优化。请查看这里的更新版本。
- [2023-10-18] 我们发布了指令跟随数据,包括简单描述和复杂指令。点击此处下载。
- [2023-09-26] 我们发布了推理代码和检查点,以及我们使用的Objaverse彩色点云文件。你可以在自己的机器上与PointLLM对话。
- [2023-08-31] 我们发布了PointLLM的论文和在线gradio演示。快来试试吧!🎉
📋 目录
🤖 在线演示
PointLLM已上线!请访问http://101.230.144.196或OpenXLab/PointLLM体验。
你可以与PointLLM就Objaverse数据集中的模型或你自己的点云进行对话!
如果你有任何反馈,请随时告诉我们!😃
💬 对话示例
| 对话 1 | 对话 2 | 对话 3 | 对话 4 |
|---|---|---|---|
 |  |  |  |
🔍 概述
模型

实验结果
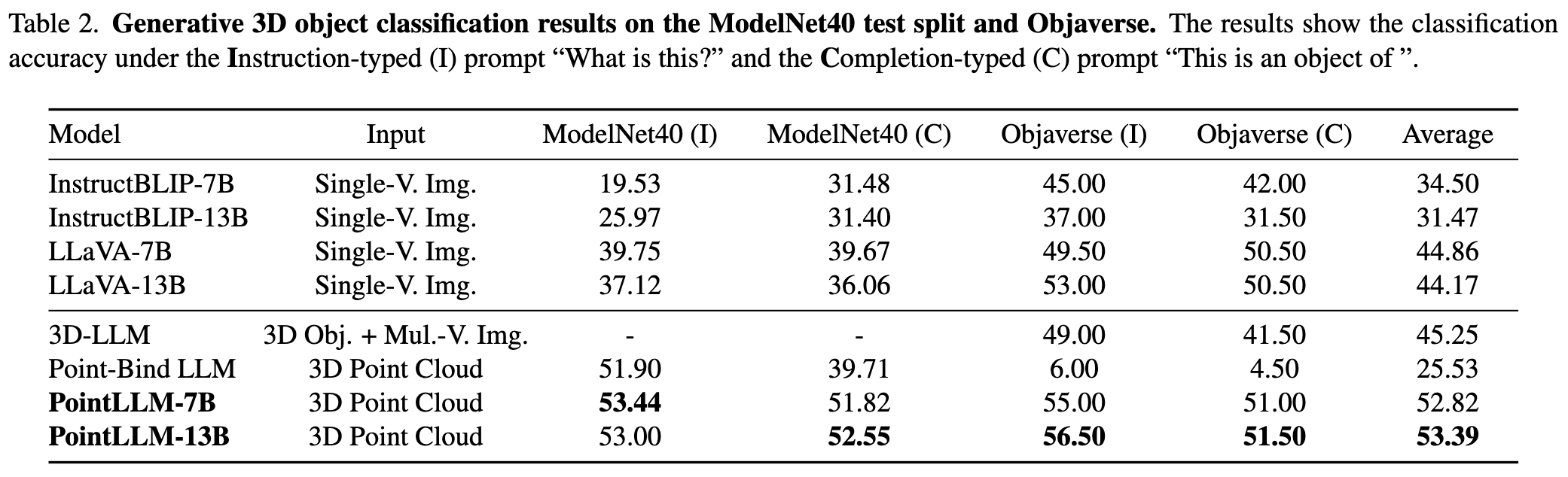
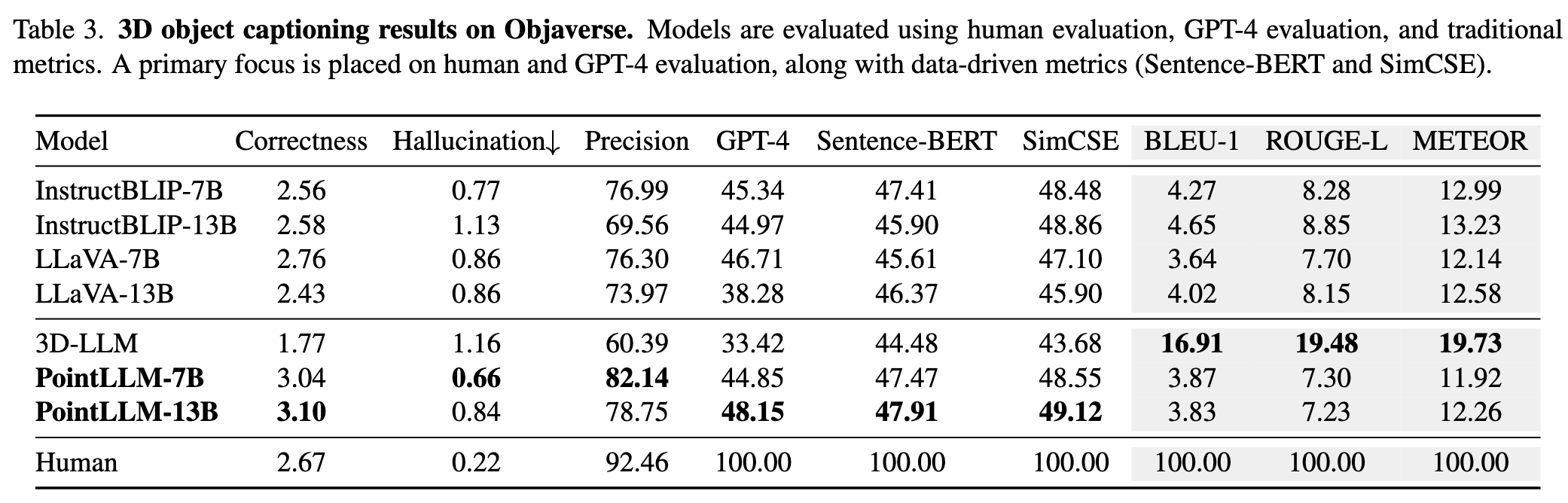
与基线的定量比较
更多结果请参考我们的论文。
与基线的定性比较
更多结果请参考我们的论文。

📦 训练和评估
安装
我们在以下环境下测试了我们的代码:
- Ubuntu 20.04
- NVIDIA驱动:515.65.01
- CUDA 11.7
- Python 3.10.13
- PyTorch 2.0.1
- Transformers 4.28.0.dev(transformers.git@cae78c46)
开始:
- 克隆此仓库。
git clone git@github.com:OpenRobotLab/PointLLM.git
cd PointLLM
- 安装包
conda create -n pointllm python=3.10 -y
conda activate pointllm
pip install --upgrade pip # 启用PEP 660支持
pip install -e .
# * 用于训练
pip install ninja
pip install flash-attn
数据准备
Objaverse训练数据
- 在这里下载660K Objaverse彩色点云的两个压缩文件。它们需要约77GB的存储空间。
- 运行以下命令将两个文件合并为一个并解压。这将产生一个名为
8192_npy的文件夹,其中包含660K个名为{Objaverse_ID}_8192.npy的点云文件。每个文件是一个维度为(8192, 6)的numpy数组,其中前三个维度是xyz,后三个维度是范围在[0, 1]的rgb。
cat Objaverse_660K_8192_npy_split_a* > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gz
- 在
PointLLM文件夹中,创建一个data文件夹,并在目录中创建一个指向解压文件的软链接。
cd PointLLM
mkdir data
ln -s /path/to/8192_npy data/objaverse_data
指令跟随数据
- 在
PointLLM/data文件夹中,创建一个名为anno_data的目录。 - 我们的指令跟随数据,包括简单描述和复杂指令,可以在这里下载。如果您在下载数据时遇到困难(如网络问题),请邮件联系作者。
- 简单描述数据有660K个样本,复杂指令有70K个样本。
- 两种训练数据都基于Objaverse数据集。
- 复杂指令是由GPT-4生成的。
- 将数据文件放入
anno_data目录。目录结构应如下所示:
PointLLM/data/anno_data
├── PointLLM_brief_description_660K_filtered.json
├── PointLLM_brief_description_660K.json
└── PointLLM_complex_instruction_70K.json
- 注意,
PointLLM_brief_description_660K_filtered.json是通过从PointLLM_brief_description_660K.json中删除我们保留作为验证集的3000个对象而筛选得到的。如果您想重现我们论文中的结果,应该使用PointLLM_brief_description_660K_filtered.json进行训练。PointLLM_complex_instruction_70K.json包含来自训练集的对象。 - 如果您想自己生成复杂指令,请参考我们的论文了解其他细节。系统提示位于
pointllm/data/data_generation/system_prompt_gpt4_0613.txt。
评估数据
- 在这里下载我们用于Objaverse数据集基准测试的参考GT
PointLLM_brief_description_val_200_GT.json,并将其放入PointLLM/data/anno_data。我们还在这里提供了我们在训练期间过滤的3000个对象ID。 - 在
PointLLM/data中创建一个名为modelnet40_data的目录。在这里下载ModelNet40点云的测试分割modelnet40_test_8192pts_fps.dat,并将其放入PointLLM/data/modelnet40_data。
训练
下载初始大语言模型和点编码器权重
- 在
PointLLM文件夹中,创建一个名为checkpoints的目录。 - 下载预训练的大语言模型和点编码器:PointLLM_7B_v1.1_init 或 PointLLM_13B_v1.1_init。将它们放在
checkpoints目录中。 - 请注意,上述 "v1.1" 表示我们使用 Vicuna-v1.1 检查点,您不需要再次下载原始 LLaMA 权重。
开始训练
- 对于第一阶段训练,只需运行:
cd PointLLM
scripts/PointLLM_train_stage1.sh
- 第一阶段训练结束后,开始第二阶段训练:
scripts/PointLLM_train_stage2.sh
PointLLM-v1.1 和 PointLLM-v1.2
通常,您不必关心以下内容。这些仅用于复现我们 v1 论文(PointLLM-v1.1)中的结果。如果您想与我们的模型进行比较或将我们的模型用于下游任务,请使用 PointLLM-v1.2(参考我们的 v2 论文),它具有更好的性能。
以下步骤用于复现 PointLLM-v1.1(点击展开)
-
PointLLM v1.1 和 v1.2 使用略有不同的预训练点编码器和投影器。如果您想复现 PointLLM v1.1,请编辑初始大语言模型和点编码器权重目录中的
config.json文件,例如,vim checkpoints/PointLLM_7B_v1.1_init/config.json。 -
更改键
"point_backbone_config_name"以指定另一个点编码器配置:# 从 "point_backbone_config_name": "PointTransformer_8192point_2layer" # v1.2 # 改为 "point_backbone_config_name": "PointTransformer_base_8192point", # v1.1 -
在
scripts/train_stage1.sh中编辑点编码器的检查点路径:# 从 point_backbone_ckpt=$model_name_or_path/point_bert_v1.2.pt # v1.2 # 改为 point_backbone_ckpt=$model_name_or_path/point_bert_v1.1.pt # v1.1
聊天
- 训练好的模型检查点可在这里获得(包括 PointLLM 的不同版本)。
- 运行以下命令,使用
torch.float32数据类型启动聊天机器人,以讨论 Objaverse 的 3D 模型。模型检查点将自动下载。您也可以手动下载模型检查点并指定它们的路径。以下是一个示例:
cd PointLLM
PYTHONPATH=$PWD python pointllm/eval/PointLLM_chat.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data --torch_dtype float32
-
您也可以轻松修改代码以使用 Objaverse 以外的点云,只要输入模型的点云尺寸为 (N, 6),其中前三个维度是
xyz,最后三个维度是rgb(范围在 [0, 1] 内)。您可以将点云采样为 8192 个点,因为我们的模型是在这样的点云上训练的。 -
下表显示了不同模型和数据类型的 GPU 要求。我们建议在适用的情况下使用
torch.bfloat16,这在我们论文的实验中使用。模型 数据类型 GPU 内存 PointLLM-7B torch.float16 14GB PointLLM-7B torch.float32 28GB PointLLM-13B torch.float16 26GB PointLLM-13B torch.float32 52GB
Gradio 演示
- 我们提供了在线 Gradio 演示的代码。您可以运行以下命令在本地启动演示,用于聊天和可视化。
cd PointLLM
PYTHONPATH=$PWD python pointllm/eval/chat_gradio.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data
- 友情提醒:如果您想公开发布演示,请参考 https://www.gradio.app/guides/sharing-your-app#security-and-file-access。
评估
推理
- 运行以下命令进行结果推理。
- 在不同基准测试上进行推理的不同命令(以 PointLLM_7B_v1.2 为例):
cd PointLLM
export PYTHONPATH=$PWD
# Objaverse 上的开放词汇分类
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 # 或 --prompt_index 1
# Objaverse 上的物体描述
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type captioning --prompt_index 2
# ModelNet40 上的封闭集零样本分类
python pointllm/eval/eval_modelnet_cls.py --model_name RunsenXu/PointLLM_7B_v1.2 --prompt_index 0 # 或 --prompt_index 1
- 请检查这两个脚本的默认命令行参数。您可以指定不同的提示、数据路径和其他参数。
- 推理后,结果将保存在
{model_name}/evaluation中,格式如下:
{
"prompt": "",
"results": [
{
"object_id": "",
"ground_truth": "",
"model_output": "",
"label_name": "" # 仅用于 modelnet40 的分类
}
]
}
ChatGPT/GPT-4 评估
- 在 https://platform.openai.com/api-keys 获取您的 OpenAI API 密钥。
- 运行以下命令,使用 ChatGPT/GPT-4 并行评估模型输出(大约花费 1.5 到 2.2 美元)。
cd PointLLM
export PYTHONPATH=$PWD
export OPENAI_API_KEY=sk-****
# Objaverse 上的开放词汇分类
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15
# Objaverse 上的物体描述
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15
ModelNet40上的封闭集零样本分类
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15
3. 评估脚本支持中断和恢复。您可以随时使用`Ctrl+C`中断评估过程。这将保存临时结果。如果评估过程中发生错误,脚本也会保存当前状态。您可以通过再次运行相同的命令从中断处恢复评估。
4. 评估结果将作为另一个字典保存在`{model_name}/evaluation`中。
以下是一些指标的解释:
```bash
"average_score": 我们在论文中报告的GPT评估的描述得分。
"accuracy": 我们在论文中报告的分类准确率,包括ChatGPT在模型输出模糊或不明确时做出的随机选择,以及ChatGPT输出"INVALID"的情况。
"clean_accuracy": 移除那些"INVALID"输出后的分类准确率。
"total_predictions": 预测总数。
"correct_predictions": 正确预测数。
"invalid_responses": ChatGPT输出"INVALID"的次数。
# 调用OpenAI API的一些其他统计数据
"prompt_tokens": ChatGPT/GPT-4提示的总令牌数。
"completion_tokens": ChatGPT/GPT-4完成结果的总令牌数。
"GPT_cost": 整个评估过程的API成本,以美元计算💵。
- 开放步骤评估。您还可以通过传递
--start_eval标志并指定--gpt_type来在推理后立即开始评估。例如:
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 --start_eval --gpt_type gpt-4-0613
传统指标评估
- 对于物体描述任务,运行以下命令使用传统指标(包括BLEU、ROUGE、METEOR、Sentence-BERT和SimCSE)评估模型输出。
python pointllm/eval/traditional_evaluator.py --results_path /path/to/model_captioning_output
- 请注意,我们不建议使用BLEU、ROUGE和METEOR进行评估,因为它们倾向于短描述,无法捕捉语义准确性和多样性。
📝 待办事项
- 添加带检查点的推理代码。
- 发布指令跟随数据。
- 添加训练代码。
- 添加评估代码。
- 添加gradio演示代码。
欢迎社区贡献!👇 如果您需要任何支持,请随时提出问题或联系我们。
- 支持Phi-2 LLM,使PointLLM更易于社区访问。
- 支持中文LLM,如InternLM。
🔗 引用
如果您觉得我们的工作和这个代码库有帮助,请考虑为这个仓库点星🌟并引用:
@article{xu2023pointllm,
title={PointLLM: Empowering Large Language Models to Understand Point Clouds},
author={Xu, Runsen and Wang, Xiaolong and Wang, Tai and Chen, Yilun and Pang, Jiangmiao and Lin, Dahua},
journal={arXiv preprint arXiv:2308.16911},
year={2023}
}
📄 许可证

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
📚 相关工作
让我们一起为3D大语言模型的发展贡献力量!
- Point-Bind & Point-LLM: 将点云与Image-Bind对齐,并利用ImageBind-LLM在没有3D指令数据训练的情况下推理多模态输入。
- 3D-LLM: 使用2D基础模型来编码3D点云的多视图图像。











