
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文nanoT5(编码器-解码器 / 预训练 + 微调)

[论文] | 摘要 | 动机 | 设置 | 预训练 | 微调 | 附加内容 | 结论 | 参考文献 | 引用 | 问题
摘要:
本仓库包含在有限预算(1块A100 GPU,< 24小时)下在PyTorch中复现"大型语言模型"(T5)预训练的代码。我们从随机初始化的T5-base-v1.1(2.48亿参数)模型开始,在C4数据集的英文子集上进行预训练,然后在超自然指令(SNI)基准上进行微调。
在单个GPU上经过约16小时,我们在SNI测试集上达到了40.7 RougeL,相比之下,HuggingFace Hub上提供的原始模型权重在150倍更多的数据上"通过模型和数据并行的组合[...]在Cloud TPU Pod的切片上"(每个切片有1024个TPU)预训练,达到了40.9 RougeL。
我们的核心贡献不是T5模型本身,它遵循HuggingFace的实现。相反,我们优化了训练流程中的其他所有内容,为您的NLP应用/研究提供了一个用户友好的起始模板。最重要的是,我们展示了在有限预算下在PyTorch中预训练T5模型到最高性能是可能的。
动机
尽管预训练的Transformer规模不断增大,研究社区仍然需要易于复现和最新的基线,以快速测试新的研究假设并在小规模上进行。
Andrej Karpathy最近的努力,nanoGPT仓库,使研究人员能够预训练和微调GPT风格(仅解码器)的语言模型。另一方面,Cramming选择为有限计算设置找到最佳的BERT风格(仅编码器)预训练方案。
通过nanoT5,我们希望填补一个空白(社区请求:#1 #2 #3 #4 #5),提供一个可访问的研究模板来预训练和微调T5风格(编码器-解码器)模型。据我们所知,这是首次尝试在PyTorch中复现T5 v1.1预训练(之前可用的实现都是在Jax/Flax中)。
**我们创建这个仓库是为了那些想自己预训练T5风格模型并评估其在下游任务上性能的人。**这可能出于各种原因:
- 您是计算资源有限的学术研究人员(像我一样),提出了一个基于T5模型的有前景的想法,因此需要一个流程来评估它;
- 您有一个内部数据集,您认为比原始预训练数据集(C4)更适合您的下游任务;
- 您想要试验持续预训练或想要在T5预训练目标的基础上构建。
如果您不需要预训练T5模型,最好从HuggingFace Hub下载权重。由于我们在有限计算资源下工作,我们的检查点性能较差。
在这个项目中,我们公开(出于研究目的)并优化了T5训练流程中的所有内容,除了模型实现。我们包含了T5模型的简化实现(这对教学和学习目的很好),但是我们没有使用最新技术(如张量或流水线并行)进行优化,因为这会使代码变得更复杂,而且在小规模上并不需要。**最重要的是,我们的代码基于PyTorch,因为对TPU的访问有限。**主要特点:
- **数据集:**C4数据集的下载和预处理与模型训练同时进行。C4数据集大于300GB,下载需要几个小时,预处理甚至更长。这个代码库实现了即时处理,对训练时间和性能没有显著影响(我们没有观察到,尽管对于旧CPU(<8核)或慢速互联网连接可能会发生)。因此,您可以在几分钟内开始预训练您自己的T5模型。
- 模型优化器 / 学习率调度器:原始T5使用内存高效的Adafactor优化器。另一方面,一项关于预训练T5的研究报告说使用AdamW训练不收敛,我们认为这很奇怪,因为AdamW理论上比Adafactor有更好的近似。我们通过几次消融实验分析了这种差异的来源。尽管Adafactor和AdamW之间有许多细微差别,但确保Adafactor收敛的是按其均方根(RMS)进行的矩阵级学习率缩放。我们通过RMS缩放增强了AdamW实现,观察到它在预训练期间变得更稳定,达到更好的验证损失,并且更快。
- **公开性和简洁性:**我们尝试平衡训练流程的实现,保持其可定制性的同时保留足够的抽象级别。我们使用HuggingFace Accelerator来实现检查点保存、梯度累积、梯度裁剪和将张量移动到正确设备等操作。我们使用neptune.ai进行实验跟踪,使用hydra进行超参数管理。此外,我们还公开了T5模型、训练循环、数据预处理等的简化实现。
- **效率:**我们使用混合精度训练(TF32 & BF16)、PyTorch 2.0编译,并利用了已建立的优化教程中列出的所有优化 #1 #2。
设置
环境 & 硬件:
git clone https://github.com/PiotrNawrot/nanoT5.git
cd nanoT5
conda create -n nanoT5 python=3.8
conda activate nanoT5
pip install -r requirements.txt
以上命令将导致以下pip freeze,截至2023年6月18日。
我们还包含了我们的lscpu和nvidia-smi。
预训练:
参考:
T5 v1.1的作者报告在C4的保留集上经过2^16步训练后,负对数似然(NLL)达到了1.942。
传统优化器(Adafactor)和学习率调度(反平方根)
我们遵循原始的预训练实验设置,包括数据集(C4)、训练目标(跨度填充)、模型架构(T5-Base)、优化器(Adafactor)和学习率调度(反平方根)。
我们在保留集上的负对数似然为1.995,略差于参考值。
AdamW和RMS缩放优化器以及余弦学习率调度
我们还尝试了AdamW优化器(而不是原始的Adafactor),因为理论上它应该在训练过程中提供更好的稳定性。它不使用梯度二阶矩的低秩近似,而是通过在内存中存储每个参数的移动平均值来直接估计。但是,使用AdamW训练会发散,类似于这项关于T5预训练的研究。通过多次消融实验,我们发现按矩阵均方根(RMS)进行学习率缩放是Adafactor收敛的关键。我们通过RMS缩放增强了AdamW的实现,观察到它收敛了,在预训练过程中变得更加稳定,而且略快(它直接从内存中检索二阶矩,而不是通过矩阵乘法近似)。
然而,当与反平方根学习率调度配对时,AdamW的表现不如Adafactor。在最终实验中,我们用余弦学习率调度替代了反平方根。我们在保留集上实现了1.953的负对数似然,显著优于使用反平方根调度的Adafactor。我们认为这是我们的默认预训练配置。
使用不同优化器(Adafactor vs AdamW)和调度器(ISR vs 余弦)的训练损失。其余超参数遵循原始T5 v1.1论文。
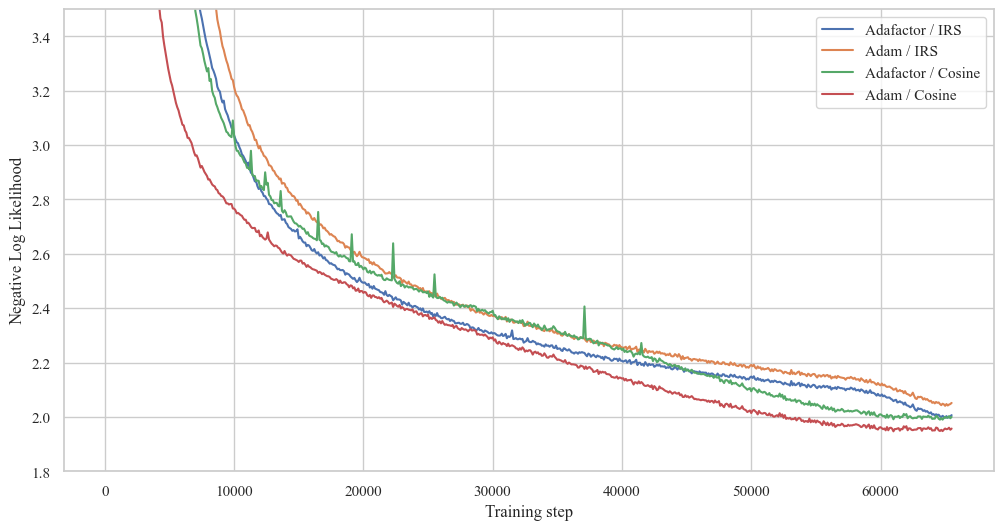
C4保留集上的负对数似然
| 反平方根 | 余弦 | |
|---|---|---|
| Adafactor | 1.995 | 1.993 |
| AdamW | 2.040 | 1.953 |
示例
要重现上述任何实验,请选择以下超参数的任意组合:
python -m nanoT5.main \
optim.name={adafactor,adamwscale} \
optim.lr_scheduler={legacy,cosine}
如果你能安装PyTorch 2.0,我们建议在预训练时添加model.compile=true标志。
假设你无法访问80GB的A100 GPU。在这种情况下,你可以通过optim.grad_acc=steps增加梯度累积步数,其中batch_size必须能被steps整除。
优化过程的摘要每100步以以下格式打印。例如:
[train] Step 100 out of 65536 | Loss --> 59.881 | Grad_l2 --> 61.126 | Weights_l2 --> 7042.931 | Lr --> 0.010 | Seconds_per_step --> 1.385 |
效率统计:
以下是我们预训练实验的效率统计。我们报告了模型完成1个预训练步骤所需的时间,以及根据默认配置的总预训练时间。请注意,我们需要增加optim.grad_acc steps以适应不同于BF16的精度。
| 混合精度格式 | Torch 2.0 compile | 梯度累积步数 | 预训练(1步) | 总预训练时间 |
|---|---|---|---|---|
| FP32 | 否 | 2 | ~4.10s | ~74.6h |
| TF32 | 否 | 2 | ~1.39s | ~25.3h |
| BF16 | 否 | 2 | ~1.30s | ~23.7h |
| TF32 | 是 | 2 | ~0.95s | ~17.3h |
| BF16 | 是 | 1 | ~0.56s | ~10.2h |
微调:
为了微调我们的模型,我们使用了流行的元数据集Super Natural-Instructions (SNI),它聚合了许多任务的数据集。这个元数据集被用于微调许多最近的LLM,例如FlanT5、BLOOM和Tk-Instruct。虽然FlanT5和BLOOM除了SNI还使用了其他语料库,但Tk-Instruct的流程包括从预训练的T5模型开始,仅在SNI上进行微调。
在本仓库中,我们重现了Tk-Instruct的微调结果,并遵循他们的流程来评估我们预训练的模型。
下载Super-Natural Instructions数据:
git clone https://github.com/allenai/natural-instructions.git data
运行微调:
我们严格遵循Tk-Instruct的微调配置。目前尚不清楚Tk-Instruct是从常规检查点(google/t5-v1_1-base)初始化的,还是从专门适用于语言建模的持续训练检查点(google/t5-base-lm-adapt)初始化的。因此,我们决定评估这两种情况。运行以下命令以重现Tk-Instruct实验:
python -m nanoT5.main task=ft \
model.name={google/t5-v1_1-base,google/t5-base-lm-adapt} \
model.random_init={true,false} \
model.checkpoint_path={"","/path/to/pytorch_model.bin"}
设置model.random_init=false model.checkpoint_path=""对应从HuggingFace Hub下载预训练权重。
设置model.random_init=false model.checkpoint_path="/path/to/pytorch_model.bin"对应使用nanoT5预训练的权重。
设置model.random_init=true model.checkpoint_path=""对应随机初始化。
不同预训练预算下保留测试集上的Rouge-L分数:
在下图中,我们比较了本仓库中在不同时间预算下(4、8、12、16、20、24小时)训练的模型性能与通过Huggingface Hub获得的原始T5-base-v1.1模型权重及其为语言建模适配的版本(google/t5-base-lm-adapt)。我们观察到,在单个GPU上训练16小时的模型平均RougeL值仅比原始T5-base-v1.1模型低0.2,尽管预训练数据量少了150倍(根据T5论文,他们以2048的批量大小预训练模型一百万步。我们的16小时配置以256的批量大小进行53332步)。专门为语言建模适配的检查点(google/t5-base-lm-adapt)表现优于原始T5-base-v1.1模型和我们的模型,但这超出了本仓库的范围。
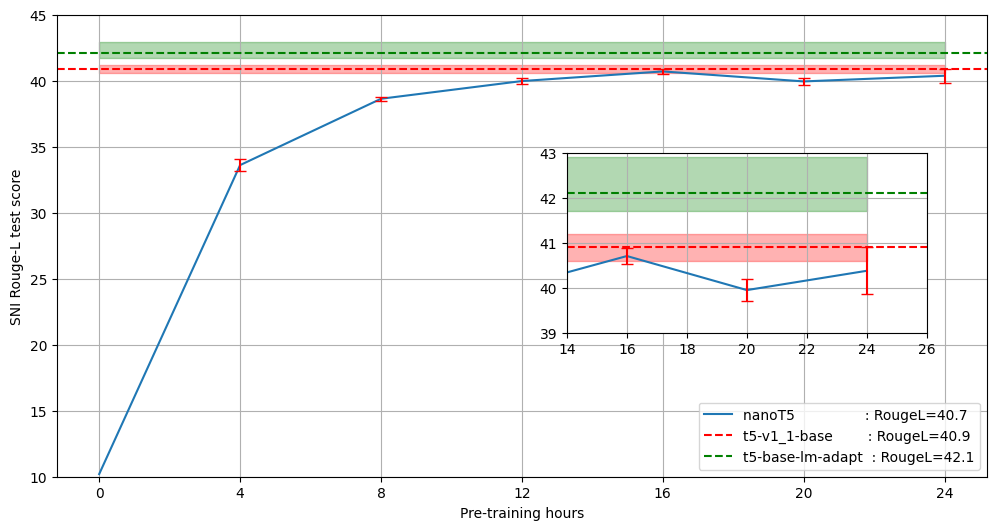
我们在HuggingFace Hub上分享了经过24小时预训练的模型权重,您可以下载并使用nanoT5在SNI上进行微调。我们还分享了微调损失曲线。
单次微调步骤耗时约0.18秒,完整微调需要约1小时。
额外内容:
我们尝试过但未成功的方法:
- 不同的优化器: 我们尝试了最新的优化器,如Lion、Sophia,但它们都不如具有RMS缩放的AdamW表现好。
- 位置嵌入: 我们尝试用ALiBi替换T5的学习相对位置嵌入。可能的好处包括减少参数和加快训练与推理速度。此外,如果ALiBi有效,我们可以添加Flash Attention,它目前只支持非参数化偏置(T5偏置是可训练的)。然而,使用ALiBi训练不太稳定,预训练损失也更差。
- FP16精度: 所有使用FP16精度的实验在不同种子下都出现了发散。
结论:
我们展示了在有限预算(1个A100 GPU,< 24小时)下,使用PyTorch成功预训练"大型语言模型"(T5)是可能的。我们公开了我们的代码库、配置和训练日志,以提高NLP研究的可及性。我们期待听到您进一步改进代码库的建议。
致谢:
感谢Edoardo Maria Ponti的反馈!
参考文献:
- T5论文
- T5 v1.1论文
- Super-Natural Instructions论文
- HuggingFace Flax脚本
- Karpathy的nanoGPT
- Instruct-GPT代码库(Super-Natural Instructions)
- 关于在HuggingFace预训练荷兰语T5的博客
引用
如果您发现本仓库有用,请考虑引用关于这项工作的论文。
@inproceedings{nawrot-2023-nanot5,
title = {nano{T}5: Fast {\&} Simple Pre-training and Fine-tuning of {T}5 Models with Limited Resources},
author = {Nawrot, Piotr},
year = 2023,
month = dec,
booktitle = {Proceedings of the 3rd Workshop for Natural Language Processing Open Source Software (NLP-OSS 2023)},
publisher = {Association for Computational Linguistics},
doi = {10.18653/v1/2023.nlposs-1.11},
url = {https://aclanthology.org/2023.nlposs-1.11}
}
下面您还可以找到一项使用nanoT5进行实验的出色工作。
@article{Kaddour2023NoTN,
title={No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-based Language Models},
author={Jean Kaddour and Oscar Key and Piotr Nawrot and Pasquale Minervini and Matt J. Kusner},
journal={ArXiv},
year={2023},
volume={abs/2307.06440},
}
问题:
如果您有任何问题,欢迎提出Github issue或直接联系我:piotr.nawrot@ed.ac.uk












{kind=link}
{kind=link}