
 访问官网
访问官网 Github
Github 文档
文档


你有一个环境、一个 PyTorch 模型和一个强化学习框架,它们本应一起工作,但却不能。PufferLib 是一个包装层,它使复杂游戏环境的强化学习变得像 Atari 上的强化学习一样简单。你只需编写一个原生 PyTorch 网络和一个简短的环境绑定;PufferLib 会处理剩下的一切。
我们所有的文档都托管在 github.io 上。如需支持,请在 Discord 上联系 @jsuarez5341 -- 在开 issue 之前请先在这里发帖。我也在寻找有兴趣为其他环境和强化学习框架添加绑定的贡献者。
演示
当前的 demo.py 是 CleanRL PPO 的升级版,具有优化的 LSTM 支持、详细的性能指标、本地仪表板、异步 envpool 采样、检查点保存、wandb 扫描等功能。它有一个强大的 --help 命令,可以根据指定的环境和策略生成选项。超参数在 config.yaml 中。以下是一些例子:
# 使用多进程训练 minigrid。将其保存为基准。
python demo.py --env minigrid --mode train --vec multiprocessing
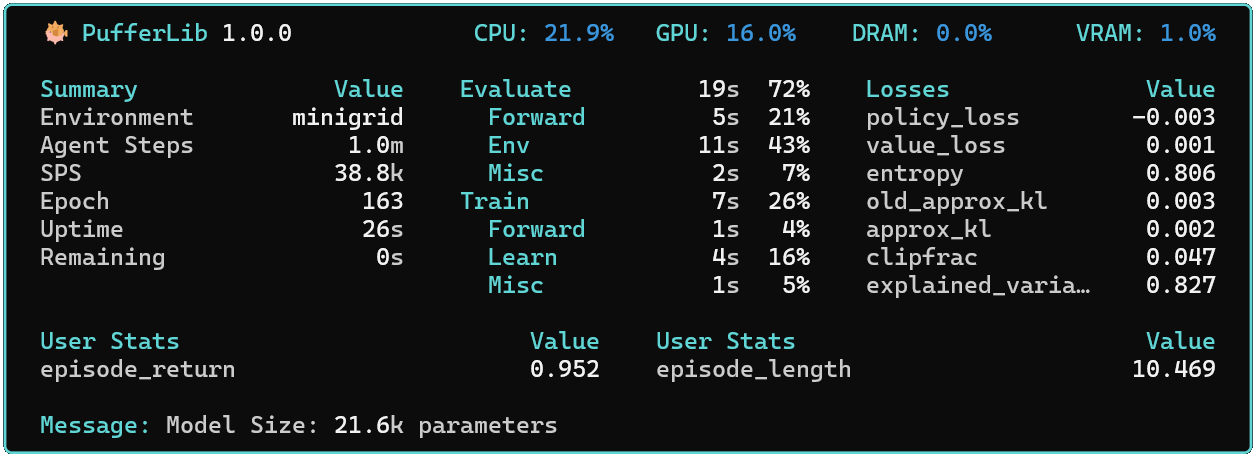
# 加载当前 minigrid 基准并在本地渲染
python demo.py --env minigrid --mode eval --baseline
# 使用串行向量化训练 squared 并将其保存为 wandb 基准
# 然后,加载当前 squared 基准并在本地渲染
python demo.py --env squared --mode train --baseline
python demo.py --env squared --mode eval --baseline
# 使用随机策略在本地渲染 NMMO
python demo.py --env nmmo --mode eval
# 为你的机器自动调整向量化设置
python demo.py --env breakout --mode autotune











