
 Github
Github Huggingface
Huggingface 文档
文档

🤗 Hugging Face | 🤖 ModelScope | Kaggle | 📑 博客 | 📖 文档
微信 | 🫨 Discord
访问我们的Hugging Face或ModelScope组织(点击上方链接)。搜索以Qwen2-Math-开头的检查点,您就能找到所需的一切!尽情使用吧!
简介
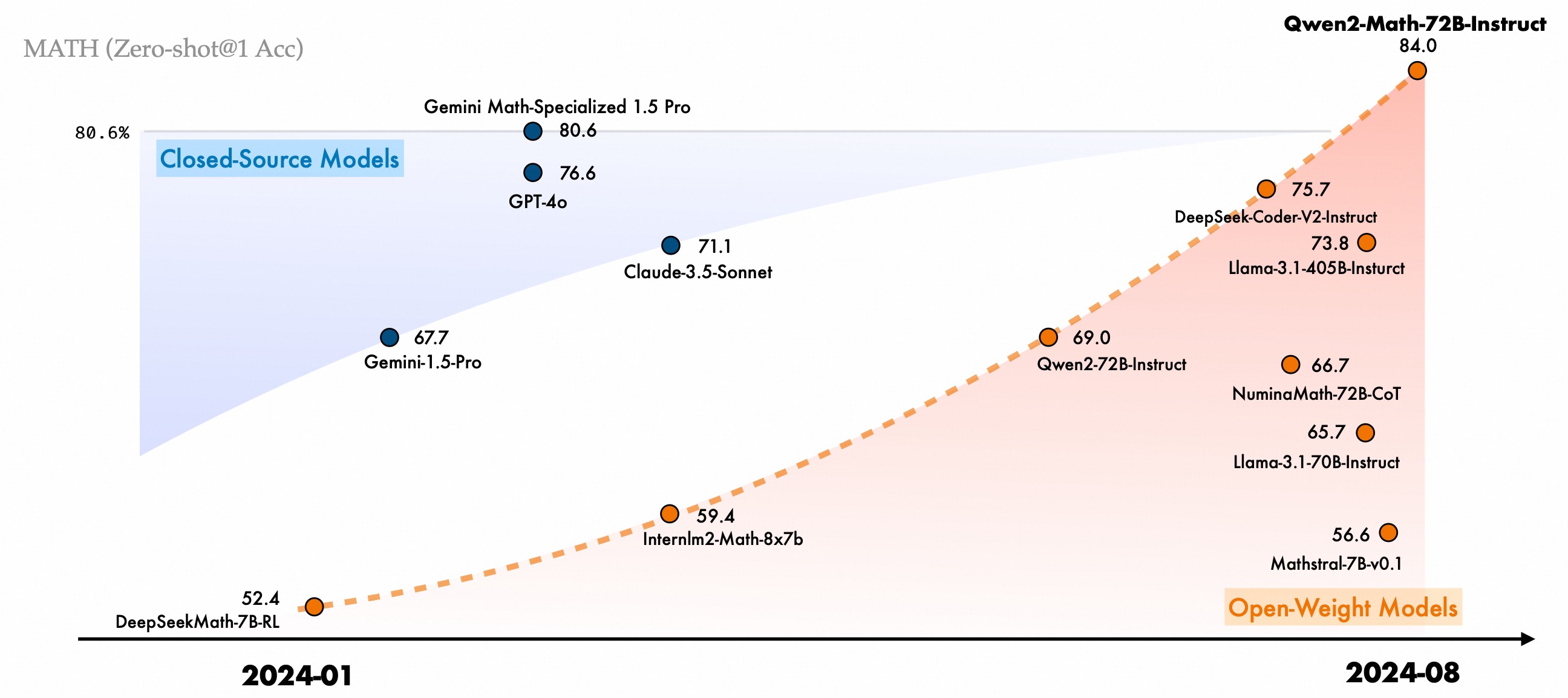
过去一年,我们在研究和提升大语言模型的推理能力方面投入了大量精力,特别关注其解决算术和数学问题的能力。今天,我们很高兴向大家介绍我们Qwen2系列的一系列数学专用大语言模型:Qwen2-Math和Qwen2-Math-Instruct-1.5B/7B/72B。Qwen2-Math是基于Qwen2 LLM构建的一系列专门用于数学的语言模型,其数学能力显著优于开源模型,甚至超越了闭源模型(如GPT4o)。我们希望Qwen2-Math能够通过解决需要复杂、多步逻辑推理的高级数学问题,为科学界做出贡献。
详细的性能和介绍请参阅这篇 📑 博客。
🚨 此模型主要支持英语。我们将很快发布双语(英语和中文)数学模型。
要求
- 对于Qwen2-Math模型,需要
transformers>=4.40.0。推荐使用最新版本。
[!Warning]
🚨 这是必须的,因为`transformers`从`4.37.0`版本开始集成了Qwen2的代码。
关于GPU内存需求和相应的吞吐量,请参见Qwen2的类似结果这里。
快速开始
[!Important]
Qwen2-Math-72B-Instruct是用于聊天的指令模型;
Qwen2-Math-72B是基础模型,通常用于少样本推理,作为微调的更好起点。
🤗 Hugging Face Transformers
Qwen2-Math的部署和推理方式与Qwen2相同。这里我们展示一个代码片段,向您展示如何使用transformers的聊天模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2-Math-7B-Instruct"
device = "cuda" # 加载模型的设备
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "找出满足方程$4x+5 = 6x+7$的$x$值。"
messages = [
{"role": "system", "content": "你是一个有帮助的助手。"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
🤖 ModelScope
我们强烈建议用户,尤其是中国大陆的用户使用ModelScope。snapshot_download可以帮助您解决下载检查点的问题。
性能
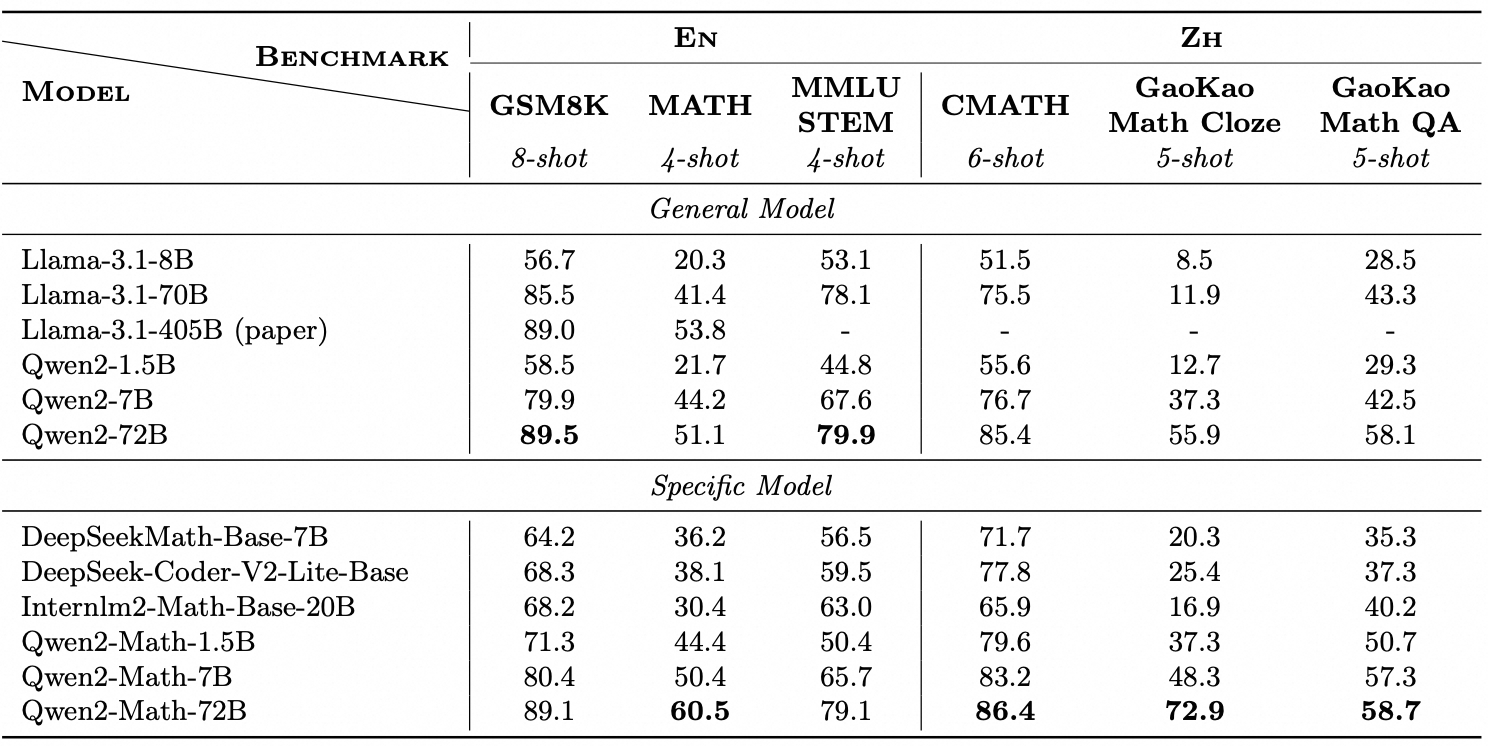
我们在三个广泛使用的英语数学基准测试GSM8K、Math和MMLU-STEM上评估了我们的Qwen2-Math-Base模型。我们还评估了三个中文数学基准测试:CMATH、高考数学完形填空和高考数学问答。所有评估都使用少样本思维链提示。
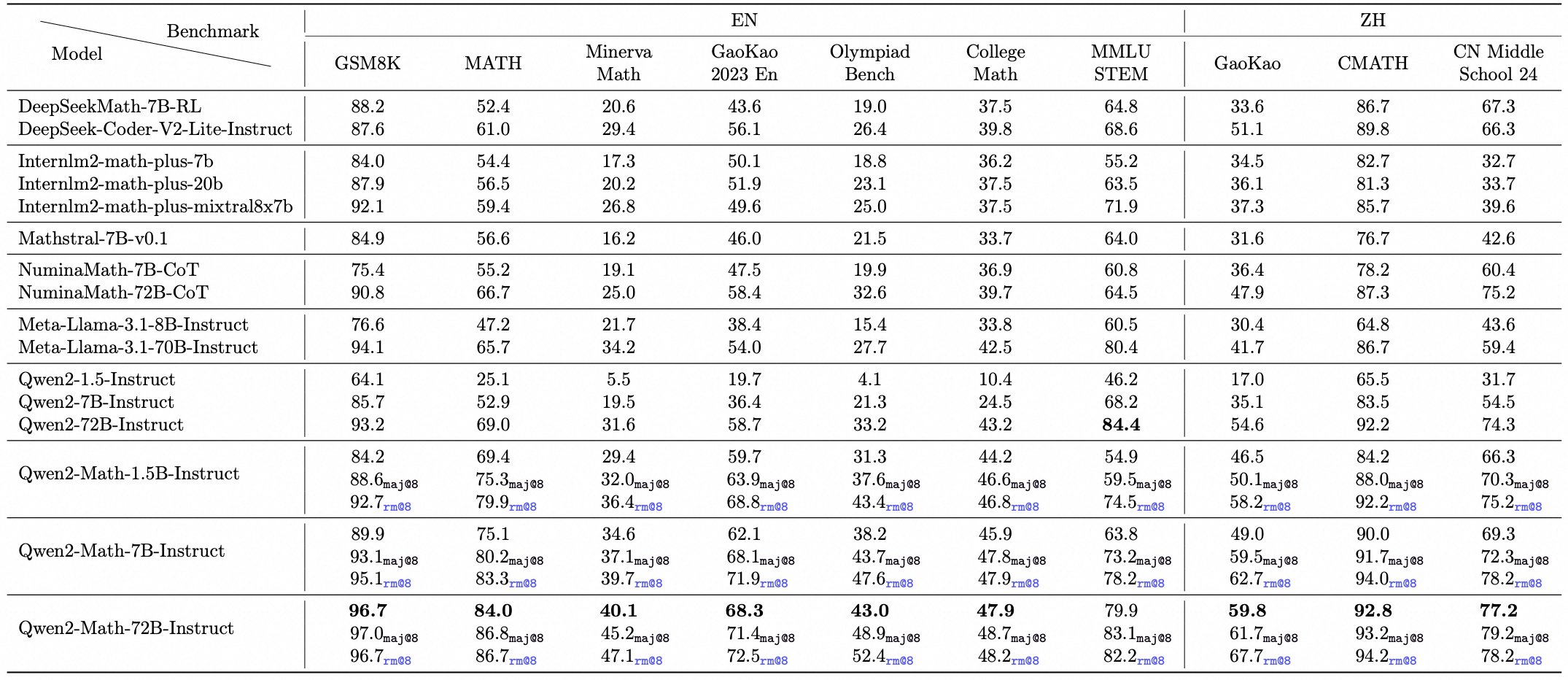
我们在英语和中文的数学基准测试上评估了Qwen2-Math-Instruct。除了广泛使用的基准测试(如GSM8K和Math)外,我们还加入了更具挑战性的考试,以全面检查Qwen2-Math-Instruct的能力,如OlympiadBench、CollegeMath、高考、AIME2024和AMC2023。对于中文数学基准测试,我们使用了CMATH、高考(2024年中国高考)和中国中考24(2024年中国中考)。
我们在所有基准测试中报告了贪婪解码、Maj@8和RM@8的零样本性能,除了多项选择基准测试(包括MMLU STEM以及高考和中考中的多项选择题)使用5样本设置。Qwen2-Math-Instruct在同等规模的模型中取得了最佳性能,其中RM@8优于Maj@8,特别是在1.5B和7B模型中。这证明了我们的数学奖励模型的有效性。
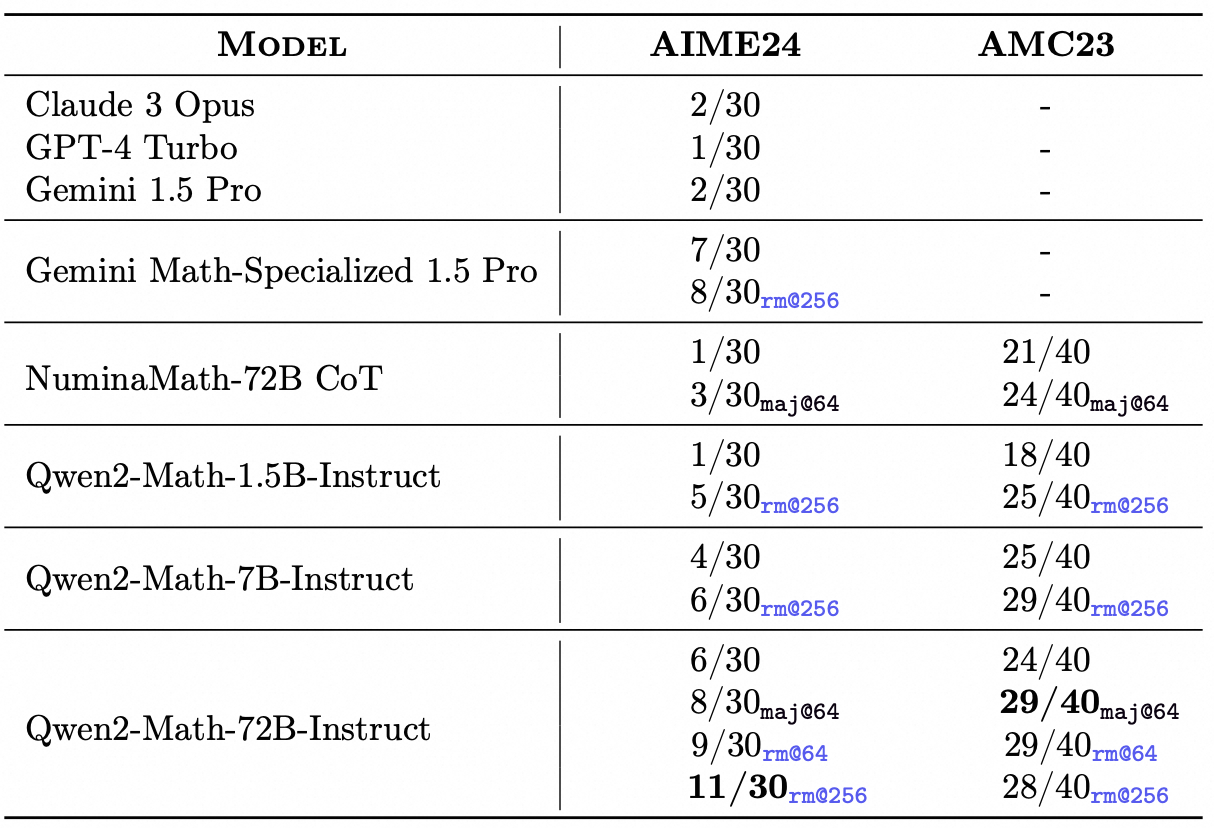
在更复杂的数学竞赛评估中,如AIME 2024和AMC 2023,Qwen2-Math-Instruct在各种设置下(包括贪婪、Maj@64、RM@64和RM@256)也表现出色。
评估
我们的评估改编自math-evaluation-harness。 欢迎使用evaluation目录中的脚本复现Qwen2-Math系列所有指令模型的结果。
要求
评估前,请使用以下命令安装所需包:
cd latex2sympy
pip install -e .
cd ..
pip install -r requirements.txt
pip install vllm==0.5.1 --no-build-isolation
pip install transformers=4.42.3
严格遵循要求的版本对复现报告的分数至关重要。
运行
使用以下命令评估Qwen2-Math-Instruct系列模型:
PROMPT_TYPE="qwen-boxed"
# Qwen2-Math-1.5B-Instruct
export CUDA_VISIBLE_DEVICES="0"
MODEL_NAME_OR_PATH="Qwen/Qwen2-Math-1.5B-Instruct"
bash sh/eval.sh $PROMPT_TYPE $MODEL_NAME_OR_PATH
# Qwen2-Math-7B-Instruct
export CUDA_VISIBLE_DEVICES="0"
MODEL_NAME_OR_PATH="Qwen/Qwen2-Math-7B-Instruct"
bash sh/eval.sh $PROMPT_TYPE $MODEL_NAME_OR_PATH
# Qwen2-Math-72B-Instruct
export CUDA_VISIBLE_DEVICES="0,1,2,3"
MODEL_NAME_OR_PATH="Qwen/Qwen2-Math-72B-Instruct"
bash sh/eval.sh $PROMPT_TYPE $MODEL_NAME_OR_PATH
引用
如果您觉得我们的工作有帮助,欢迎引用。
@article{yang2024qwen2,
title={Qwen2 technical report},
author={Yang, An and Yang, Baosong and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Zhou, Chang and Li, Chengpeng and Li, Chengyuan and Liu, Dayiheng and Huang, Fei and others},
journal={arXiv preprint arXiv:2407.10671},
year={2024}
}












{kind=link}