
 访问官网
访问官网 Github
Github
RLeXplore:加速内在动机强化学习研究
RLeXplore是一个统一、高度模块化和即插即用的工具包,目前提供了八种代表性内在奖励算法的高质量、可靠实现。由于各种混淆因素,包括不同的实现、优化策略和评估方法,比较内在奖励算法一直具有挑战性。因此,RLeXplore旨在为构建、计算和优化内在奖励模块提供统一和标准化的程序。
RLeXplore的工作流程如下图所示:
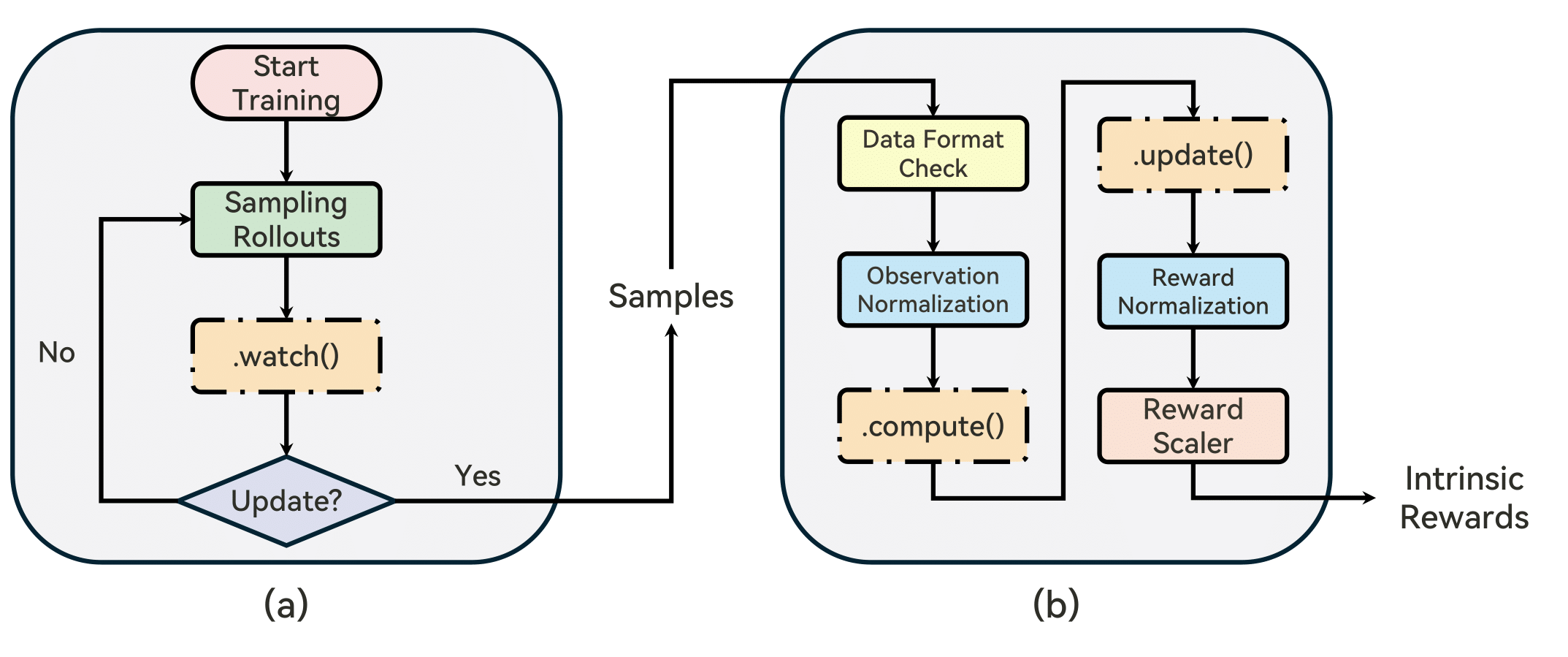
安装
- 使用pip
推荐
打开终端,使用pip安装rllte:
conda create -n rllte python=3.8
pip install rllte-core
- 使用git
打开终端,从GitHub使用git克隆仓库:
git clone https://github.com/RLE-Foundation/rllte.git
pip install -e .
现在你可以通过以下方式调用内在奖励模块:
from rllte.xplore.reward import ICM, RIDE, ...
模块列表
| 类型 | 模块 |
|---|---|
| 基于计数 | PseudoCounts, RND, E3B |
| 好奇心驱动 | ICM, Disagreement, RIDE |
| 基于记忆 | NGU |
| 基于信息理论 | RE3 |
教程
点击以下链接获取代码笔记本:
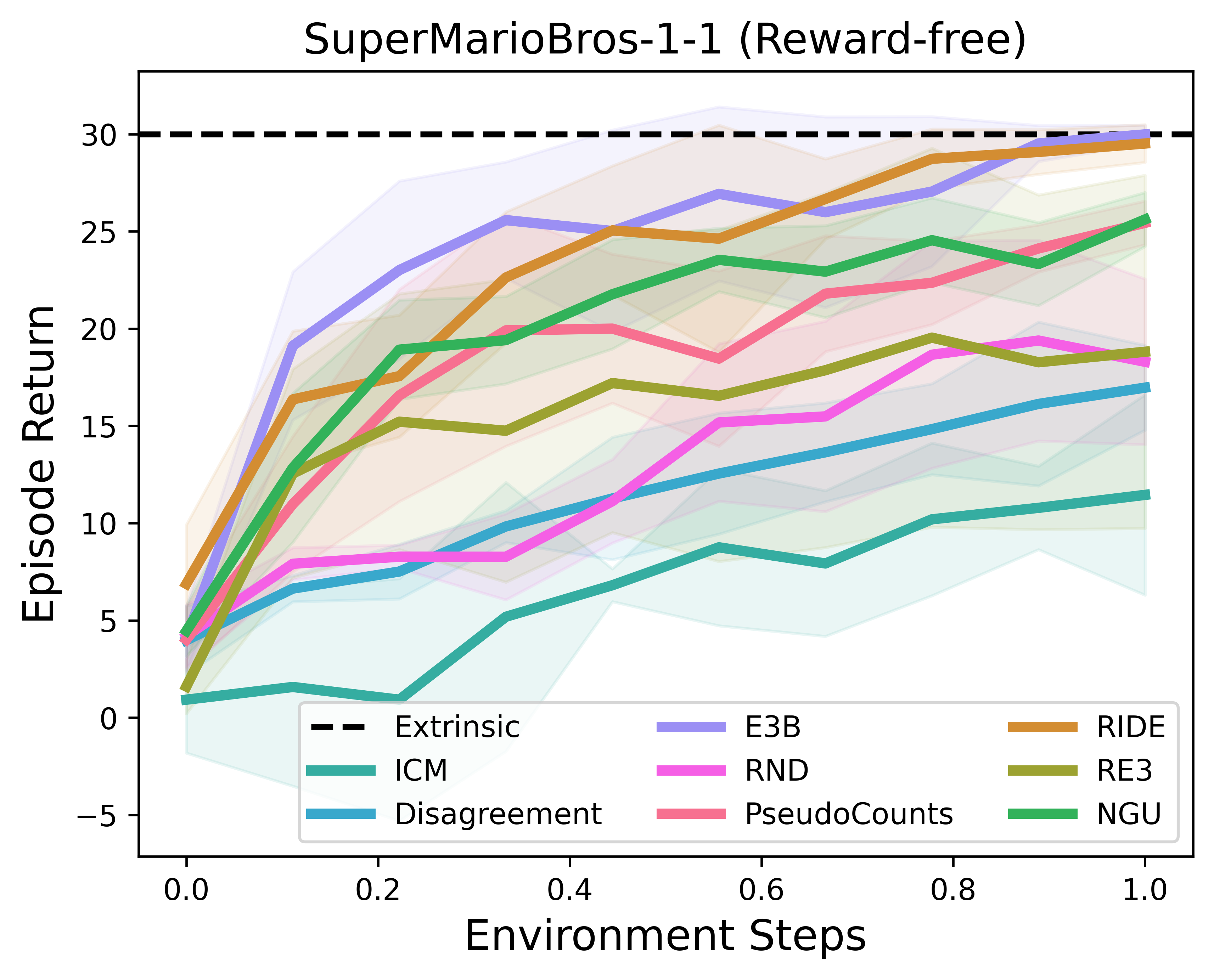
基准测试结果
RLLTE的PPO+RLeXplore在超级马里奥兄弟上的表现:
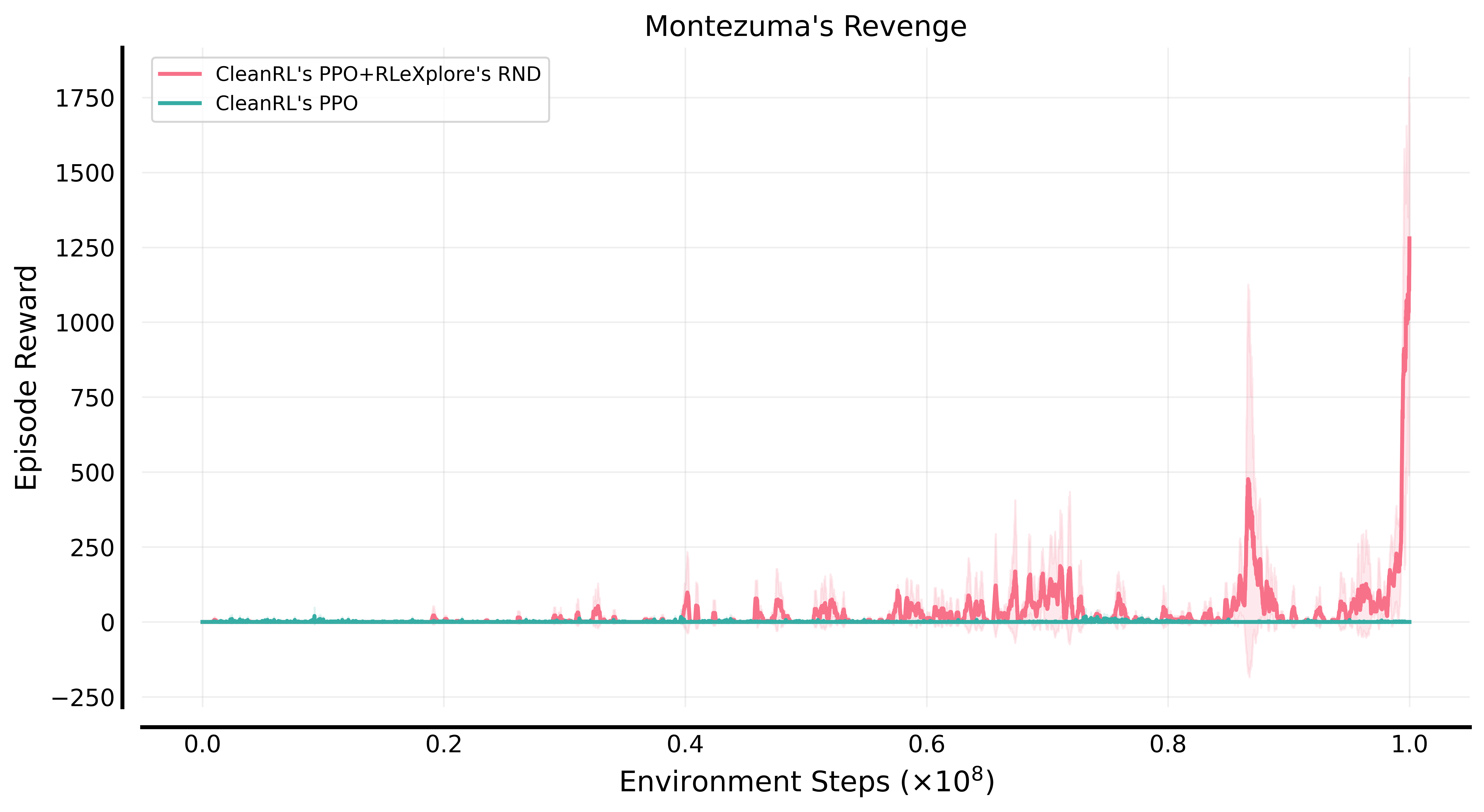
CleanRL的PPO+RLeXplore的RND在蒙特祖玛的复仇上的表现:
引用我们
在出版物中引用此仓库:
@article{yuan_roger2024rlexplore,
title={RLeXplore: Accelerating Research in Intrinsically-Motivated Reinforcement Learning},
author={Yuan, Mingqi and Castanyer, Roger Creus and Li, Bo and Jin, Xin and Berseth, Glen and Zeng, Wenjun},
journal={arXiv preprint arXiv:2405.19548},
year={2024}
}











