
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档 论文
论文超赞MLSecOps 🛡️🤖




一份精心策划的超赞开源工具、资源和教程清单,专注于MLSecOps(机器学习安全运维)。
目录
开源安全工具
在这一部分,我们可以一起看看现有哪些开源解决方案和概念验证来完成ML保护任务。当然,其中一些可能已不再维护或运行困难。但是,不提及它们将是一个巨大的遗憾。
| 工具 | 描述 |
|---|---|
| ModelScan | 防御机器学习模型序列化攻击 |
| NB Defense | 安全的Jupyter笔记本 |
| Garak | 大型语言模型漏洞扫描器 |
| Adversarial Robustness Toolbox | 机器学习模型对抗攻击防御方法库 |
| MLSploit | 用于对抗性机器学习研究的交互式实验云框架 |
| TensorFlow Privacy | 隐私保护机器学习算法和工具库 |
| Foolbox | 用于创建和评估对抗性攻击和防御的Python工具箱 |
| Advertorch | 对抗性鲁棒性研究的Python工具箱 |
| Artificial Intelligence Threat Matrix | 识别和缓解机器学习系统威胁的框架 |
| Adversarial ML Threat Matrix | 人工智能系统的对抗性威胁景观 |
| CleverHans | 机器学习模型对抗性示例和防御库 |
| AdvBox | 用于在PaddlePaddle、PyTorch、Caffe2、MxNet、Keras、TensorFlow中生成欺骗神经网络的对抗性示例的工具箱 |
| Audit AI | 通用机器学习应用的偏见测试 |
| Deep Pwning | 一个轻量级框架,用于评估机器学习模型对有动机对手的鲁棒性实验 |
| Privacy Meter | 用于审计统计和机器学习算法中数据隐私的开源库 |
| TensorFlow Model Analysis | 用于分析、验证和监控生产中机器学习模型的库 |
| PromptInject | 组装对抗性提示的框架 |
| TextAttack | 用于自然语言处理中对抗性攻击、数据增强和模型训练的Python框架 |
| OpenAttack | 用于文本对抗性攻击的开源包 |
| TextFooler | 针对文本分类和推理的自然语言攻击模型 |
| Flawed Machine Learning Security | "有缺陷的机器学习安全"的实际示例,以及机器学习模型生命周期从训练到打包再到部署的各个阶段的ML安全最佳实践 |
| Adversarial Machine Learning CTF | 这个存储库是一个CTF挑战,展示了大多数(所有?)常见人工神经网络中的安全缺陷。它们容易受到对抗性图像的攻击 |
| Damn Vulnerable LLM Project | 一个为被黑而设计的大型语言模型 |
| Gandalf Lakera | 提示注入CTF游乐场 |
| Vigil | LLM提示注入和安全扫描器 |
| PALLMs (Payloads for Attacking Large Language Models) | 在一个地方收集的各种攻击LLM的有效载荷列表 |
| AI-exploits | MLOps系统的漏洞利用。不仅仅是给予ChatGPT等LLM的输入 |
| Offensive ML Playbook | 攻击性ML手册。机器学习攻击和渗透测试笔记 |
| AnonLLM | 为大型语言模型API匿名化个人身份信息(PII) |
| AI Goat | 易受攻击的LLM CTF挑战 |
| Pyrit | 用于生成式AI的Python风险识别工具 |
| Raze to the Ground: Query-Efficient Adversarial HTML Attacks on Machine-Learning Phishing Webpage Detectors | AISec '23接受的论文"Raze to the Ground: 对机器学习钓鱼网页检测器的查询高效对抗性HTML攻击"的源代码 |
| Giskard | LLM应用的开源测试工具 |
| Safetensors | 将pickle转换为安全的序列化选项 |
| Citadel Lens | 根据行业标准进行模型质量测试 |
| Model-Inversion-Attack-ToolBox | 实现模型反转攻击的框架 |
| NeMo-Guardials | NeMo Guardrails允许开发人员在构建基于LLM的应用程序时轻松添加可编程护栏,位于应用程序代码和LLM之间 |
| AugLy | 生成对抗性攻击的工具 |
| Knockoffnets | 实现窃取模型数据的黑盒攻击的概念验证 |
| Robust Intelligence Continous Validation | 用于持续模型验证以符合标准的工具 |
| VGER | Jupyter攻击框架 |
| AIShield Watchtower | AIShield提供的开源工具,用于研究AI模型和扫描漏洞 |
| PS-fuzz | 扫描LLM漏洞的工具 |
| Mindgard-cli | 通过CLI检查AI安全性 |
| PurpleLLama3 | 使用Meta LLM基准检查LLM安全性 |
| Model transparency | 生成模型签名 |
| ARTkit | 自动化基于提示的生成式AI应用测试和评估 |
| LangBiTe | LLM偏见测试框架 |
| OpenDP | 为OpenDP项目提供动力的差分隐私算法核心库 |
| TF-encrypted | TensorFlow加密 |
商业工具
| 工具 | 描述 |
|---|---|
| Databricks平台,Azure Databricks | 数据湖数据管理和实施工具 |
| Hidden Layer AI检测响应 | 事件检测和响应工具 |
| Guardian | CI/CD中的模型保护 |
数据
| 工具 | 描述 |
|---|---|
| ARX - 数据匿名化工具 | 数据集匿名化工具 |
| Data-Veil | 数据掩码和匿名化工具 |
| 图像匿名化工具 | 图像匿名化 |
| 数据匿名化工具 | 数据匿名化 |
| BMW-匿名化-Api | 该存储库允许您匿名化图像/视频中的敏感信息。该解决方案与我们已发布/将发布的用于对象检测和语义分割的基于深度学习的训练/推理解决方案完全兼容 |
| DeepPrivacy2 | 真实图像匿名化工具箱 |
| PPAP | 使用对抗性保护网络进行潜在空间级图像匿名化 |
机器学习代码安全
- lintML - Nvidia开发的ML安全检查工具
- HiddenLayer: 模型即代码 - 关于ML库中一些向量的研究
- Copycat CNN - 如何生成卷积神经网络副本的概念验证
- 差分隐私库 - 为差分隐私和机器学习设计的库
101资源
这里列出了一些资源,可以帮助您了解AI安全主题。了解存在哪些攻击以及攻击者如何使用它们。
AI安全学习地图
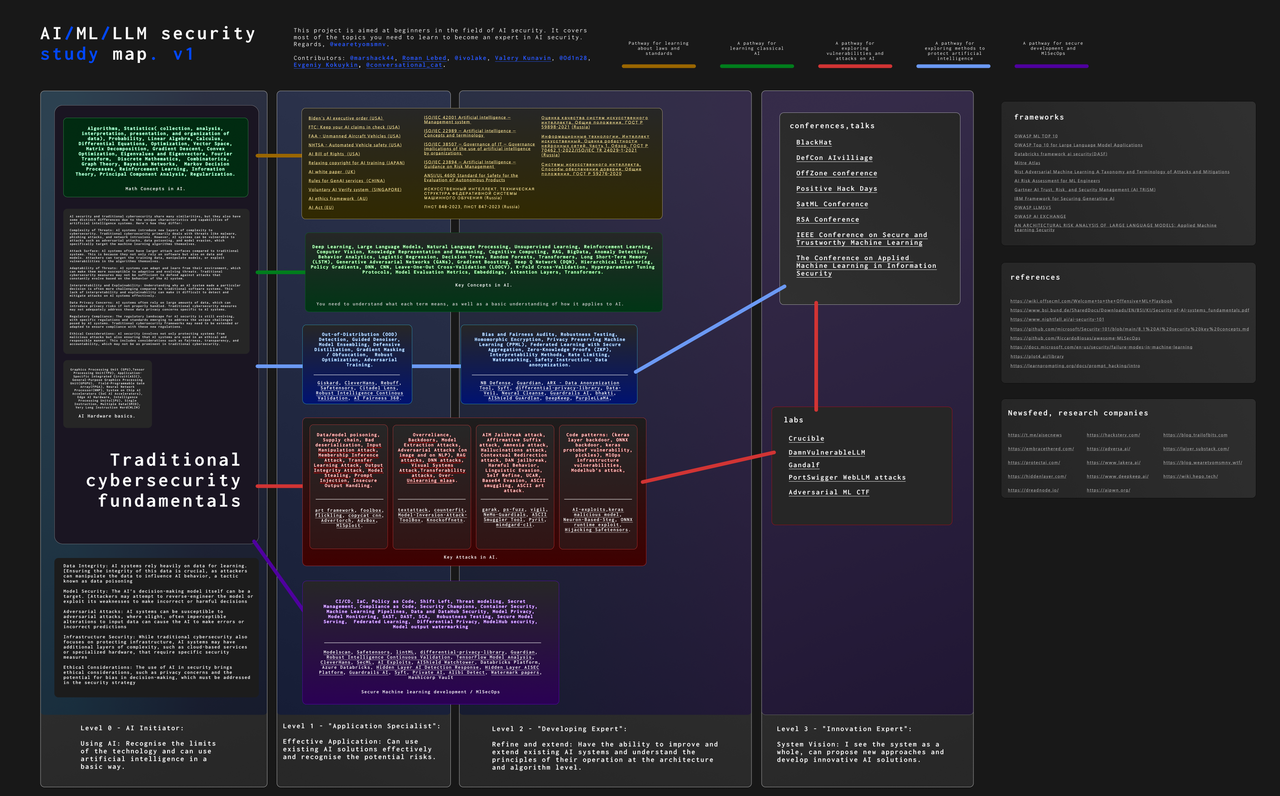
威胁建模
更多内容请参阅《对抗性AI攻击、缓解和防御策略:网络安全专业人士的AI攻击、威胁建模和使用MLSecOps保护AI的指南》
攻击向量
这里我们提供了一个有用的资源列表,重点关注特定的攻击向量。
博客和出版物
🌱 AI安全社区正在成长。新的博客和许多研究人员正在涌现。在这一段落中,您可以看到一些博客的示例。
- 🛡️ 大型语言模型的红队测试
- 🔍 谷歌的人工智能红队
- 🔒 MLSecOps十大漏洞
- 🏴☠️ 通过对抗性提示的令牌走私越狱
- ☣️ 数据投毒究竟有多毒?后门和数据投毒攻击的统一基准
- 📊 我们需要一种新的方法来衡量人工智能安全性
- 🕵️ PrivacyRaven:实现模型反演的概念验证
- 🧠 对抗性提示工程
- 🔫 TextAttack:自然语言处理中对抗性攻击、数据增强和对抗性训练的框架
- 📋 Trail Of Bits对Hugging Face的safetensors库的审计
- 🔝 大型语言模型应用的OWASP十大安全风险
- 🔐 LLM安全
- 🔑 你的MLOps基础设施是否泄露机密?
- 🚩 拥抱红色,展示如何黑客入侵LLM的博客
- 🎙️ 音频劫持:使用生成式人工智能扭曲实时音频交易
- 🌐 HADESS - Web LLM攻击
- 🧰 WTF博客 - MLSecOps框架...有哪些可用,它们之间有什么区别?
- 📚 DreadNode论文栈
MLOps基础设施漏洞
关于MLOps基础设施漏洞的非常有趣的文章。其中一些甚至可以找到现成的漏洞利用。
- 无声破坏 - 关于将Pickle转换为SafeTensors的机器人入侵研究
- 不那么清晰:MLOps解决方案如何模糊你的供应链 - 关于ClearML平台漏洞的研究
- 揭示Azure的无声威胁:云漏洞之旅 - 关于Azure MLAAS安全问题的研究
- MLOps安全格局
- 混淆学习:通过机器学习模型进行供应链攻击
MLSecOps流程
学术扑克脸
仓库
AgentPoison
"AgentPoison:通过记忆或知识库后门投毒对LLM代理进行红队测试"的官方实现。该项目探索了数据投毒和后门插入LLM代理的方法,以评估它们对此类攻击的抵抗力。
DeepPayload
研究将恶意载荷嵌入深度神经网络的方法。
backdoor
调查深度学习模型的后门攻击,重点是在模型中创建不可检测的漏洞。
Stealing_DL_Models
通过各种攻击向量窃取深度学习模型的技术,使对手能够复制或访问模型。
datafree-model-extraction
无需使用数据的模型提取,允许在不访问原始数据的情况下恢复模型。
LLMmap
用于映射和分析大型语言模型(LLMs)的工具,探索各种LLM的结构和行为。
GoogleCloud-Federated-ML-Pipeline
使用Google Cloud基础设施的联邦学习管道,实现分布式数据上的模型训练。
Class_Activation_Mapping_Ensemble_Attack
使用集成类激活图来通过操纵激活图引入模型错误的攻击。
COLD-Attack
在各种条件和约束下攻击深度模型的方法,专注于创建更具弹性的攻击。
pal
针对机器学习模型的自适应攻击研究,能够创建适应模型防御的攻击。
ZeroShotKnowledgeTransfer
零样本场景下的知识转移,探索在没有目标数据先前训练的情况下在模型之间转移知识的方法。
GMI-Attack
生成信息标签的攻击,旨在隐蔽地从训练模型中提取数据。
Knowledge-Enriched-DMI
使用额外知识增强DMI(数据挖掘和集成)方法,以提高准确性和效率。
vmi
研究可视化和解释机器学习模型的方法,提供对模型工作原理的洞察。
Plug-and-Play-Attacks
可以"即插即用"而无需模型修改的攻击,提供灵活和通用的攻击方法。
snap-sp23
用于分析和处理快照数据的工具,实现高效处理数据快照。
privacy-vs-robustness
研究模型中隐私和鲁棒性之间的权衡,旨在平衡机器学习中的这两个方面。
ML-Leaks
从训练模型中数据泄露的方法,探索从机器学习模型中提取私人信息的方式。
BlindMI
关于盲信息提取攻击的研究,实现在不访问模型内部结构的情况下检索数据。
python-DP-DL
用于深度学习的差分隐私方法,确保模型训练过程中的数据隐私。
MMD-mixup-Defense
使用MMD-mixup的防御方法,旨在提高模型抵御攻击的鲁棒性。
MemGuard
保护内存免受攻击的工具,探索防止模型内存数据泄露的方法。
unsplit
用于合并和拆分数据以改进训练的方法,优化模型中异构数据的使用。
face_attribute_attack
针对人脸识别模型的属性攻击,探索通过操纵面部属性来诱导错误的方法。
FVB
针对人脸验证模型的攻击,旨在破坏基于人脸识别的身份验证系统。
Malware-GAN
使用GAN创建恶意软件,探索使用生成模型生成恶意代码的方法。
Generative_Adversarial_Perturbations
使用生成模型生成对抗性扰动的方法,旨在引入深度模型的错误。
Adversarial-Attacks-with-Relativistic-AdvGAN
使用相对论AdvGAN的对抗性攻击,探索创建更真实和有效的攻击方法。
llm-attacks
针对大型语言模型的攻击,探索LLM的漏洞和保护方法。
LLMs-Finetuning-Safety
大型语言模型的安全微调,旨在防止数据泄露并确保LLM调优过程中的安全性。
DecodingTrust
评估模型可信度的方法,探索确定机器学习模型可靠性和安全性的方法。
promptbench
评估提示的基准测试,提供用于测试和优化大型语言模型查询的工具。
rome
基于ROM代码分析和评估模型的工具,探索模型性能和弹性的各个方面。
llmprivacy
关于大型语言模型隐私的研究,旨在保护数据并防止LLM的泄露。
社区资源
- MLSecOps
- MLSecOps播客
- MITRE ATLAS™和Slack社区
- MlSecOps社区和Slack社区
- MITRE ATLAS™(人工智能系统对抗性威胁景观)
- OWASP AI交流
- OWASP机器学习安全十大项目
- OWASP大型语言模型应用十大项目
- OWASP LLMSVS
- OWASP AI安全周期表
- OWASP Slack
- Awesome LLM安全
- Hackstery
- PWNAI
- AiSec_X_Feed
- HUNTR Discord社区
- AIRSK
- AI漏洞数据库
- AI事件数据库
- Defcon AI Village CTF
- Awesome AI安全
- MLSecOps参考资料库
- Awesome LVLM攻击
- Awesome MLLM安全
书籍
信息图表
MLSecOps生命周期
AI安全市场图

贡献
欢迎对此列表做出所有贡献!请随时提交拉取请求,添加或改进任何内容。
贡献者 ✨







仓库统计






活动


支持我们
如果您觉得这个项目有用,请考虑给它一个星标 ⭐️

许可证
本项目采用 MIT 许可证 - 详情请见 LICENSE 文件。

用❤️制作











