
 Github
Github Huggingface
Huggingface 论文
论文Stable Cascade

这是Stable Cascade的官方代码库。我们提供了训练和推理脚本,以及多种可供使用的模型。
该模型基于Würstchen架构构建,其与Stable Diffusion等其他模型的主要区别在于它使用了更小的潜在空间。为什么这很重要?潜在空间越小,推理运行速度就越快,训练成本也就越低。潜在空间有多小?Stable Diffusion使用8倍的压缩因子,将1024x1024的图像编码为128x128。Stable Cascade实现了42倍的压缩因子,这意味着可以将1024x1024的图像编码为24x24,同时保持清晰的重建效果。然后在这个高度压缩的潜在空间中训练文本条件模型。该架构的前几个版本相比Stable Diffusion 1.5实现了16倍的成本降低。
因此,这种模型非常适合效率至关重要的应用场景。此外,所有已知的扩展,如微调、LoRA、ControlNet、IP-Adapter、LCM等,也都可以应用于这种方法。其中一些(微调、ControlNet、LoRA)已经在训练和推理部分提供。
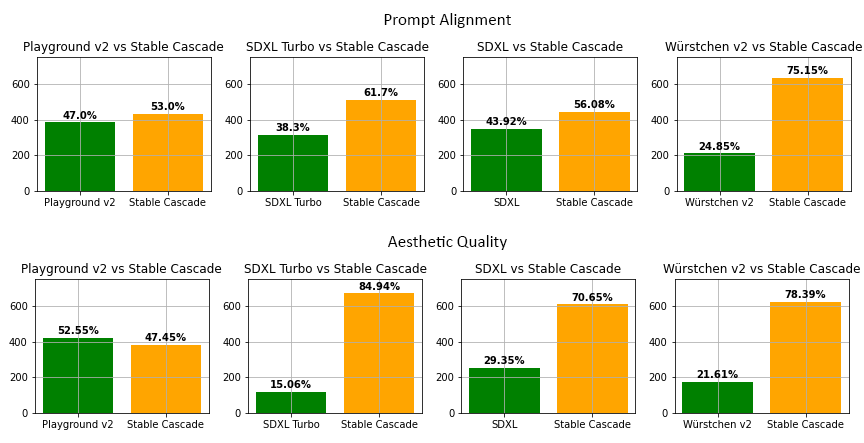
此外,Stable Cascade在视觉效果和评估方面都取得了令人印象深刻的结果。根据我们的评估,Stable Cascade在几乎所有比较中在提示对齐和美学质量方面表现最佳。上图显示了使用parti-prompts(链接)和美学提示混合进行人工评估的结果。具体来说,Stable Cascade(30次推理步骤)与Playground v2(50次推理步骤)、SDXL(50次推理步骤)、SDXL Turbo(1次推理步骤)和Würstchen v2(30次推理步骤)进行了比较。
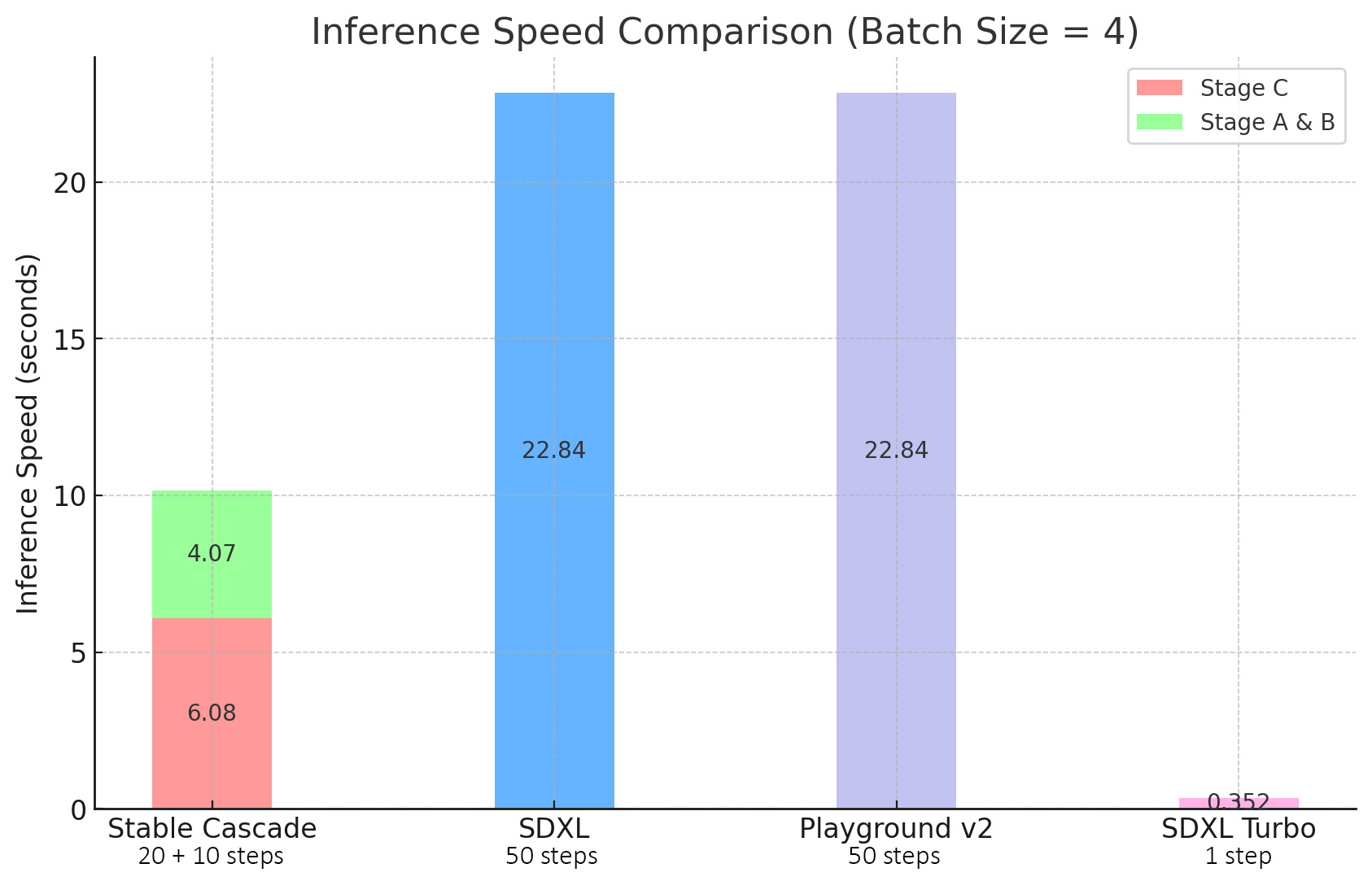
Stable Cascade对效率的关注通过其架构和更高压缩的潜在空间得到体现。尽管最大的模型比Stable Diffusion XL多出14亿参数,但它仍然具有更快的推理时间,如下图所示。

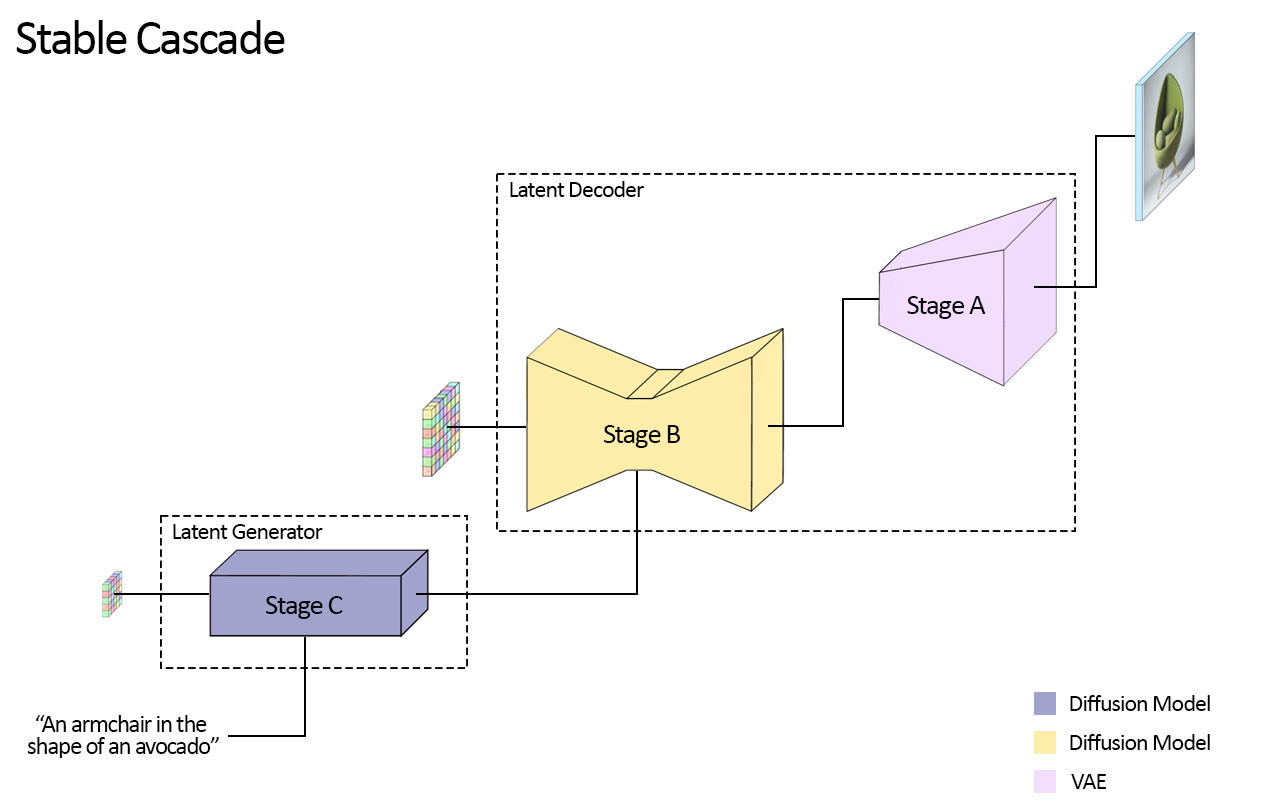
模型概述
Stable Cascade由三个模型组成:Stage A、Stage B和Stage C,代表生成图像的级联,因此命名为"Stable Cascade"。 Stage A和B用于压缩图像,类似于Stable Diffusion中VAE的工作。然而,如前所述,通过这种设置可以实现更高的图像压缩。此外,Stage C负责根据文本提示生成24 x 24的小型潜在表示。下图直观地展示了这一过程。 请注意,Stage A是一个VAE,而Stage B和C都是扩散模型。
在本次发布中,我们为Stage C提供了两个检查点,为Stage B提供了两个,为Stage A提供了一个。Stage C有10亿和36亿参数的版本,但我们强烈推荐使用36亿参数的版本,因为大部分工作都集中在对它的微调上。Stage B的两个版本分别有7亿和15亿参数。两者都能达到很好的效果,但15亿参数的版本在重建小型和精细细节方面表现出色。因此,如果使用每个阶段的较大版本,您将获得最佳效果。最后,Stage A包含2000万参数,由于其规模较小而保持固定。
入门指南
本节将简要概述如何开始使用Stable Cascade。
推理
可以通过推理部分提供的笔记本运行模型。您将找到有关下载模型、计算要求以及如何使用模型的一些教程的更多详细信息。具体来说,提供了四个笔记本,用于以下用例:
文本生成图像
一个简洁的笔记本,为您提供文本生成图像、图像变体和图像到图像的基本功能。
- 文本生成图像
电影般的照片,一只拟人化的企鹅坐在咖啡馆里,一边看书一边喝咖啡。

- 图像变体
该模型还可以理解图像嵌入,这使得生成给定图像(左)的变体成为可能。这里没有给出任何提示。

- 图像到图像
这个功能的工作方式与通常一样,通过将图像噪化到特定程度,然后让模型从该起点生成。这里左侧图像被噪化到80%,标题是:一个人骑着啮齿动物。

此外,该模型也可以在diffusers 🤗库中使用。您可以在这里找到文档和使用方法。
ControlNet
这个笔记本展示了如何使用我们训练的ControlNets,或如何使用您自己为Stable Cascade训练的ControlNet。在此版本中,我们提供以下ControlNets:
- 局部修复 / 外部修复

- 人脸身份识别

注意:人脸身份识别ControlNet将在稍后发布。
- Canny边缘检测

- 超分辨率

这些功能都可以通过同一个笔记本使用,只需为每个ControlNet更改配置即可。更多信息请参见推理指南。
LoRA
我们还提供了自己实现的Stable Cascade LoRA训练和使用方法,可用于微调文本条件模型(Stage C)。具体来说,您可以添加和学习新的词元,并为模型添加LoRA层。这个笔记本展示了如何使用训练好的LoRA。 例如,用以下类型的训练图像对我的狗进行LoRA训练:

让我能够根据以下提示生成我的狗的图像:
电影风格照片,一只名叫[fernando]的狗穿着宇航服。

图像重建
最后,对于那些想从头开始训练自己的文本条件模型的人来说,特别是如果你想使用与我们的Stage C完全不同的架构,Stable Cascade使用的(扩散)自编码器可能会非常有趣,它能够在高度压缩的空间中工作。就像人们使用Stable Diffusion的VAE来训练自己的模型(例如Dalle3)一样,你可以以同样的方式使用Stage A和B,同时受益于更高的压缩率,让你能更快地训练和运行模型。
这个笔记本展示了如何编码和解码图像,以及你能获得的具体好处。
例如,假设你有一批维度为4 x 3 x 1024 x 1024的图像:

你可以将这些图像编码为4 x 16 x 24 x 24的压缩尺寸,得到1024 / 24 = 42.67的空间压缩因子。之后,你可以使用Stage A和B将图像解码回4 x 3 x 1024 x 1024,得到以下输出:

如你所见,重建的效果出奇地接近,即使是小细节也能保留。标准VAE等方法无法实现这样的重建效果。笔记本提供了更多信息和易用的代码供你尝试。
训练
我们提供了从头开始训练Stable Cascade、微调、ControlNet和LoRA的代码。你可以在训练文件夹中找到详细的说明。
备注
这个代码库仍处于早期开发阶段。你可能会遇到意外错误或未经完全优化的训练和推理代码。我们对此提前表示歉意。如果有兴趣,我们将继续发布更新,旨在引入最新的改进和优化。此外,我们非常乐意接受想要贡献的人提出的想法、反馈,甚至是更新。谢谢。
Gradio应用
首先通过运行以下命令安装gradio和diffusers:
pip3 install gradio
pip3 install accelerate # 可选
pip3 install git+https://github.com/kashif/diffusers.git@wuerstchen-v3
然后从项目根目录运行此命令:
PYTHONPATH=./ python3 gradio_app/app.py
引用
@misc{pernias2023wuerstchen,
title={Wuerstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models},
author={Pablo Pernias and Dominic Rampas and Mats L. Richter and Christopher J. Pal and Marc Aubreville},
year={2023},
eprint={2306.00637},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
许可证
本仓库的所有代码均采用MIT许可证
模型权重(可按照这些说明从Huggingface获取)采用STABILITY AI非商业研究社区许可证











