
 Github
Github 论文
论文RepViT-SAM:迈向实时分割任何物体
RepViT:从ViT视角重新审视移动CNN
RepViT-SAM和RepViT的官方PyTorch实现。CVPR 2024。
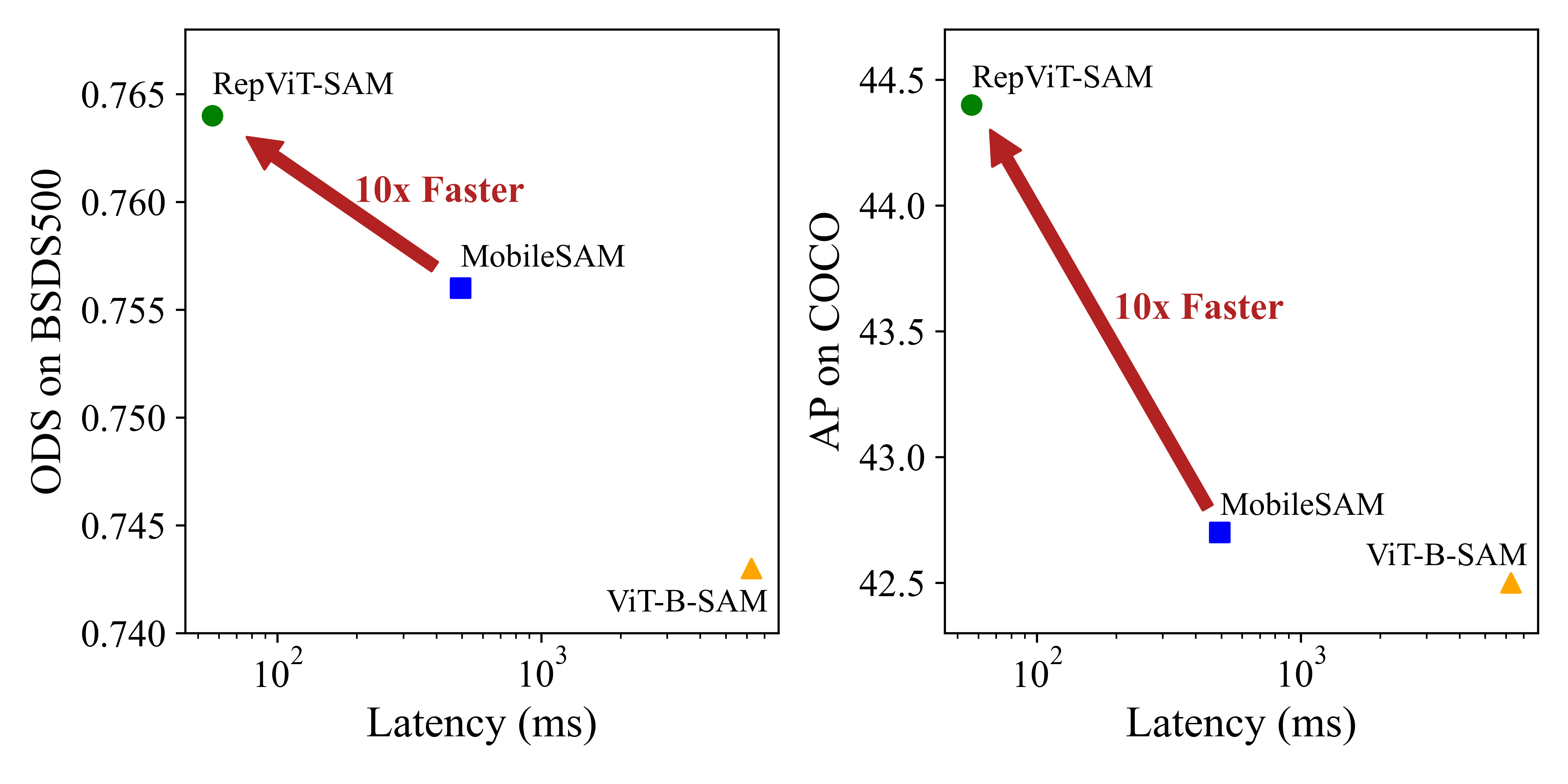
模型部署在iPhone 12上,使用Core ML Tools测量延迟。
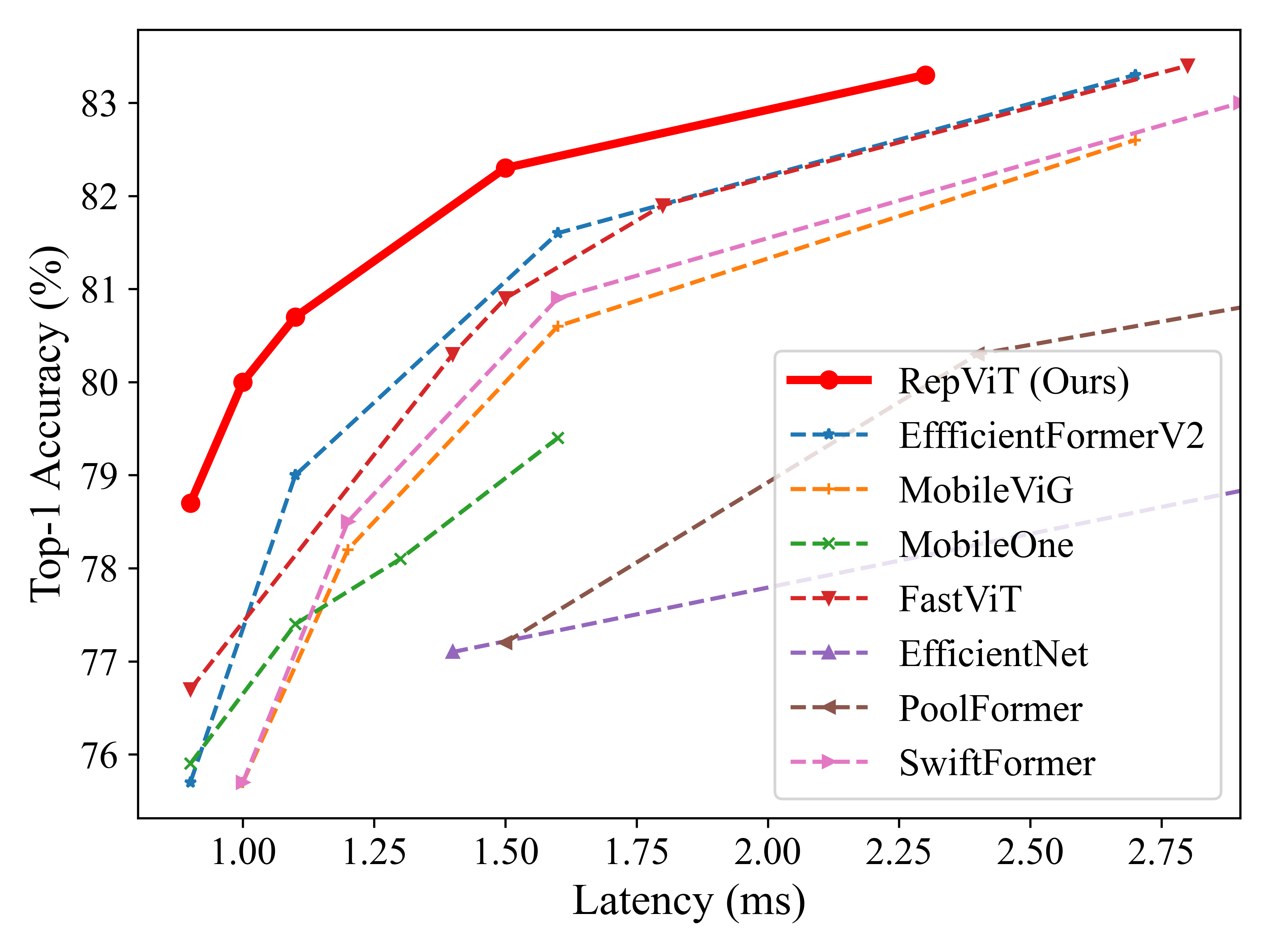
模型在ImageNet-1K上训练,并部署在iPhone 12上,使用Core ML Tools测量延迟。
RepViT-SAM:迈向实时分割任何物体。
Ao Wang, Hui Chen, Zijia Lin, Jungong Han, 和 Guiguang Ding
[arXiv] [项目主页]
摘要
分割任何物体模型(SAM)最近在各种计算机视觉任务的零样本迁移性能上表现出色。然而,其高昂的计算成本仍然让实际应用望而却步。MobileSAM提出通过蒸馏方法用TinyViT替换SAM中的重型图像编码器,显著降低了计算需求。但由于自注意力机制造成的大量内存和计算开销,其在资源受限的移动设备上的部署仍面临挑战。最近,RepViT通过将ViT的高效架构设计融入CNN中,在移动设备上实现了性能和延迟的最佳平衡。在此基础上,为了在移动设备上实现实时分割任何物体,我们用RepViT模型替换SAM中的重型图像编码器,得到了RepViT-SAM模型。大量实验表明,RepViT-SAM比MobileSAM具有显著更好的零样本迁移能力,同时推理速度提高了近10倍。RepViT:从ViT视角重新审视移动CNN。
Ao Wang, Hui Chen, Zijia Lin, Jungong Han, 和 Guiguang Ding
[arXiv]
摘要
近期,轻量级Vision Transformer(ViT)在资源受限的移动设备上展示出比轻量级卷积神经网络(CNN)更优越的性能和更低的延迟。这种改进通常归因于多头自注意力模块,使模型能够学习全局表示。然而,轻量级ViT和轻量级CNN之间的架构差异尚未得到充分研究。在本研究中,我们重新审视了轻量级CNN的高效设计,并强调了它们在移动设备上的潜力。我们通过整合轻量级ViT的高效架构选择,逐步增强标准轻量级CNN(特别是MobileNetV3)的移动友好性。最终得到了一个新的纯轻量级CNN家族,即RepViT。大量实验表明,RepViT在各种视觉任务中优于现有最先进的轻量级ViT,并展现出有利的延迟。在ImageNet上,RepViT在iPhone 12上实现了超过80%的top-1准确率,延迟仅为1毫秒,据我们所知,这是轻量级模型首次达到这一水平。我们最大的模型RepViT-M2.3在仅2.3毫秒延迟的情况下获得了83.7%的准确率。更新 🔥
- 2023/12/17:Grounding-SAM支持RepViT-SAM,请参见Grounded-RepViT-SAM。感谢!
- 2023/12/11:RepViT-SAM已发布。请参阅RepViT-SAM。
- 2023/12/11:RepViT-M0.6已发布,在约0.6毫秒延迟下达到74.1%准确率。其检查点在这里
- 2023/09/28:RepViT-M0.9/1.0/1.1/1.5/2.3模型已发布。
- 2023/07/27:RepViT模型已集成到timm中。请查看https://github.com/huggingface/pytorch-image-models/pull/1876。
ImageNet-1K分类
模型
| 模型 | Top-1 (300轮 / 450轮) | 参数量 | MACs | 延迟 | 检查点 | Core ML | 日志 |
|---|---|---|---|---|---|---|---|
| M0.9 | 78.7 / 79.1 | 5.1M | 0.8G | 0.9ms | 300轮 / 450轮 | 300轮 / 450轮 | 300轮 / 450轮 |
| M1.0 | 80.0 / 80.3 | 6.8M | 1.1G | 1.0ms | 300轮 / 450轮 | 300轮 / 450轮 | 300轮 / 450轮 |
| M1.1 | 80.7 / 81.2 | 8.2M | 1.3G | 1.1ms | 300轮 / 450轮 | 300轮 / 450轮 | 300轮 / 450轮 |
| M1.5 | 82.3 / 82.5 | 14.0M | 2.3G | 1.5ms | 300轮 / 450轮 | 300轮 / 450轮 | 300轮 / 450轮 |
| M2.3 | 83.3 / 83.7 | 22.9M | 4.5G | 2.3ms | 300轮 / 450轮 | 300轮 / 450轮 | 300轮 / 450轮 |
提示:将训练时的RepViT转换为推理时的结构
from timm.models import create_model
import utils
model = create_model('repvit_m0_9')
utils.replace_batchnorm(model)
延迟测量
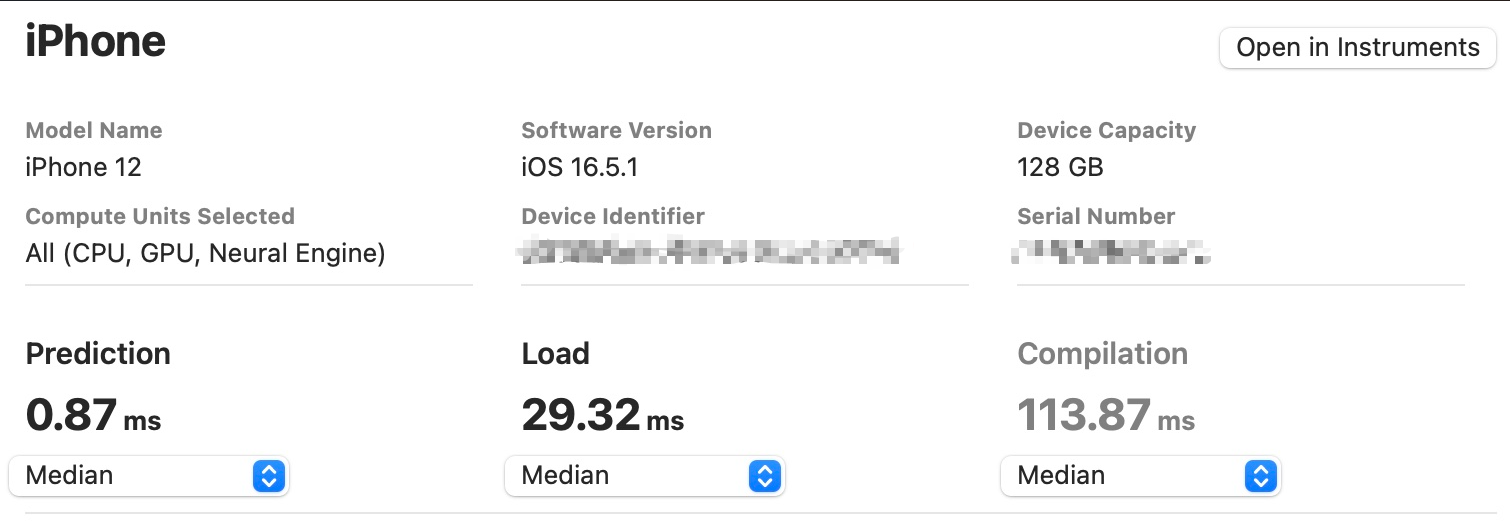
RepViT在iPhone 12 (iOS 16)上报告的延迟使用了来自XCode 14的基准测试工具。 例如,这是RepViT-M0.9的延迟测量:
提示:将模型导出为Core ML模型
python export_coreml.py --model repvit_m0_9 --ckpt pretrain/repvit_m0_9_distill_300e.pth
提示:测量GPU上的吞吐量
python speed_gpu.py --model repvit_m0_9
ImageNet
准备工作
推荐使用conda虚拟环境。
conda create -n repvit python=3.8
pip install -r requirements.txt
数据准备
从http://image-net.org/下载并解压ImageNet训练和验证图像。训练和验证数据分别应位于`train`文件夹和`val`文件夹中:
|-- /path/to/imagenet/
|-- train
|-- val
训练
在8个GPU的机器上训练RepViT-M0.9:
python -m torch.distributed.launch --nproc_per_node=8 --master_port 12346 --use_env main.py --model repvit_m0_9 --data-path ~/imagenet --dist-eval
提示:请指定您的数据路径和模型名称!
测试
例如,测试RepViT-M0.9:
python main.py --eval --model repvit_m0_9 --resume pretrain/repvit_m0_9_distill_300e.pth --data-path ~/imagenet
下游任务
致谢
分类(ImageNet)代码库部分基于LeViT、PoolFormer和EfficientFormer构建。
检测和分割流程来自MMCV(MMDetection和MMSegmentation)。
感谢这些出色的实现!
引用
如果我们的代码或模型对您的工作有帮助,请引用我们的论文:
@inproceedings{wang2024repvit,
title={Repvit: Revisiting mobile cnn from vit perspective},
author={Wang, Ao and Chen, Hui and Lin, Zijia and Han, Jungong and Ding, Guiguang},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={15909--15920},
year={2024}
}
@misc{wang2023repvitsam,
title={RepViT-SAM: Towards Real-Time Segmenting Anything},
author={Ao Wang and Hui Chen and Zijia Lin and Jungong Han and Guiguang Ding},
year={2023},
eprint={2312.05760},
archivePrefix={arXiv},
primaryClass={cs.CV}
}











