
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文Mix-of-Show
🚩🚩🚩: 社区版主分支已发布(持续更新中)。
Mix-of-Show的官方代码。此分支用于应用,包括简化的代码、内存/速度优化和性能改进。研究用途请参考原始研究分支(论文结果、评估和比较方法)。
[NeurIPS 2023]- Mix-of-Show: 扩散模型多概念定制化的去中心化低秩适应
顾宇超、王鑫涛、吴张杰、石云君、陈云鹏、范子涵、肖武游、赵睿、常树宁、吴伟佳、葛一晓、单瑛、Mike Zheng Shou

📋 结果
单概念结果
与LoRA的区别:
-
在ED-LoRA中,嵌入(LoRA权重=0)已经编码了稳定的身份(以哈利波特为例):
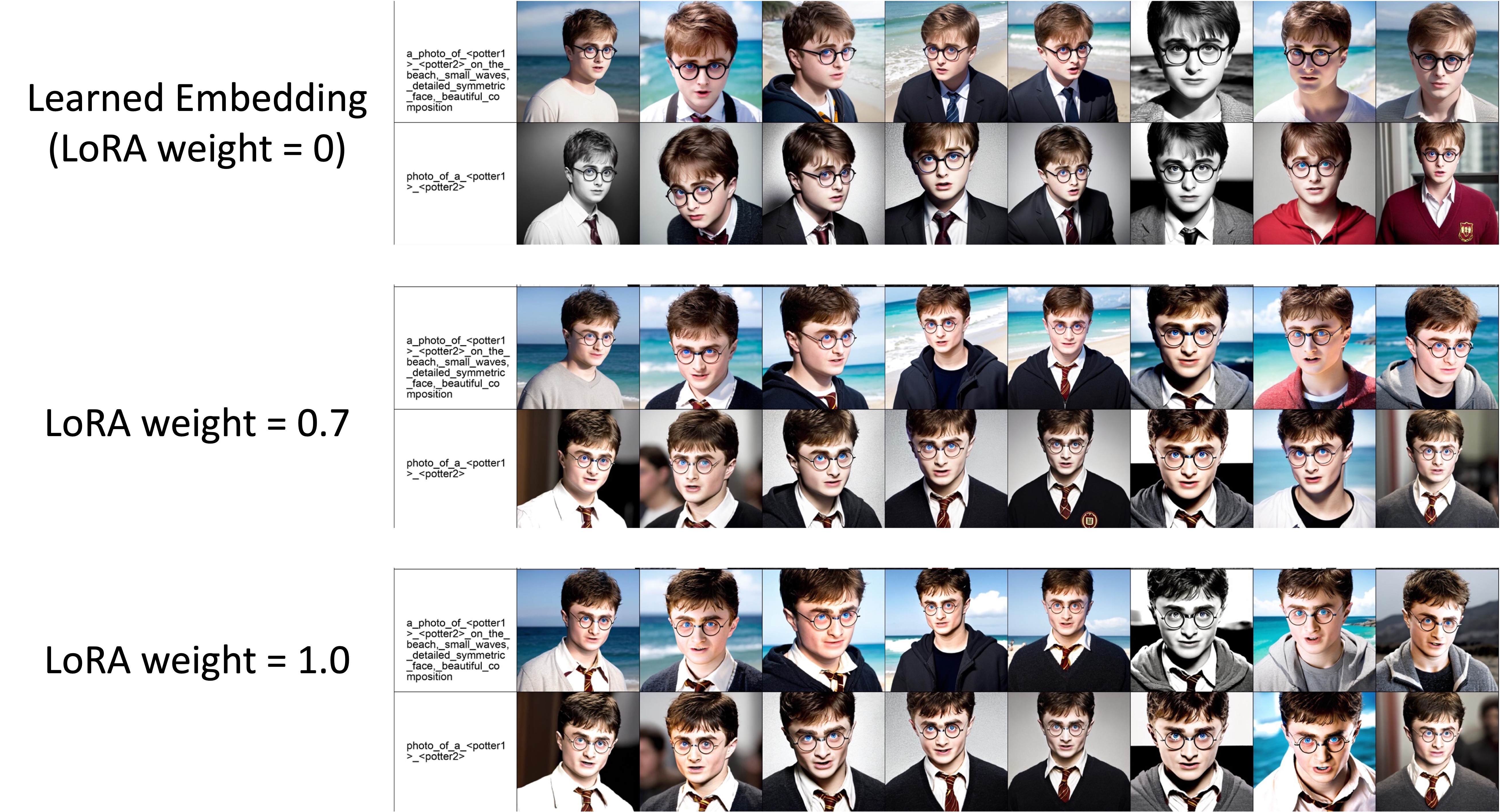
-
基于ED-LoRA,我们可以支持多概念融合而不会丢失太多身份。
多概念结果
概念列表:

动漫角色:

真实角色:


将Mix-of-Show与Stable Diffusion Video结合用于动画制作:
https://github.com/TencentARC/Mix-of-Show/assets/31696690/5a677e99-2c86-41dc-a9da-ba92b3155717
🚩 更新/待办事项
- 支持StableDiffusion XL。
- Colab演示。
- 2023年10月8日。添加注意力正则化和质量改进。
- 2023年10月3日。发布社区版主分支。
- 2023年6月12日。发布研究代码。请切换到研究分支。
:wrench: 依赖项和安装
⏬ 预训练模型和数据准备
预训练模型准备
我们采用ChilloutMix用于真实世界概念,Anything-v4用于动漫概念。
git clone https://github.com/TencentARC/Mix-of-Show.git
cd experiments/pretrained_models
# Diffusers版本的ChilloutMix
git-lfs clone https://huggingface.co/windwhinny/chilloutmix.git
# Diffusers版本的Anything-v4
git-lfs clone https://huggingface.co/andite/anything-v4.0.git
数据准备
注意:数据选择和标注在单概念调优中很重要。我们强烈建议查看sd-scripts中的数据处理。在我们的ED-LoRA中,我们不需要任何正则化数据集。 详细的数据集准备步骤可以参考Dataset.md。我们在本仓库中使用的预处理数据可在Google Drive上获取。
:computer: 单客户端概念调优
步骤1:修改配置
在调优之前,必须在相应的配置文件中指定数据路径并调整某些超参数。以下是一些需要修改的基本配置设置。
datasets:
train:
# 概念数据配置
concept_list: datasets/data_cfgs/edlora/single-concept/characters/anime/hina_amano.json
replace_mapping:
<TOK>: <hina1> <hina2> # 概念新标记
val_vis:
# 调优过程中用于可视化的验证提示
prompts: datasets/validation_prompts/single-concept/characters/test_girl.txt
replace_mapping:
<TOK>: <hina1> <hina2> # 概念新标记
models:
enable_edlora: true # true表示ED-LoRA,false表示普通LoRA
new_concept_token: <hina1>+<hina2> # 概念新标记,使用"+"连接
initializer_token: <rand-0.013>+girl
# 初始化标记,只需根据给定概念的语义类别修改后面的部分
val:
val_during_save: true # 保存检查点时,可视化样本结果。
compose_visualize: true # 将所有样本组合成一个大网格图进行可视化
步骤2:开始调优
我们使用2个A100 GPU调优每个概念。与LoRA类似,社区用户可以启用梯度累积、xformer、梯度检查点,以在单个GPU上进行调优。
accelerate launch train_edlora.py -opt options/train/EDLoRA/real/8101_EDLoRA_potter_Cmix_B4_Repeat500.yml
步骤3:采样
从Google Drive下载我们训练好的模型。
直接采样图像:
import torch
from diffusers import DPMSolverMultistepScheduler
from mixofshow.pipelines.pipeline_edlora import EDLoRAPipeline, StableDiffusionPipeline
from mixofshow.utils.convert_edlora_to_diffusers import convert_edlora
pretrained_model_path = 'experiments/pretrained_models/chilloutmix'
lora_model_path = 'experiments/2002_EDLoRA_hermione_Cmix_B4_Iter1K/models/checkpoint-latest/edlora.pth'
enable_edlora = True # True表示edlora,False表示lora
pipeclass = EDLoRAPipeline if enable_edlora else StableDiffusionPipeline
pipe = pipeclass.from_pretrained(pretrained_model_path, scheduler=DPMSolverMultistepScheduler.from_pretrained(pretrained_model_path, subfolder='scheduler'), torch_dtype=torch.float16).to('cuda')
pipe, new_concept_cfg = convert_edlora(pipe, torch.load(lora_model_path), enable_edlora=enable_edlora, alpha=0.7)
pipe.set_new_concept_cfg(new_concept_cfg)
TOK = '<hermione1> <hermione2>' # TOK是训练lora/edlora时的概念名称
prompt = f'a {TOK} in front of eiffel tower, 4K, high quality, high resolution'
negative_prompt = 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality'
image = pipe(prompt, negative_prompt=negative_prompt, height=768, width=512, num_inference_steps=50, guidance_scale=7.5).images[0]
image.save('res.jpg')
或者为全面可视化采样图像网格:在测试配置中指定模型路径,然后运行以下命令。
python test_edlora.py -opt options/test/EDLoRA/human/8101_EDLoRA_potter_Cmix_B4_Repeat500.yml
:computer: 中心节点概念融合
步骤1: 收集概念模型
收集所有您想要扩展预训练模型的概念模型,并相应地修改 datasets/data_cfgs/MixofShow/multi-concept/real/* 中的配置。
[
{
"lora_path": "experiments/EDLoRA_Models/Base_Chilloutmix/characters/edlora_potter.pth", # ED-LoRA 路径
"unet_alpha": 1.0, # 通常使用完整身份 = 1.0
"text_encoder_alpha": 1.0, # 通常使用完整身份 = 1.0
"concept_name": "<potter1> <potter2>" # 新概念标记
},
{
"lora_path": "experiments/EDLoRA_Models/Base_Chilloutmix/characters/edlora_hermione.pth",
"unet_alpha": 1.0,
"text_encoder_alpha": 1.0,
"concept_name": "<hermione1> <hermione2>"
},
... # 继续添加新概念以扩展预训练模型
]
步骤2: 梯度融合
bash fuse.sh
步骤3: 采样
从谷歌云盘下载我们的融合模型。
从融合模型进行单概念采样:
import json
import os
import torch
from diffusers import DPMSolverMultistepScheduler
from mixofshow.pipelines.pipeline_edlora import EDLoRAPipeline
预训练模型路径 = 'experiments/composed_edlora/chilloutmix/potter+hermione+thanos_chilloutmix/combined_model_base'
启用_edlora = True # True 表示启用 edlora,False 表示启用 lora
pipe = EDLoRAPipeline.from_pretrained(预训练模型路径, scheduler=DPMSolverMultistepScheduler.from_pretrained(预训练模型路径, subfolder='scheduler'), torch_dtype=torch.float16).to('cuda')
with open(f'{预训练模型路径}/new_concept_cfg.json', 'r') as fr:
新概念配置 = json.load(fr)
pipe.set_new_concept_cfg(新概念配置)
标记 = '<thanos1> <thanos2>' # 标记是训练 lora/edlora 时的概念名称
提示词 = f'一个{标记}站在富士山前'
负面提示词 = '长身体,低分辨率,不良解剖,糟糕的手,缺少手指,额外的手指,较少的手指,裁剪,最差质量,低质量'
图像 = pipe(提示词, negative_prompt=负面提示词, height=1024, width=512, num_inference_steps=50, generator=torch.Generator('cuda').manual_seed(1), guidance_scale=7.5).images[0]
图像.save(f'结果.jpg')
区域可控的多概念采样:
bash regionally_sample.sh
📜 许可证和致谢
本项目基于Apache 2.0 许可证发布。
此代码库基于diffusers构建。感谢他们的开源贡献!此外,我们还要感谢以下令人惊叹的开源项目:
-
LoRA for Diffusion Models (https://github.com/cloneofsimo/lora, https://github.com/kohya-ss/sd-scripts)。
-
Custom Diffusion (https://github.com/adobe-research/custom-diffusion)。
-
T2I-Adapter (https://github.com/TencentARC/T2I-Adapter)。
🌏 引用
@article{gu2023mixofshow,
title={Mix-of-Show: Decentralized Low-Rank Adaptation for Multi-Concept Customization of Diffusion Models},
author={Gu, Yuchao and Wang, Xintao and Wu, Jay Zhangjie and Shi, Yujun and Chen Yunpeng and Fan, Zihan and Xiao, Wuyou and Zhao, Rui and Chang, Shuning and Wu, Weijia and Ge, Yixiao and Shan Ying and Shou, Mike Zheng},
journal={arXiv preprint arXiv:2305.18292},
year={2023}
}
📧 联系方式
如果您有任何问题或改进建议,请发送电子邮件至 Yuchao Gu (yuchaogu9710@gmail.com),或提出一个 issue。











