
 Github
Github Huggingface
Huggingface 论文
论文SEED-Story

我们推出了SEED-Story,这是一个基于SEED-X的多模态大语言模型,能够生成多模态长篇故事,包含丰富连贯的叙事文本和角色及风格一致的图像。 我们还发布了StoryStream,这是一个专门为训练和评估多模态故事生成而设计的大规模数据集。

待办事项
- 发布StoryStream数据集。
- 发布推理代码和模型检查点。
- 发布指令微调的训练代码。
简介
SEED-Story是一个由多模态大语言模型驱动的系统,能够基于用户提供的图像和文本作为故事开头,生成多模态长篇故事。生成的故事包含丰富连贯的叙事文本,以及角色和风格一致的图像。尽管我们在训练时最多使用10个序列,但生成的故事可以延伸至25个多模态序列。

给定相同的初始图像但不同的开场文本,SEED-Story可以生成不同的多模态故事。上面的分支以提及"戴黄帽子的男人"的文本开始,导致生成的图像包含该角色。下面的分支开始时没有提到这个男人,结果生成的故事与第一个故事不同,不包括他。

方法
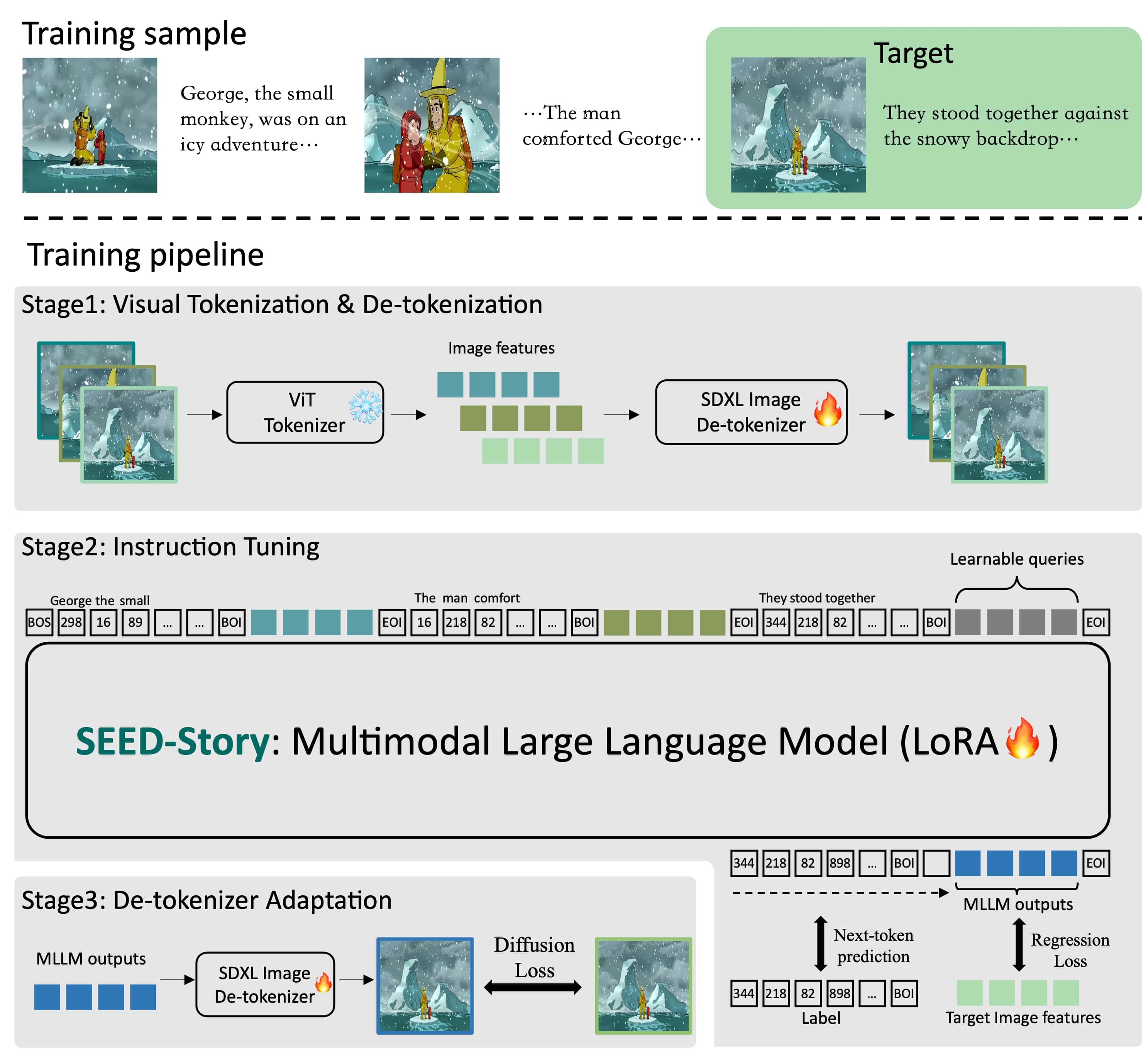
在第一阶段,我们预训练了一个基于SD-XL的解码器,通过输入预训练ViT的特征来重建图像。
在第二阶段,我们采样一个随机长度的交错图像-文本序列,通过执行下一个词预测和可学习查询的输出隐藏状态与目标图像ViT特征之间的图像特征回归来训练多模态大语言模型。
在第三阶段,将多模态大语言模型回归得到的图像特征输入解码器,以微调SD-XL,增强生成图像中角色和风格的一致性。
视频演示

这是SEED-Story的视频演示。点击可跳转到YouTube!在这个演示中,我们使用图像到视频模型来为生成的图像添加动画,并使用AI语音来叙述配套的故事文本。我们由衷感谢Meixi Chen制作了这个演示。
使用方法
依赖
- Python >= 3.8(推荐使用Anaconda)
- PyTorch >=2.0.1(推荐使用torch==2.1.2+cu121)
- NVIDIA GPU + CUDA
安装
克隆仓库并安装依赖包
git clone
cd SEED-Story
pip install -r requirements.txt
数据准备
我们发布了StoryStream数据集,用于训练和测试多模态故事生成。从StoryStream下载图像和故事文本文件。
StoryStream数据集包含3个子集:Curious George、Rabbids Invasion和The Land Before Time。我们以George子集为例。
jsonl文件包含所有数据。每行包含一个由30张图像和相应故事文本组成的故事。"image"组件是30张图像路径的列表。"captions"组件是30个相应故事文本的列表。
为了提高训练效率,您可以像我们一样将故事分成长度为10的块。分块脚本在./StoryStream/chunk_data.py中。
模型权重
我们发布了预训练的编码器、预训练的解码器、预训练的基础模型SEED-X-pretrained、 StoryStream指令微调的多模态大语言模型SEED-Story-George和StoryStream微调的解码器Detokenizer-George,它们都在SEED-Story Hugging Face中。
请下载检查点并将它们保存在./pretrained文件夹下。
您还需要下载stable-diffusion-xl-base-1.0、Llama-2-7b-hf和Qwen-VL-Chat,并将它们保存在./pretrained文件夹下。请使用以下脚本提取Qwen-VL-Chat中视觉编码器的权重。
python3 src/tools/reload_qwen_vit.py
推理
使用SEED-Story进行推理
# 多模态故事生成
python3 src/inference/gen_george.py
# 使用多模态注意力汇聚进行故事可视化
python3 src/inference/vis_george_sink.py
评估
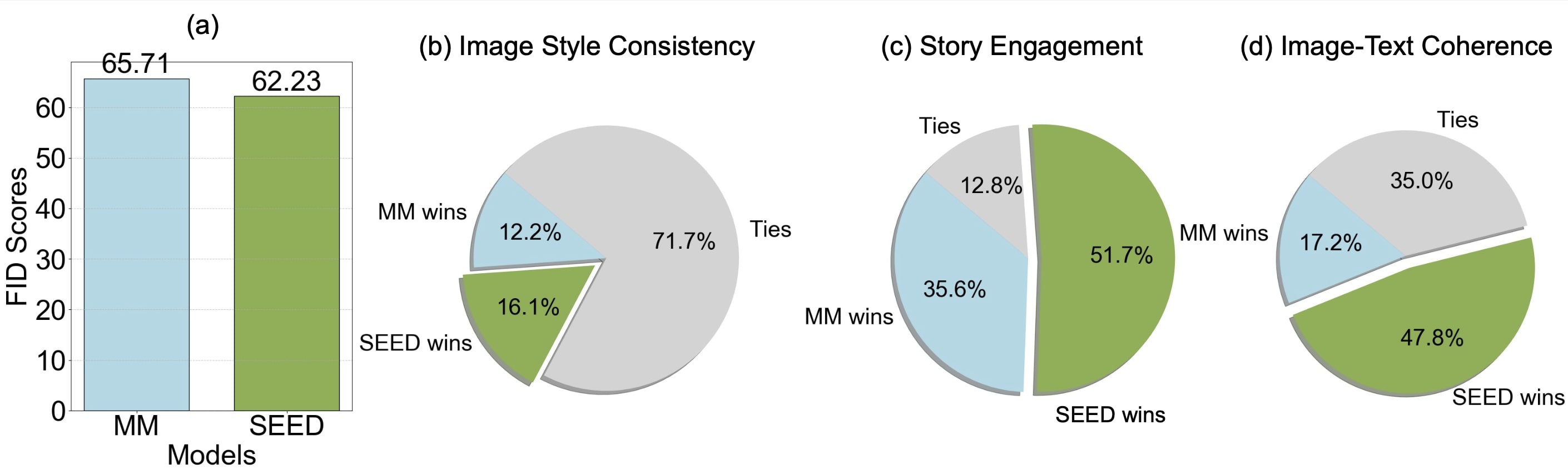
我们使用GPT4 API评估多模态生成结果。脚本位于./src/eval文件夹下。我们通过给定验证集的开头来评估生成结果。评估从3个方面进行:图像风格一致性、故事吸引力和文本-图像一致性。
| 风格 | 吸引力 | 一致性 | |
|---|---|---|---|
| GPT4评估 | 8.61 | 6.27 | 8.24 |
| 比较评估结果如下所示。 |
指令微调
阶段1:视觉分词与反分词
视觉分词与反分词请参考 SEED-X。
阶段2:指令微调
- 准备预训练模型(参见模型权重)。
- 准备指令微调数据。例如,使用"build_long_story_datapipe"数据加载器进行StoryStream时,每个文件夹存储多个jsonl文件,每个jsonl文件最多包含1万条内容,内容示例如下:
{"id": 102, "images": ["000258/000258_keyframe_0-19-49-688.jpg", "000258/000258_keyframe_0-19-52-608.jpg", "000258/000258_keyframe_0-19-54-443.jpg", "000258/000258_keyframe_0-19-56-945.jpg", "000258/000258_keyframe_0-20-0-866.jpg", "000258/000258_keyframe_0-20-2-242.jpg", "000258/000258_keyframe_0-20-4-328.jpg", "000258/000258_keyframe_0-20-10-250.jpg", "000258/000258_keyframe_0-20-16-673.jpg", "000258/000258_keyframe_0-20-19-676.jpg"], "captions": ["从前,在一个充满五彩缤纷建筑的小镇里,一个名叫蒂米的小男孩站在人行道上。他穿着一件浅绿色的T恤,上面印有建筑图案,还戴着配套的手套,看起来对即将到来的一天充满期待。", "不久,蒂米加入了聚集在公园里的一群人。其中有一个戴黄帽子、系绿领带的男子,一位穿粉色裙子、手持包包和喷雾瓶的女士,还有两个穿白衣服、拿着包的孩子。他们都准备好开始今天的活动了。", "蒂米站在那个戴黄帽子的男子旁边,那人还戴着黄手套,衣服上印有城市景观图案。蒂米穿着一件带有回收标志的绿色T恤,手里拿着一个装满可回收物的透明塑料袋和一张纸。他们准备开始他们的城市清洁任务。", "蒂米脸上依然挂着笑容,开始沿着带有银色栏杆的人行道行走,兴奋地准备帮助清洁他心爱的城市,他的热情感染了周围的人。", "这群人聚集在公园里,为清洁活动做准备。戴黄帽子的男子手持剪贴板,附近一个孩子戴着手套,拿着垃圾夹。每个人都迫不及待地想要开始。", "突然,一只棕色的猴子乔治出现了。他站在两个人之间,开心地拿着一个带有城堡图案的蓝色保龄球瓶。乔治总是准备好加入有趣的活动并伸出援手。", "小组成员之一戴着手套,拿着垃圾袋和剪贴板。他们都准备好开始清洁工作,而乔治也急切地想要帮忙。", "当他们开始清洁时,其中一个孩子把一幅画递给了一位成年人。这幅画上是花朵,象征着他们试图在城市中保护的美丽。", "这群人手牵手,提着袋子,沿着人行道走着。他们是一个团队,一起努力使他们的城市变得更干净、更美丽。", "他们走着,经过了一个穿白衣服的幼儿和一个推婴儿车的成年人。城市充满了生机,每个人都在为保持城市清洁尽自己的一份力。"], "orders": [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]}
- 运行指令微调脚本。
bash scripts/sft_storystream.sh
阶段3:反分词器适应
- 使用以下脚本获取"pytorch_model.bin"。
cd train_output/seed_story/checkpoint-xxxx
python3 zero_to_fp32.py . pytorch_model.bin
- 在"configs/clm_models/agent_7b_seed_story.yaml"中将"pretrained_model_path"更改为新的检查点。例如,
pretrained_model_path: train_output/seed_story/checkpoint-6000/pytorch_model.bin
- 运行反分词器适应脚本。
bash scripts/adapt_storystream.sh
引用
如果您觉得这项工作有帮助,请考虑引用:
@article{yang2024seedstory,
title={SEED-Story: Multimodal Long Story Generation with Large Language Model},
author={Shuai Yang and Yuying Ge and Yang Li and Yukang Chen and Yixiao Ge and Ying Shan and Yingcong Chen},
year={2024},
journal={arXiv preprint arXiv:2407.08683},
url={https://arxiv.org/abs/2407.08683},
}
许可证
SEED-Story 在 Apache 许可证 2.0 版下授权,除了 License 中列出的第三方组件。











