
onnx-tool
一个ONNX模型的工具:
- 构建LLM模型和概要
- 解析和编辑:常量折叠;操作融合。
- 模型概要:快速形状推理;MACs统计
- 计算图和形状引擎。
- 模型内存压缩:激活压缩和权重压缩。
- 支持量化模型和稀疏模型。
支持的模型:
- 自然语言处理:BERT, T5, GPT, LLaMa, MPT(TransformerModel)
- 扩散模型:稳定扩散(文本编码器,VAE,UNET)
- 计算机视觉:Detic,BEVFormer,SSD300_VGG16,...
- 音频:sovits,LPCNet
构建LLM模型和概要
在一秒钟内给10个hugging face模型建立概要。保存ONNX模型与llama.cpp一样简单。 代码参考
| 模型名称(1k输入) | MACs(G) | 参数(G) | KV缓存(G) |
|---|---|---|---|
| gpt-j-6b | 6277 | 6.05049 | 0.234881 |
| yi-1.5-34B | 35862 | 34.3889 | 0.125829 |
| microsoft/phi-2 | 2948 | 2.77944 | 0.167772 |
| Phi-3-mini-4k | 4083 | 3.82108 | 0.201327 |
| Phi-3-small-8k-instruct | 7912 | 7.80167 | 0.0671089 |
| Phi-3-medium-4k-instruct | 14665 | 13.9602 | 0.104858 |
| Llama3-8B | 8029 | 8.03026 | 0.0671089 |
| Llama-3.1-70B-Japanese-Instruct-2407 | 72888 | 70.5537 | 0.167772 |
| QWen-7B | 7509 | 7.61562 | 0.0293601 |
| Qwen2_72B_Instruct | 74895 | 72.7062 | 0.167772 |
根据硬件规格获得首次令牌延迟和下次令牌延迟。
| model_type_4bit_kv16bit | 内存大小(GB) | Ultra-155H_first_latency | Ultra-155H_next_latency | Arc-A770_first_latency | Arc-A770_next_latency | H100-PCIe_first_latency | H100-PCIe_next_latency |
|---|---|---|---|---|---|---|---|
| gpt-j-6b | 3.75678 | 1.0947 | 0.041742 | 0.0916882 | 0.00670853 | 0.0164015 | 0.00187839 |
| yi-1.5-34B | 19.3369 | 5.77095 | 0.214854 | 0.45344 | 0.0345302 | 0.0747854 | 0.00966844 |
| microsoft/phi-2 | 1.82485 | 0.58361 | 0.0202761 | 0.0529628 | 0.00325866 | 0.010338 | 0.000912425 |
| Phi-3-mini-4k | 2.49649 | 0.811173 | 0.0277388 | 0.0745356 | 0.00445802 | 0.0147274 | 0.00124825 |
| Phi-3-small-8k-instruct | 4.2913 | 1.38985 | 0.0476811 | 0.117512 | 0.00766303 | 0.0212535 | 0.00214565 |
| Phi-3-medium-4k-instruct | 7.96977 | 2.4463 | 0.088553 | 0.198249 | 0.0142317 | 0.0340576 | 0.00398489 |
| Llama3-8B | 4.35559 | 1.4354 | 0.0483954 | 0.123333 | 0.00777784 | 0.0227182 | 0.00217779 |
| Llama-3.1-70B-Japanese-Instruct-2407 | 39.4303 | 11.3541 | 0.438114 | 0.868475 | 0.0704112 | 0.137901 | 0.0197151 |
| QWen-7B | 4.03576 | 1.34983 | 0.0448417 | 0.11722 | 0.00720671 | 0.0218461 | 0.00201788 |
| Qwen2_72B_Instruct | 40.5309 | 11.6534 | 0.450343 | 0.890816 | 0.0723766 | 0.14132 | 0.0202654 |
基本解析和编辑
您可以通过onnx_tool.Model加载任何onnx文件:
使用onnx_tool.Graph更改图结构;
使用onnx_tool.Node更改操作属性和IO张量;
使用onnx_tool.Tensor更改张量数据或类型。
要应用您的更改,只需调用onnx_tool.Model或onnx_tool.Graph的save_model方法。
形状推理与模型概要
所有概要数据必须基于形状推理结果构建。
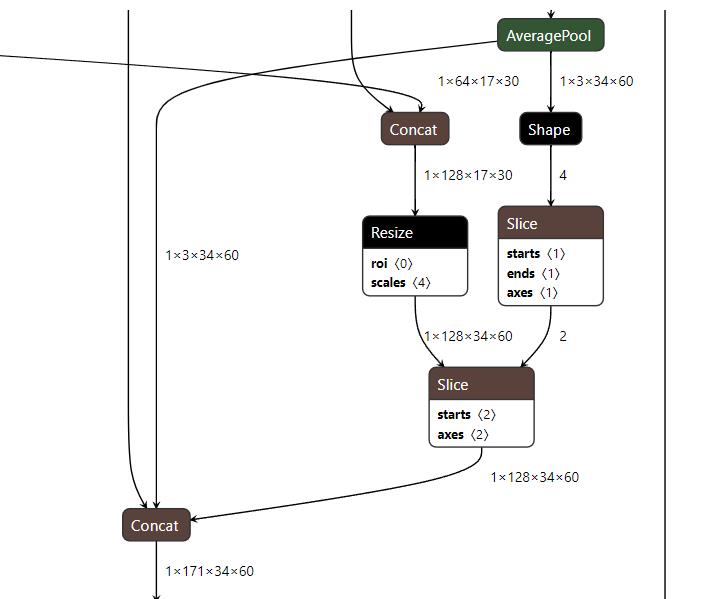
带有张量形状的ONNX图:

稀疏概要表:

介绍: data/Profile.md。
pytorch使用: data/PytorchUsage.md。
tensorflow使用: data/TensorflowUsage.md。
示例: benchmark/examples.py。
计算图与形状引擎
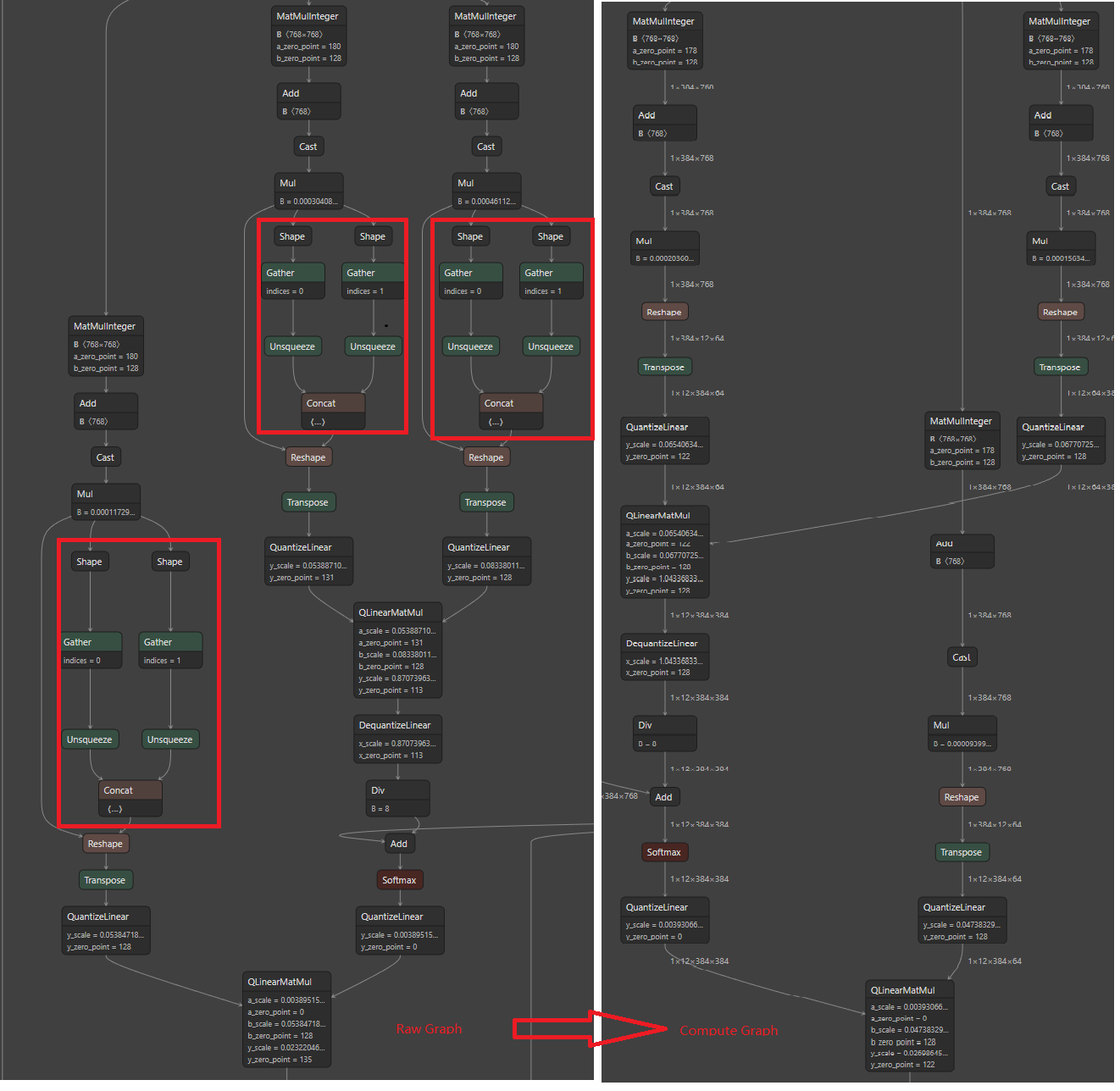
删除由ONNX导出创建的形状计算层以获得计算图。在运行时使用形状引擎更新张量形状。
示例: benchmark/shape_regress.py。
benchmark/examples.py。
将计算图和形状引擎集成到cpp推理引擎中: data/inference_engine.md
内存压缩
激活压缩
激活内存也称为临时内存,是由每个操作输出创建的。只有标记为模型输出的最后一个激活会被保留。因此,您不需要为每个激活张量准备内存空间。它们最好重用优化的内存大小。
对于大型语言模型和高分辨率的计算机视觉模型,激活内存压缩是节省内存的关键。
该压缩方法在大多数模型上实现了5%的内存压缩。
例如:
| 模型 | 本机内存大小(MB) | 压缩后的内存大小(MB) | 压缩比(%) |
|---|---|---|---|
| 稳定扩散(VAE编码器) | 14,245 | 540 | 3.7 |
| 稳定扩散(VAE解码器) | 25,417 | 1,140 | 4.48 |
| 稳定扩散(文本编码器) | 215 | 5 | 2.5 |
| 稳定扩散(UNet) | 36,135 | 2,232 | 6.2 |
| GPT2 | 40 | 2 | 6.9 |
| BERT | 2,170 | 27 | 1.25 |
代码示例: benchmark/compression.py
权重压缩
一个具有 70 亿参数的 fp32 模型将占用 28GB 的磁盘空间和内存空间。如果您的设备没有这么多内存空间,您甚至无法运行该模型。因此,权重压缩对于运行大型语言模型至关重要。作为参考,具有 int4 对称 32 位块量化(llama.cpp 的 q4_0 量化方法)的 70 亿模型,其模型大小与 fp32 模型相比仅为~0.156 倍。
当前支持:
- [fp16]
- [int8]x[对称/不对称]x[每张量/每通道/每块]
- [int4]x[对称/不对称]x[每张量/每通道/每块]
代码示例:benchmark/examples.py。
如何安装
pip install onnx-tool
或者
pip install --upgrade git+https://github.com/ThanatosShinji/onnx-tool.git
python>=3.6
如果通过 onnx 的安装 pip install onnx-tool 失败,您可以首先尝试 pip install onnx==1.8.1(类似于这个较低的版本)。
然后再次 pip install onnx-tool。
已知问题
- 不支持循环操作
- 不支持序列类型
ONNX 模型库 及SOTA 模型的结果
一些模型具有动态输入形状。MACs 随输入形状变化。在这些结果中使用的输入形状写在 data/public/config.py。 带有所有张量形状的 onnx 模型可以下载:百度网盘(代码:p91k)Google 云盘
|
|











