
 Github
Github 论文
论文IP_LAP:基于特征点和外观先验的身份保持说话人脸生成(CVPR 2023)
我们CVPR2023论文"基于特征点和外观先验的身份保持说话人脸生成"的Pytorch官方实现。
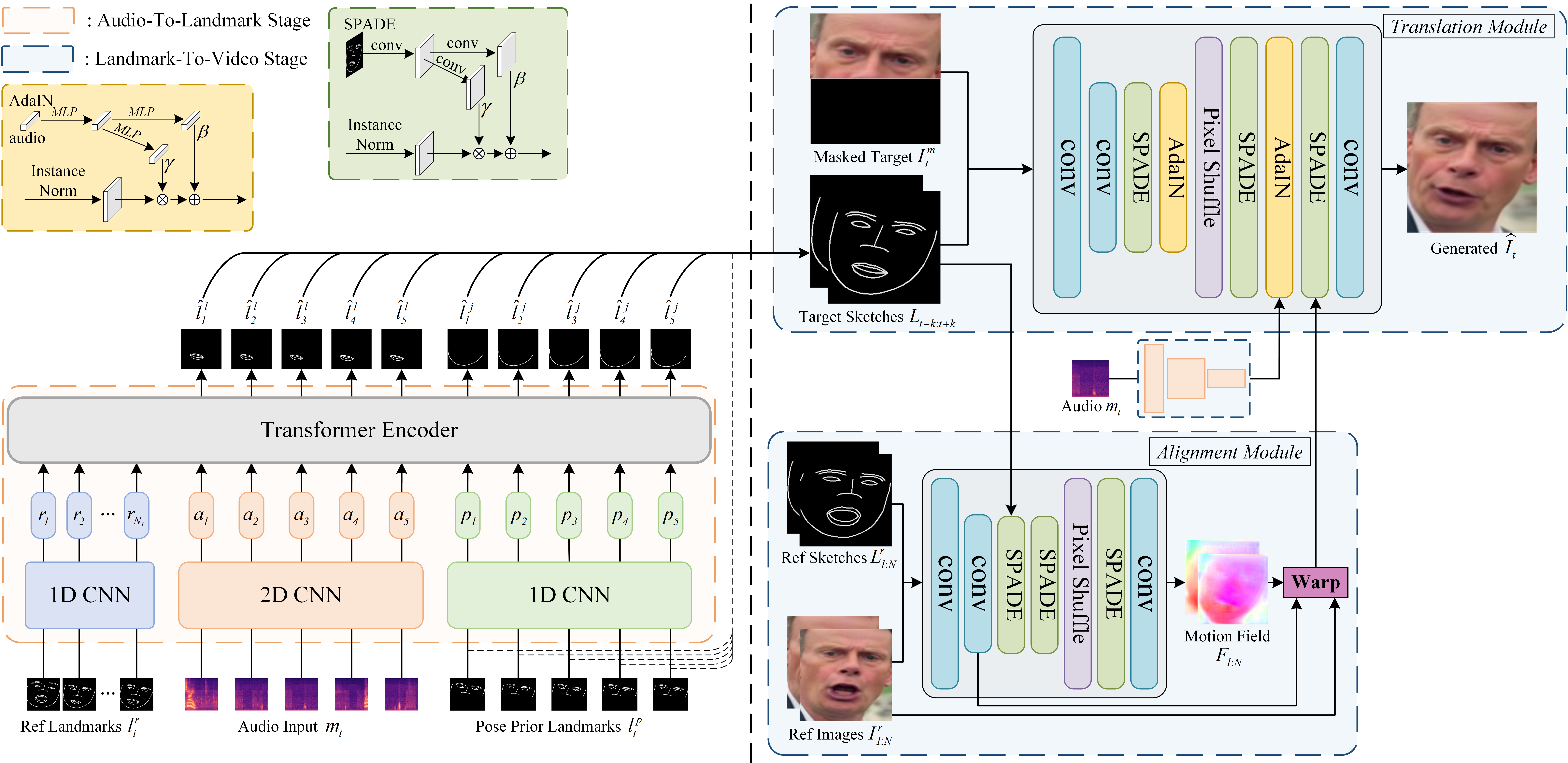
待办事项:
- 演示视频
- 预训练模型
- 测试代码
- 训练代码
- 数据集预处理代码
- 指南
- arXiv论文发布
环境要求
- Python 3.7.13
- torch 1.10.0
- torchvision 0.11.0
- ffmpeg
我们使用4张24G RTX3090在CUDA 11.1上进行实验。更多详情请参考requirements.txt。我们建议先安装pytorch,然后运行:
pip install -r requirements.txt
测试
从OneDrive或坚果云下载预训练模型,并将它们放在test/checkpoints文件夹中。然后运行以下命令:
CUDA_VISIBLE_DEVICES=0 python inference_single.py
要对其他视频进行推理,请指定--input和--audio选项,更多详情请查看代码。
评估代码类似于这个仓库。
训练
下载LRS2数据集
我们的模型在LRS2上训练。请访问LRS2网站下载数据集。LRS2数据集文件夹结构如下:
数据根目录 (mvlrs_v1)
├── main, pretrain (本工作中我们只使用main文件夹)
| ├── 文件夹列表
| │ ├── 以(.mp4)结尾的五位数视频ID
main文件夹即下文提到的lrs2_video。
预处理音频
通过运行以下命令从视频文件中提取原始音频和梅尔频谱特征:
CUDA_VISIBLE_DEVICES=0 python preprocess_audio.py --data_root ....../lrs2_video/ --out_root ..../lrs2_audio
预处理视频中的人脸
通过运行以下命令从视频文件中提取裁剪后的人脸、特征点和草图:
CUDA_VISIBLE_DEVICES=0 python preprocess_video.py --dataset_video_root ....../lrs2_video/ --output_sketch_root ..../lrs2_sketch --output_face_root ..../lrs2_face --output_landmark_root ..../lrs2_landmarks
训练特征点生成器
通过运行以下命令训练特征点生成器网络:
CUDA_VISIBLE_DEVICES=0 python train_landmarks_generator.py --pre_audio_root ..../lrs2_audio --landmarks_root ..../lrs2_landmarks
模型训练直到eval_L1_loss不再下降(约6e-3)。 在默认的批量大小设置下,使用单个RTX 3090,我们的模型在第1837个epoch(610k次迭代)停止,eval_L1_loss为5.866e-3,用时不超过一天。
训练视频渲染器
视频渲染器的训练类似(使用四张RTX 3090)。训练直到FID不再下降(约20或更低)。 通过运行以下命令训练视频渲染器网络:
CUDA_VISIBLE_DEVICES=0,1,2,3 python train_video_renderer.py --sketch_root ..../lrs2_sketch --face_img_root ..../lrs2_face --audio_root ..../lrs2_audio
请注意,平移模块将在25个epoch后才开始训练,因此fid和running_gen_loss将在25个epoch后才开始下降。
致谢
本项目基于公开可用的代码DFRF、pix2pixHD、vico_challenge和Wav2Lip构建。感谢这些作品的作者公开他们优秀的工作和代码。
引用和Star
如果您在研究中使用了本仓库,请引用以下论文并为本项目点Star。谢谢!
@InProceedings{Zhong_2023_CVPR,
author = {Zhong, Weizhi and Fang, Chaowei and Cai, Yinqi and Wei, Pengxu and Zhao, Gangming and Lin, Liang and Li, Guanbin},
title = {Identity-Preserving Talking Face Generation With Landmark and Appearance Priors},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
pages = {9729-9738}
}











