
 Github
Github Huggingface
Huggingface 文档
文档 论文
论文通过多模态大语言模型掌握文本到图像扩散:重新描述、规划和生成 - ICML 2024
本仓库包含我们的RPG的官方实现,已被ICML 2024接收。
通过多模态大语言模型掌握文本到图像扩散:重新描述、规划和生成
杨凌, 于兆晨, 孟陈林, 徐敏凯, Stefano Ermon, 崔斌
北京大学, 斯坦福大学, Pika Labs
介绍
 |
| RPG概述 |
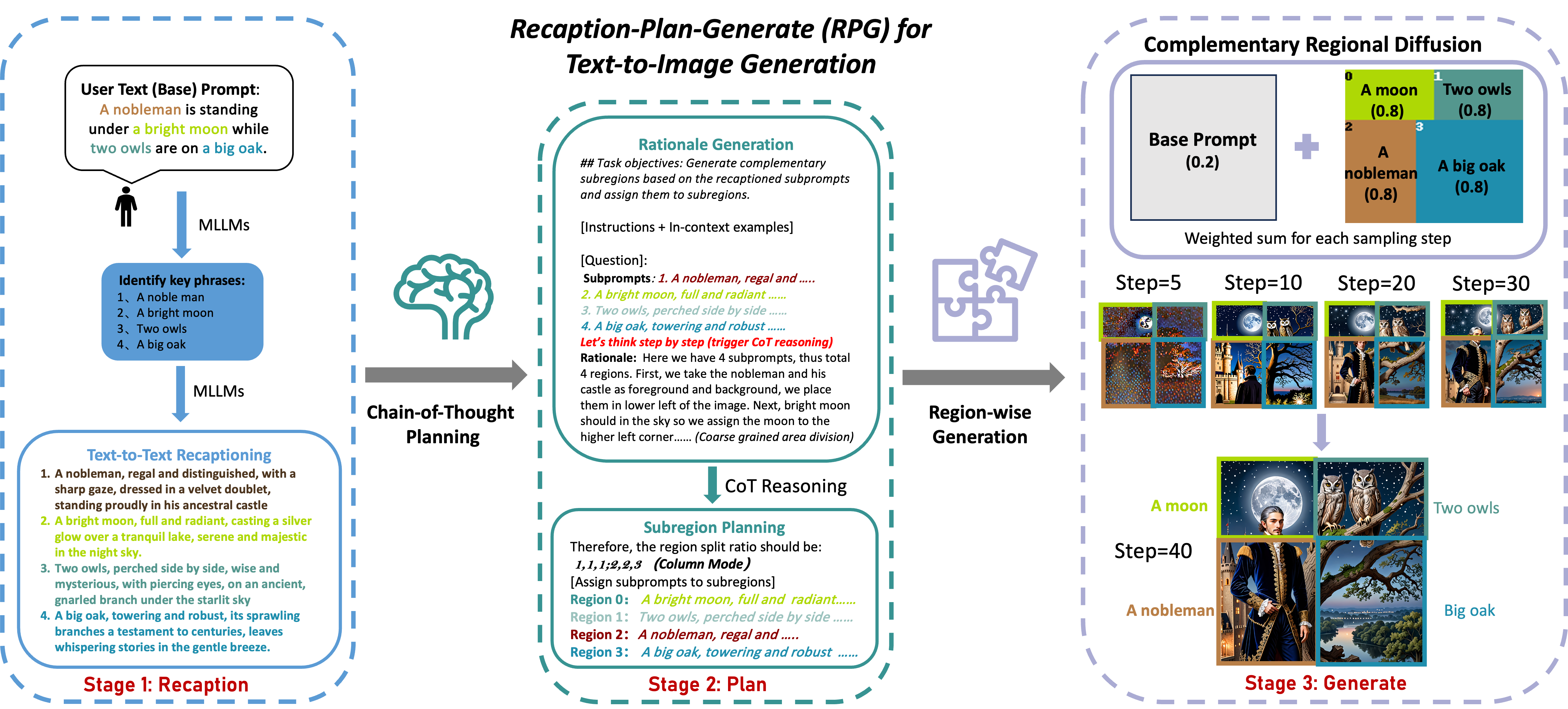
摘要: RPG是一种强大的无需训练的范式,可以利用专有的多模态大语言模型(如GPT-4、Gemini-Pro)或开源的本地多模态大语言模型(如miniGPT-4)作为提示重描述器和区域规划器,结合我们的互补区域扩散,实现最先进的文本到图像生成和编辑。我们的框架非常灵活,可以推广到任意多模态大语言模型架构和扩散模型骨干。RPG还能生成超高分辨率图像,这里有一个例子:
 |
| 文本提示:一幅美丽的风景,中间有一条河。河的左边是冬天的傍晚,有一座大冰山和一个小村庄,一些人在河上滑冰,一些人在滑雪。河的右边是夏天的清晨,有一座火山和一个小村庄,一些人在玩耍。 |
🚩 最新更新
[2024.1] 我们的主要代码连同演示已发布,支持不同的扩散模型骨干(SDXL, SD v2.0/2.1 SD v1.4/1.5),可以利用GPT-4和Gemini-Pro复现我们的良好结果。我们的RPG也兼容本地多模态大语言模型,我们将在未来继续改进结果。
[2024.4] 我们的代码库已基于diffusers更新,现在同时支持扩散模型的ckpts和diffusers。对于扩散模型骨干,可以使用RegionalDiffusionPipeline用于SD v2.0/2.1 SD v1.4/1.5等基础模型,使用RegionalDiffusionXLPipeline用于SDXL。
待办事项
- 更新Gradio演示
- 发布自我优化版RPG
- 发布用于图像编辑的RPG
- 发布带ControlNet的RPG v3
- 发布支持diffusers的RPG v2
- 发布RPG v1
画廊
1. 多人物复杂属性绑定
1024*1024示例
这是一幅英语到中文的翻译,请提供此源文本的中文翻译。 不要提供任何解释或翻译以外的文本。 注意:翻译需要符合中文语序、流畅、通顺 |  |  |  |
| 一个白色马尾辫、穿黑色连衣裙的女孩正在咖啡厅里与一个金色卷发、穿白色连衣裙的女孩聊天。 | 一个双马尾女孩,戴着棕色牛仔帽,穿着印有苹果图案的白色衬衫,蓝色牛仔裤和及膝靴,全身照。 | 一对情侣,左边是美丽的女孩,银色头发,编织马尾辫,快乐,充满活力,精力充沛,平和;右边是英俊的年轻男子,面部细节精美,咧嘴而笑,金色头发,迷人。 | 两位穿着旗袍的漂亮中国女孩正在茶室里品茶,墙上挂着一幅中国山水画。左边的女孩梳着黑色马尾辫,身穿红色旗袍;右边的女孩梳着白色马尾辫,身穿橙色旗袍。 |
2048*1024 示例
 |
| 从左到右,一位金发马尾辫的欧洲女孩穿着白衬衫,一位棕色卷发的非洲女孩穿着印有鸟图案的蓝色衬衫,一位黑色短发的亚洲年轻男子穿着西装,他们正开心地在校园里行走。 |
2. 多物体复杂关系
1024*1024 示例
 |  |  |  |
| 从左到右,木地板上有两个红苹果、一件印有苹果图案的衬衫和一台iPad。 | 大理石桌上摆放着七个带有不同几何图案的白色陶瓷杯,左侧放着一束玫瑰花。 | 木桌上呈X形排列着五个西瓜,中间的一个被切开了,写实风格,俯视角。 | 从左到右,沐浴在柔和的晨光中,一个温馨的角落里,一杯冒着热气的星巴克拿铁咖啡放在粗犷的桌子上,旁边是一个优雅的花瓶,里面插着盛开的玫瑰,而一只毛茸茸的布偶猫在附近舒适地打着呼噜,它的眼睛半闭着,流露出幸福安详的神情。 |
2048*1024 示例
 |
| 一个绿色双马尾的女孩穿着橙色连衣裙坐在沙发上,左边是一张凌乱的桌子,桌子上方有一扇大窗户,沙发右上方是一个生机勃勃的鱼缸,写实风格。 |
3. RPG 与 ControlNet
OpenPose 示例
| OpenPose | |
 |  |
深度图示例
| 深度图 | |
 |  |
Canny 边缘示例
| Canny 边缘 | |
 |  |
prompt 是大致概括图像内容的原始提示词
base_prompt 设置生成的基础提示词,是图像的概要,这里我们默认将 base_prompt 设置为原始输入提示词
base_ratio 是基础提示词的权重
还有其他常见的可选参数:
guidance_scale 是无分类器引导比例
num_inference_steps 是生成图像的步骤数
seed 控制种子以使生成可重现
需要注意的是,我们引入了一些重要参数:base_prompt & base_ratio
在添加你的 prompt 和 api-key,并设置你的 下载的扩散模型路径 后,只需运行以下命令即可获得结果:
python RPG.py
常见问题:如何正确设置 --base_prompt & --base_ratio ?
如果你想生成一张包含 同一类的多个实体 的图像(例如,两个女孩、三只猫、一个男人和一个女孩),你应该使用 基础提示词,并使用 base_prompt 设置包含图像中每类实体数量的基础提示词。另一个相关参数是 base_ratio,这是基础提示词的权重。根据我们的实验,当 base_ratio 在 [0.35,0.55] 之间时,最终结果会更好。以下是上述命令生成的图像:
只要我们有相同的随机种子,你就会得到一张与我们结果类似的图像:
<表格居中> <行> <单元格宽度=100% 样式="无边框"><图片 src="https://yellow-cdn.veclightyear.com/ab5030c0/8583d4be-585a-4bfe-93ce-2f08c63d7736.png" 样式="宽度:100%"></单元格> </行> <行> <单元格宽度="100%" 样式="无边框; 文字居中; 自动换行">文本提示词:一个英俊的金发卷发年轻男子穿着黑色西装,和一个穿红色旗袍的黑色双马尾女孩在酒吧里。 </单元格> </行> </表格>
另一方面,当涉及到包含 多个不同类别的实体 的图像时,就不需要使用基础提示词,这里有一个例子:
from RegionalDiffusion_base import RegionalDiffusionPipeline
from RegionalDiffusion_xl import RegionalDiffusionXLPipeline
from diffusers.schedulers import KarrasDiffusionSchedulers,DPMSolverMultistepScheduler
from mllm import local_llm,GPT4
import torch
# 如果你想加载ckpt,用".from_single_file"初始化。
pipe = RegionalDiffusionXLPipeline.from_single_file("你的ckpt路径",torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
# #如果你想使用 diffusers,用".from_pretrained"初始化。
# pipe = RegionalDiffusionXLPipeline.from_pretrained("你的 diffusers 路径",torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config,use_karras_sigmas=True)
pipe.enable_xformers_memory_efficient_attention()
prompt= '从左到右,在柔和的晨光中,一个舒适的角落里有一杯冒着热气的星巴克拿铁放在一张朴实的桌子上,旁边是一个优雅的花瓶里盛开的玫瑰,同时一只毛茸茸的布偶猫舒服地在附近打着呼噜,它的眼睛半闭着,陶醉在幸福的宁静中。'
para_dict = GPT4(prompt,key='你的密钥')
split_ratio = para_dict['Final split ratio']
regional_prompt = para_dict['Regional Prompt']
negative_prompt = ""
images = pipe(
prompt=regional_prompt,
split_ratio=split_ratio, # 区域提示词的比例,提示词数量与区域数量相同
batch_size = 1, #批量大小
base_ratio = 0.5, # 基础提示词的比例
base_prompt= None, # 如果base_prompt为None,base_ratio将不起作用
num_inference_steps=20, # 采样步骤
height = 1024,
negative_prompt=negative_prompt, # 负面提示词
width = 1024,
seed = None,# 随机种子
guidance_scale = 7.0
).images[0]
images.save("test.png")
你将得到一张与我们结果类似的图像:
<表格居中> <行> <单元格宽度=100% 样式="无边框"><图片 src="https://yellow-cdn.veclightyear.com/ab5030c0/6767d711-45cc-4743-ba3f-64e087af8895.png" 样式="宽度:100%"></单元格> </行> <行> <单元格宽度="100%" 样式="无边框; 文字居中; 自动换行">文本提示词:从左到右,在柔和的晨光中,一个舒适的角落里有一杯冒着热气的星巴克拿铁放在一张朴实的桌子上,旁边是一个优雅的花瓶里盛开的玫瑰,同时一只毛茸茸的布偶猫舒服地在附近打着呼噜,它的眼睛半闭着,陶醉在幸福的宁静中。 </单元格> </行> </表格>
了解什么时候应该使用 base_prompt 很重要,如果这些参数设置不当,我们就无法获得令人满意的结果。我们在论文中对基础提示词进行了消融研究,你可以查看我们的论文获取更多信息。
3. 使用本地 LLM 的区域扩散
我们建议使用超过 130 亿参数的基础模型以获得高质量的结果,但这同时会增加加载时间和显存使用。我们用三种不同规模的模型进行了实验。这里我们以 llama2-13b-chat 为例:
from RegionalDiffusion_base import RegionalDiffusionPipeline
from RegionalDiffusion_xl import RegionalDiffusionXLPipeline
from diffusers.schedulers import KarrasDiffusionSchedulers,DPMSolverMultistepScheduler
from mllm import local_llm,GPT4
import torch
# 如果你想使用单个检查点,使用此管道
pipe = RegionalDiffusionXLPipeline.from_single_file("你的检查点路径",torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
# 如果你想使用diffusers,使用此管道
# pipe = RegionalDiffusionXLPipeline.from_pretrained("你的diffusers路径",torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config,use_karras_sigmas=True)
pipe.enable_xformers_memory_efficient_attention()
prompt= '两个女孩在咖啡馆里聊天。'
para_dict = local_llm(prompt,model_path='你的模型路径')
split_ratio = para_dict['Final split ratio']
regional_prompt = para_dict['Regional Prompt']
negative_prompt = ""
images = pipe(
prompt=regional_prompt,
split_ratio=split_ratio, # 区域提示的比例,提示数量与区域数量相同,提示数量与区域数量相同
batch_size = 1, #批次大小
base_ratio = 0.5, # 基础提示的比例
base_prompt= prompt,
num_inference_steps=20, # 采样步骤
height = 1024,
negative_prompt=negative_prompt, # 负面提示
width = 1024,
seed = 1234,# 随机种子
guidance_scale = 7.0
).images[0]
images.save("test.png")
在本地版本中,添加你的提示并设置好扩散模型路径和本地MLLM/LLM路径后,只需运行以下命令即可获得结果:
python RPG.py
# 📖BibTeX
@inproceedings{yang2024mastering, title={Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs}, author={Yang, Ling and Yu, Zhaochen and Meng, Chenlin and Xu, Minkai and Ermon, Stefano and Cui, Bin}, booktitle={International Conference on Machine Learning}, year={2024} }
# 致谢
我们的RPG是一个通用的MLLM控制的文本到图像生成/编辑框架,它建立在几个坚实的工作基础之上。感谢[AUTOMATIC1111](https://github.com/AUTOMATIC1111/stable-diffusion-webui)、[regional-prompter](https://github.com/hako-mikan/sd-webui-regional-prompter)、[SAM](https://github.com/facebookresearch/segment-anything)、[diffusers](https://github.com/huggingface/diffusers)和[IA](https://github.com/geekyutao/Inpaint-Anything)的出色工作和代码库!我们还要感谢Hugging Face分享我们的[论文](https://huggingface.co/papers/2401.11708)。












{kind=link}
{kind=link}