
 访问官网
访问官网 Github
Github 文档
文档AutoCrawler
谷歌、Naver多进程图片爬虫(高质量、高速度、可定制)
使用方法
-
安装Chrome
-
pip install -r requirements.txt
-
在keywords.txt中编写搜索关键词
-
运行 "main.py"
-
文件将下载到'download'目录。
参数
用法:
python3 main.py [--skip true] [--threads 4] [--google true] [--naver true] [--full false] [--face false] [--no_gui auto] [--limit 0]
--skip true 如果下载目录已经存在,跳过关键词。当重新下载时需要此选项。
--threads 4 下载线程数。
--google true 从google.com下载(布尔值)
--naver true 从naver.com下载(布尔值)
--full false 下载全分辨率图像而不是缩略图(较慢)
--face false 面部搜索模式
--no_gui auto 无GUI模式。(无头模式)加速全分辨率模式,但在缩略图模式下不稳定。
默认:"auto" - full=false时为false,full=true时为true
(可用于Docker Linux系统)
--limit 0 每个网站下载图像的最大数量。(0:无限)
--proxy-list '' 逗号分隔的代理列表,例如:"socks://127.0.0.1:1080,http://127.0.0.1:1081"。
每个线程将随机选择其中一个。
全分辨率模式
通过指定--full true,你可以下载JPG、GIF、PNG文件的全分辨率图像
数据不平衡检测
基于文件数量检测数据不平衡。
爬取结束后,信息会显示哪些目录低于平均文件数的50%。
建议你删除这些目录并重新下载。
通过SSH在服务器上远程爬取
sudo apt-get install xvfb <- 这是虚拟显示
sudo apt-get install screen <- 这将允许你在运行时关闭SSH终端。
screen -S s1
Xvfb :99 -ac & DISPLAY=:99 python3 main.py
自定义
你可以通过更改collect_links.py来制作自己的爬虫
如何解决问题
由于google网站不断变化,你可能需要修复collect_links.py
- 进入谷歌图片。https://www.google.com/search?q=dog&source=lnms&tbm=isch
- 在Chrome上打开开发者工具。 (CTRL+SHIFT+I,CMD+OPTION+I)
- 指定一张图片进行捕获。
- 查看collect_links.py
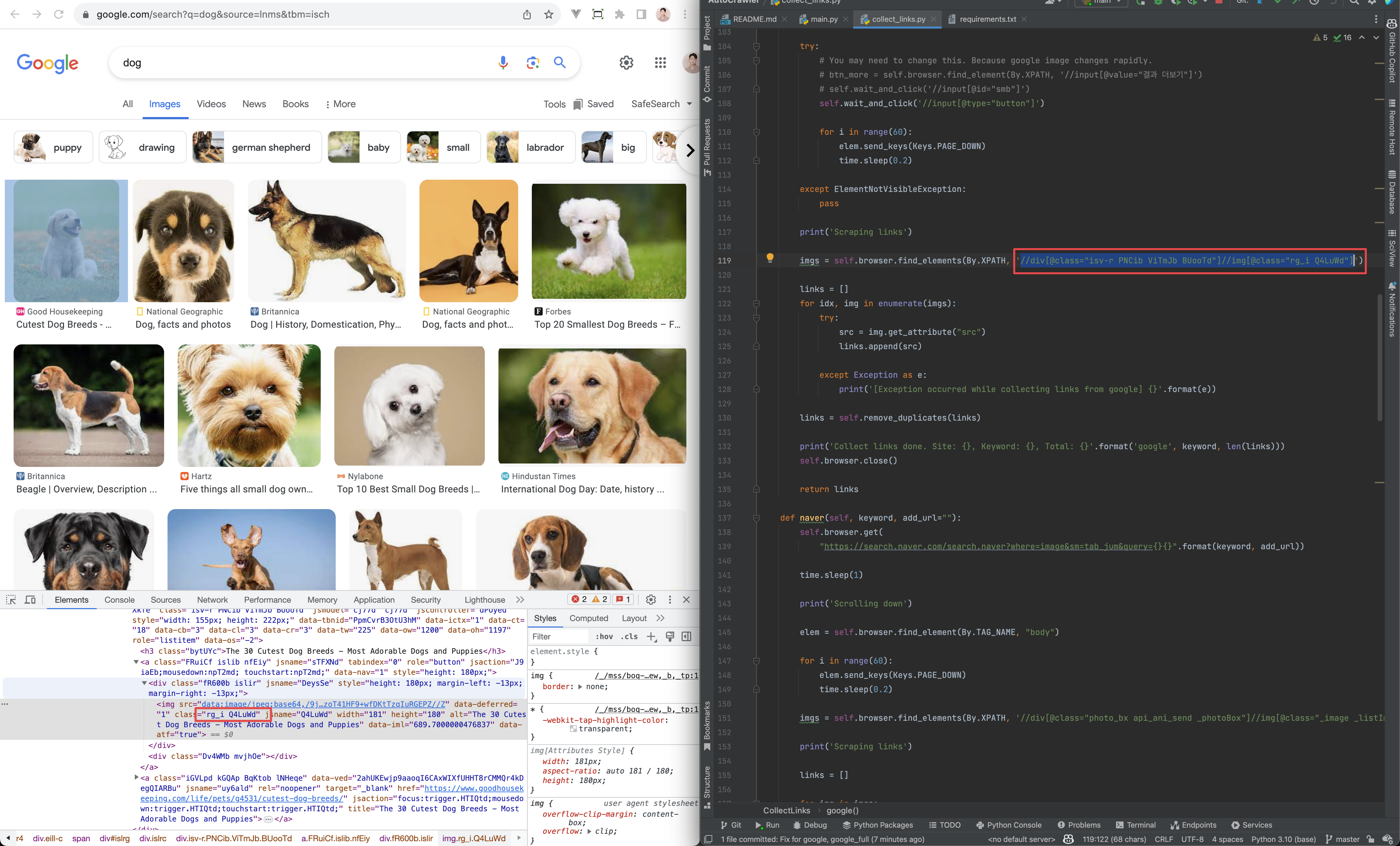
- XPATH用法文档:https://www.w3schools.com/xml/xpath_syntax.asp
- 你可以在Chrome开发者工具中使用CTRL+F测试XPATH。
- 你需要找到使爬取工作的方法。











