
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文

Monkey:图像分辨率和文本标签对大型多模态模型至关重要
请为最新更新点亮星标 ⭐



💡 Monkey系列项目:✨
[CVPR'24] Monkey:图像分辨率和文本标签对大型多模态模型至关重要
张力, 杨彪, 刘强, 马志银, 张硕, 杨敬旭, 孙亚博, 刘玉良, 白翔






TextMonkey:无需OCR的大型多模态文档理解模型
刘玉良, 杨彪, 刘强, 张力, 马志银, 张硕, 白翔


Mini-Monkey:多模态大语言模型的多尺度自适应裁剪
黄明鑫, 刘玉良, 梁定康, 金连文, 白翔

新闻
2024.8.13🚀 Mini-Monkey的源代码已发布。2024.8.6🚀 我们发布了Mini-Monkey论文。2024.4.13🚀 TextMonkey的源代码已发布。2024.4.5🚀 Monkey被提名为CVPR 2024亮点论文。2024.3.8🚀 我们发布了TextMonkey论文。2024.2.27🚀 Monkey被CVPR 2024接收。2024.1.3🚀 发布基础数据生成流程。数据生成2023.12.16🚀 Monkey现可使用8张NVIDIA 3090 GPU进行训练。详见训练小节。2023.11.06🚀 我们发布了Monkey论文。
🐳 模型库
Monkey-Chat
| 模型 | 语言模型 | Transformers(HF) | MMBench-Test | CCBench | MME | SeedBench_IMG | MathVista-MiniTest | HallusionBench-Avg | AI2D Test | OCRBench |
|---|---|---|---|---|---|---|---|---|---|---|
| Monkey-Chat | Qwev-7B | 🤗echo840/Monkey-Chat | 72.4 | 48 | 1887.4 | 68.9 | 34.8 | 39.3 | 68.5 | 534 |
| Mini-Monkey | internlm2-chat-1_8b | Mini-Monkey | --- | 75.5 | 1881.9 | 71.3 | 47.3 | 38.7 | 74.7 | 802 |
环境
conda create -n monkey python=3.9
conda activate monkey
git clone https://github.com/Yuliang-Liu/Monkey.git
cd ./Monkey
pip install -r requirements.txt
您可以从https://github.com/Dao-AILab/flash-attention/releases/下载相应版本的flash_attention,并使用以下代码安装:
pip install flash_attn-2.3.5+cu117torch2.0cxx11abiFALSE-cp39-cp39-linux_x86_64.whl --no-build-isolation
训练
我们还提供了Monkey的模型定义和训练代码,您可以在上面探索。您可以通过执行finetune_ds_debug.sh来执行Monkey的训练代码,通过执行finetune_textmonkey.sh来执行TextMonkey的训练代码。
用于Monkey训练的json文件可以在此链接下载。
推理
运行Monkey和Monkey-Chat的推理代码:
python ./inference.py --model_path 模型路径 --image_path 图像路径 --question "您的问题"
演示
演示快速且易于使用。只需从桌面或手机上传图像,或直接拍摄一张。 Demo_chat作为原始演示的升级版本也已启动,以提供增强的交互体验。
我们还提供了原始演示的源代码和模型权重,允许您自定义某些参数以获得更独特的体验。具体操作如下:
- 确保您已配置环境。
- 您可以选择离线或在线使用演示:
- 离线:
- 下载模型权重。
- 修改
demo.py文件中的DEFAULT_CKPT_PATH="pathto/Monkey"为您的模型权重路径。 - 使用以下命令运行演示:
python demo.py - 在线:
- 使用以下命令运行演示并在线下载模型权重:
python demo.py -c echo840/Monkey
对于TextMonkey,您可以从模型权重下载模型权重,并运行演示代码:
python demo_textmonkey.py -c 模型路径
在2023年11月14日之前,我们观察到对于一些随机图片,Monkey可以比GPT4V获得更准确的结果。
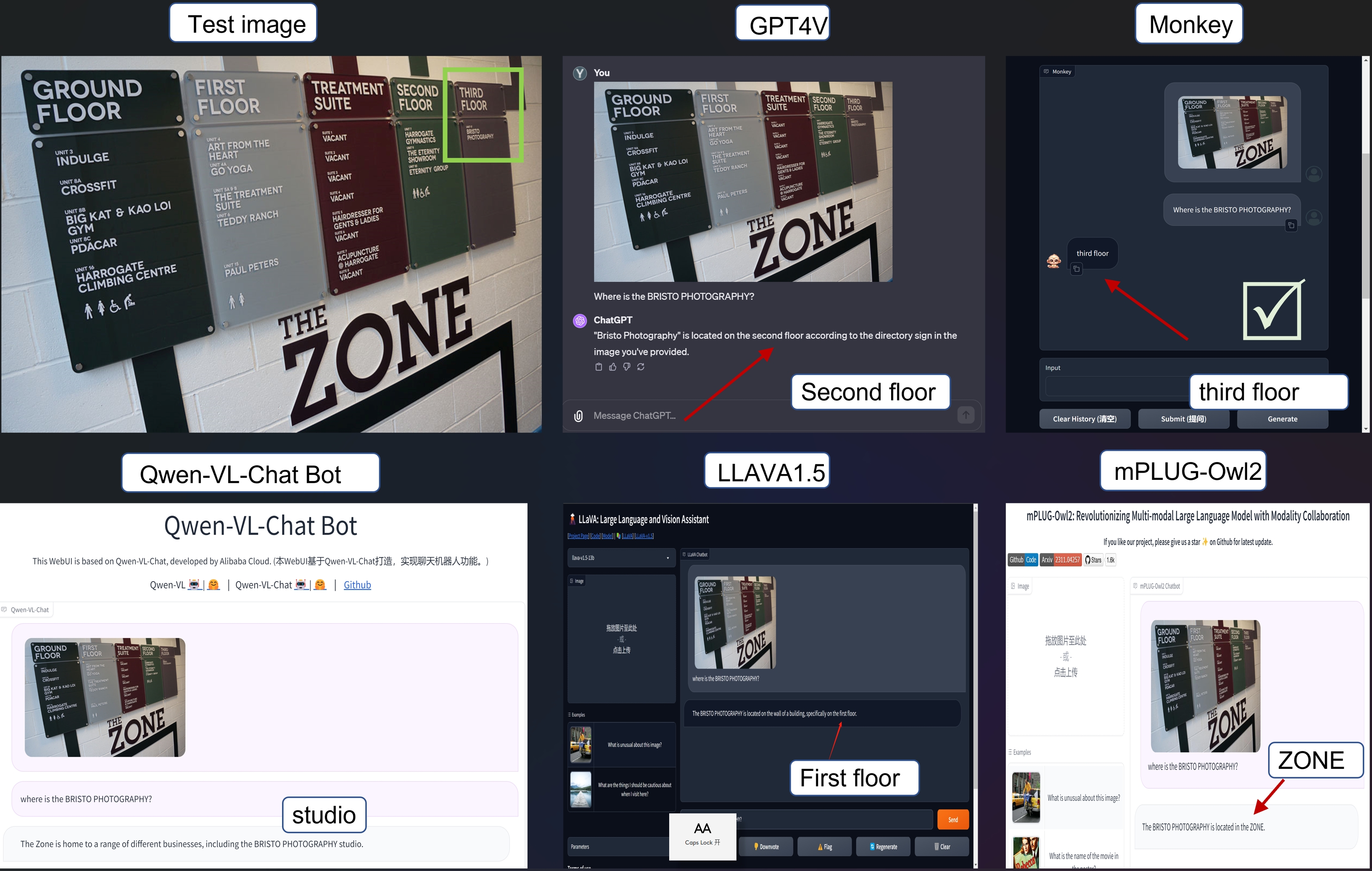
在2024年1月31日之前,Monkey-chat在OpenCompass的多模态模型类别中排名第五。

数据集
你可以从Monkey_Data下载Monkey使用的训练和测试数据。
Monkey训练所用的json文件可以在此链接下载。
我们多层次描述生成方法的数据现已开源,可在此链接下载。我们已上传了多层次描述中使用的图片。示例:

你可以从此链接下载Monkey的训练图片。提取码:4hdh
你可以从此链接下载Monkey的测试图片和jsonl文件。提取码:5h71
这些图片来自CC3M、COCO Caption、TextCaps、VQAV2、OKVQA、GQA、ScienceQA、VizWiz、TextVQA、OCRVQA、ESTVQA、STVQA、AI2D和DUE_Benchmark。使用数据时,需遵守原始数据集的协议。
评估
我们在evaluate_vqa.py文件中提供了14个视觉问答(VQA)数据集的评估代码,便于快速验证结果。具体操作如下:
- 确保已配置环境。
- 修改
sys.path.append("pathto/Monkey")为项目路径。 - 准备评估所需的数据集。
- 运行评估代码。
以ESTVQA为例:
- 按以下目录结构准备数据:
├── data
| ├── estvqa
| ├── test_image
| ├── {image_path0}
| ├── {image_path1}
| ·
| ·
| ├── estvqa.jsonl
- 注释
.jsonl文件每行格式示例:
{"image": "data/estvqa/test_image/011364.jpg", "question": "What is this store?", "answer": "pizzeria", "question_id": 0}
- 修改字典
ds_collections:
ds_collections = {
'estvqa_test': {
'test': 'data/estvqa/estvqa.jsonl',
'metric': 'anls',
'max_new_tokens': 100,
},
...
}
- 运行以下命令:
bash eval/eval.sh 'EVAL_PTH' 'SAVE_NAME'
引用Monkey
如果你想引用此处发布的基准结果,请使用以下BibTeX条目:
@inproceedings{li2023monkey,
title={Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models},
author={Li, Zhang and Yang, Biao and Liu, Qiang and Ma, Zhiyin and Zhang, Shuo and Yang, Jingxu and Sun, Yabo and Liu, Yuliang and Bai, Xiang},
booktitle={proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
year={2024}
}
@article{liu2024textmonkey,
title={TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document},
author={Liu, Yuliang and Yang, Biao and Liu, Qiang and Li, Zhang and Ma, Zhiyin and Zhang, Shuo and Bai, Xiang},
journal={arXiv preprint arXiv:2403.04473},
year={2024}
}
@article{huang2024mini,
title={Mini-Monkey: Multi-Scale Adaptive Cropping for Multimodal Large Language Models},
author={Huang, Mingxin and Liu, Yuliang and Liang, Dingkang and Jin, Lianwen and Bai, Xiang},
journal={arXiv preprint arXiv:2408.02034},
year={2024}
}
致谢
Qwen-VL、LLAMA、LLaVA、OpenCompass、InternLM、InternVL。
版权
我们欢迎提出建议以帮助我们改进Monkey。如有任何疑问,请联系刘玉良博士:ylliu@hust.edu.cn。如果你发现有趣的内容,也欢迎通过电子邮件或提出问题与我们分享。谢谢!











