
 访问官网
访问官网 Github
Githubw2vgrep - 语义搜索工具
w2vgrep 是一个命令行工具,使用词嵌入技术对文本输入进行语义搜索。它旨在找到与查询在语义上相似的匹配项,超越了简单的字符串匹配。支持多种语言。其使用体验设计类似于 grep。
使用示例
在海明威的《老人与海》中搜索与"死亡"语义相似的词,显示上下文和行号:
curl -s 'https://gutenberg.ca/ebooks/hemingwaye-oldmanandthesea/hemingwaye-oldmanandthesea-00-t.txt' \
| w2vgrep -C 2 -n --threshold=0.55 death
输出:
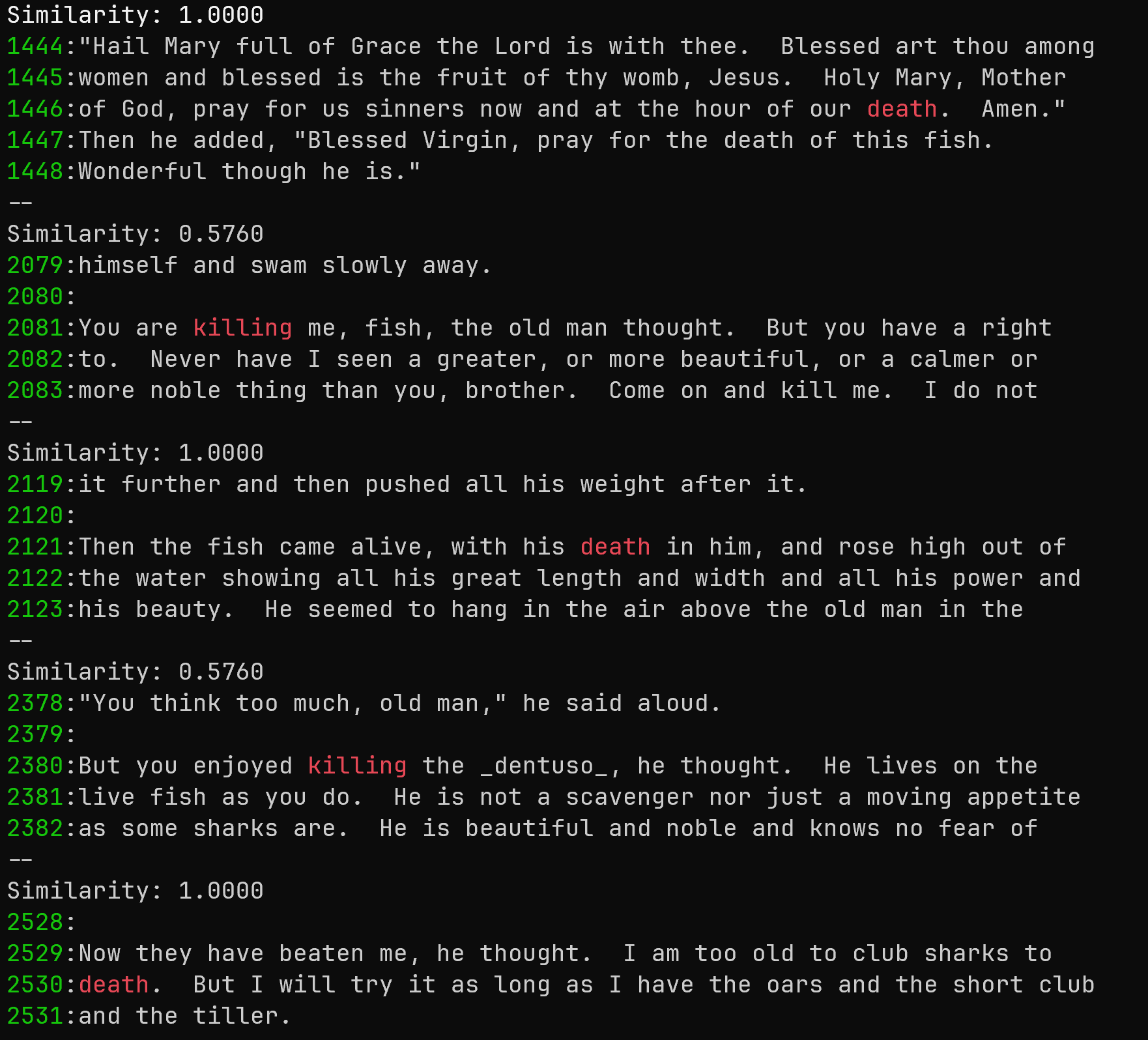
这个命令:
- 从加拿大古腾堡计划网站获取《老人与海》的文本
- 将文本通过管道传递给 w2vgrep
- 搜索与"死亡"在语义上相似的词
- 使用 0.55 的相似度阈值(-threshold 0.55)
- 显示每个匹配项前后 2 行的上下文(-C 2)
- 显示行号(-n)
输出将显示匹配项及其相似度分数、高亮显示的词、上下文和行号。
功能
- 使用词嵌入进行语义搜索
- 可配置的相似度阈值
- 显示上下文(匹配行的前后)
- 颜色编码输出
- 支持多种语言
- 从文件或标准输入读取
- 通过 JSON 文件和命令行参数进行配置
安装
绝对需要两个文件:
- w2vgrep 二进制文件
- 向量嵌入模型文件
- (可选)config.json 文件,用于告诉 w2vgrep 嵌入模型的位置
使用安装脚本:
# 克隆
git clone https://github.com/arunsupe/semantic-grep.git
cd semantic-grep
# 运行安装:
# 使用本地 go 编译器编译,安装到 user/bin,
# 将模型下载到 $HOME/.config/semantic-grep
# 创建 config.json
bash install.sh
二进制文件:
- 下载最新的二进制发布版
- 下载向量嵌入模型(见下文)
- 可选择下载 config.json 以在其中配置模型位置(或从命令行进行配置)
从源代码构建(Linux/OSX):
# 克隆
git clone https://github.com/arunsupe/semantic-grep.git
cd semantic-grep
# 构建
go build -o w2vgrep
# 使用此辅助脚本下载 word2vec 模型(参见下文的"词嵌入模型")
bash download-model.sh
用法
基本用法:
./w2vgrep [选项] <查询> [文件]
如果未指定文件,w2vgrep 从标准输入读取。
命令行选项
-m, --model_path= Word2Vec 模型文件的路径。覆盖配置文件
-t, --threshold= 匹配的相似度阈值(默认:0.7)
-A, --before-context= 匹配行之前的行数
-B, --after-context= 匹配行之后的行数
-C, --context= 匹配行前后的行数
-n, --line-number 打印行号
-i, --ignore-case 忽略大小写
-o, --only-matching 仅输出匹配的单词
-l, --only-lines 仅输出匹配的行,不显示相似度分数
-f, --file= 从文件中匹配模式,每行一个模式。类似于 grep -f
配置
w2vgrep 可以使用 JSON 文件进行配置。默认情况下,它会在当前目录、"$HOME/.config/semantic-grep/config.json" 和 "/etc/semantic-grep/config.json" 中查找 config.json。
词嵌入模型
快速入门:
w2vgrep 需要__二进制__格式的词嵌入模型。默认模型加载器使用模型文件的扩展名来确定类型(.bin、.8bit.int)。本仓库中提供了一些兼容的模型文件(models/)。从 models/ 目录下载一个 .bin 文件,并在 config.json 中更新路径。
注意:除非在您的机器上安装了 git lfs,否则 git clone 不会下载大型二进制模型文件。如果您不想安装 git-lfs,只需手动下载模型 .bin 文件并将其放在正确的文件夹中即可。
支持多种语言:
Facebook的fasttext团队已发布了157种语言的词向量,这是一个令人惊叹的资源。我想在我的github账户上托管这些文件,但遗憾的是,它们太大且需要花费。因此,我提供了一个小型go程序fasttext-to-bin,可以从中创建与w2vgrep兼容的二进制模型。(注意:使用带有".vec.gz"扩展名的文本文件,而不是".bin.gz"二进制文件)
# 例如,对于法语模型:
curl -s 'https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.fr.300.vec.gz' | gunzip -c | ./fasttext-to-bin -input - -output models/fasttext/cc.fr.300.bin
# 使用方法如下:
# curl -s 'https://www.gutenberg.org/cache/epub/17989/pg17989.txt' \
# | w2vgrep -C 2 -n -t 0.55 \
# -model_path model_processing_utils/cc.fr.300.bin 'château'
自己制作:
或者,你可以使用预训练模型(如Google的Word2Vec)或使用gensim等工具训练自己的模型。但请注意,似乎没有标准化的二进制格式(谷歌的格式与Facebook的fasttext或gensim的默认_save()_不同)。对于w2vgrep,由于高效加载大型模型对性能至关重要,我选择保持最简单的格式。
通过查找同义词测试模型
为了帮助排查模型问题,我在./model_processing_utils/中添加了一个synonym-finder.go。这个程序将在模型中找到与查询词相似度高于任何阈值的相似词。
# 构建
cd model_processing_utils
go build synonym-finder.go
# 运行
synonym-finder -model_path path/to/cc.zh.300.bin -threshold 0.6 合理性
# 输出
与'合理性'相似度>=0.60的词:
科学性 0.6304
合理性 1.0000
正当性 0.6018
公允性 0.6152
不合理性 0.6094
合法性 0.6219
有效性 0.6374
必要性 0.6499
关于不同嵌入模型性能的说明
不同模型对"相似性"的定义不同(解释)。然而,就实际目的而言,它们似乎足够等效。
贡献
欢迎贡献!请随时提交Pull Request。
许可和归属:
本项目的代码根据MIT许可证授权。
go-flags包:
本项目使用的go-flags包根据BSD-3-Clause许可证分发。请查看许可证信息https://github.com/jessevdk/go-flags。
Word2Vec模型:
本项目使用存储在models/googlenews-slim目录中的word2vec-slim模型的镜像版本。该模型根据Apache License 2.0分发。有关模型、其原作者和许可证的更多信息,请参阅models/googlenews-slim/ATTRIBUTION.md文件。
GloVe词向量:
本项目使用存储在models/glove目录中的GloVe词向量的处理版本。该作品根据Public Domain Dedication and License v1.0分发。有关模型、其原作者和许可证的更多信息,请参阅models/glove/ATTRIBUTION.md文件。
Fasttext词向量:
本项目使用存储在models/fasttext目录中的fasttext词向量的处理版本。该作品根据Creative Commons Attribution-Share-Alike License 3.0分发。有关模型、其原作者和许可证的更多信息,请参阅models/fasttext/ATTRIBUTION.md文件。
网络上的模型来源
- Google的Word2Vec:来自 https://github.com/mmihaltz/word2vec-GoogleNews-vectors
- 上述模型的精简版:GoogleNews-vectors-negative300-SLIM.bin.gz 模型,来自 https://github.com/eyaler/word2vec-slim/
- 斯坦福大学自然语言处理小组的全局词向量表示(glove)模型 来源:二进制版本镜像存放在 models/glove/ 目录下。
- Facebook的fasttext向量:https://fasttext.cc/docs/en/crawl-vectors.html











