
 Github
Github 文档
文档Semantra
https://user-images.githubusercontent.com/306095/233867821-601db8b0-19c6-4bae-8e93-720b324dc199.mov
Semantra是一个多用途的语义文档搜索工具。通过语义而非仅仅匹配文本来进行查询。
这个工具设计用于在命令行上运行,它分析你计算机上指定的文本和PDF文件,并启动一个本地Web搜索应用程序,用于交互式查询这些文件。Semantra的目的是使运行专门的语义搜索引擎变得简单、友好、可配置且私密/安全。
Semantra是为那些在海量信息中寻找细节的个人而设计的——在截稿期限前筛选泄露文件的记者、在论文中寻找洞见的研究人员、通过查询主题来深入理解文学的学生、连接跨书籍事件的历史学家等等。
资源
- 教程:Semantra入门的温和介绍——从安装工具到使用它分析文档的实践示例
- 指南:如何更好地使用Semantra的实用指南
- 概念:解释一些概念以更好地理解Semantra的工作原理
- 使用Web界面:Semantra网页应用的使用参考
本页面提供了Semantra的高级概述和功能参考。它也有其他语言版本:Semantra en español,Semantra 中文说明
安装
确保你已安装Python >= 3.9。
安装Semantra最简单的方法是通过pipx。如果你还没有安装pipx,请运行:
python3 -m pip install --user pipx
或者,如果你已安装Homebrew,可以运行brew install pipx。
安装pipx后,运行:
python3 -m pipx ensurepath
打开一个新的终端窗口,让pipx设置的新路径设置生效。然后运行:
pipx install semantra
这将在你的路径上安装Semantra。你应该能够在终端中运行semantra并看到输出。
注意:如果上述步骤不起作用,或者你想要更精细的安装,你可以在虚拟环境中安装Semantra(但请注意,它只有在虚拟环境激活时才能访问):
python3 -m venv venv
source venv/bin/activate
pip install semantra
使用方法
Semantra操作存储在本地计算机上的文档集合——文本或PDF文件。
最简单的情况下,你可以通过运行以下命令对单个文档使用Semantra:
semantra doc.pdf
你也可以对多个文档运行Semantra:
semantra report.pdf book.txt
Semantra需要一些时间来处理输入的文档。这是每个文档的一次性操作(后续对同一文档集合的运行将几乎瞬时完成)。
处理完成后,Semantra将启动一个本地Web服务器,默认地址为localhost:8080。在这个网页上,你可以交互式地对传入的文档进行语义查询。
快速说明:
当你第一次运行Semantra时,可能需要几分钟时间和几百兆字节的硬盘空间来下载可以处理你传入文档的本地机器学习模型。使用的模型可以自定义,但默认模型是快速、精简和高效的绝佳组合。
如果你想快速处理文档而不使用自己的计算资源,并且不介意付费或与外部服务共享数据,你可以使用OpenAI的嵌入模型。
Web应用快速导览
当你第一次导航到Semantra的Web界面时,你会看到这样的界面:
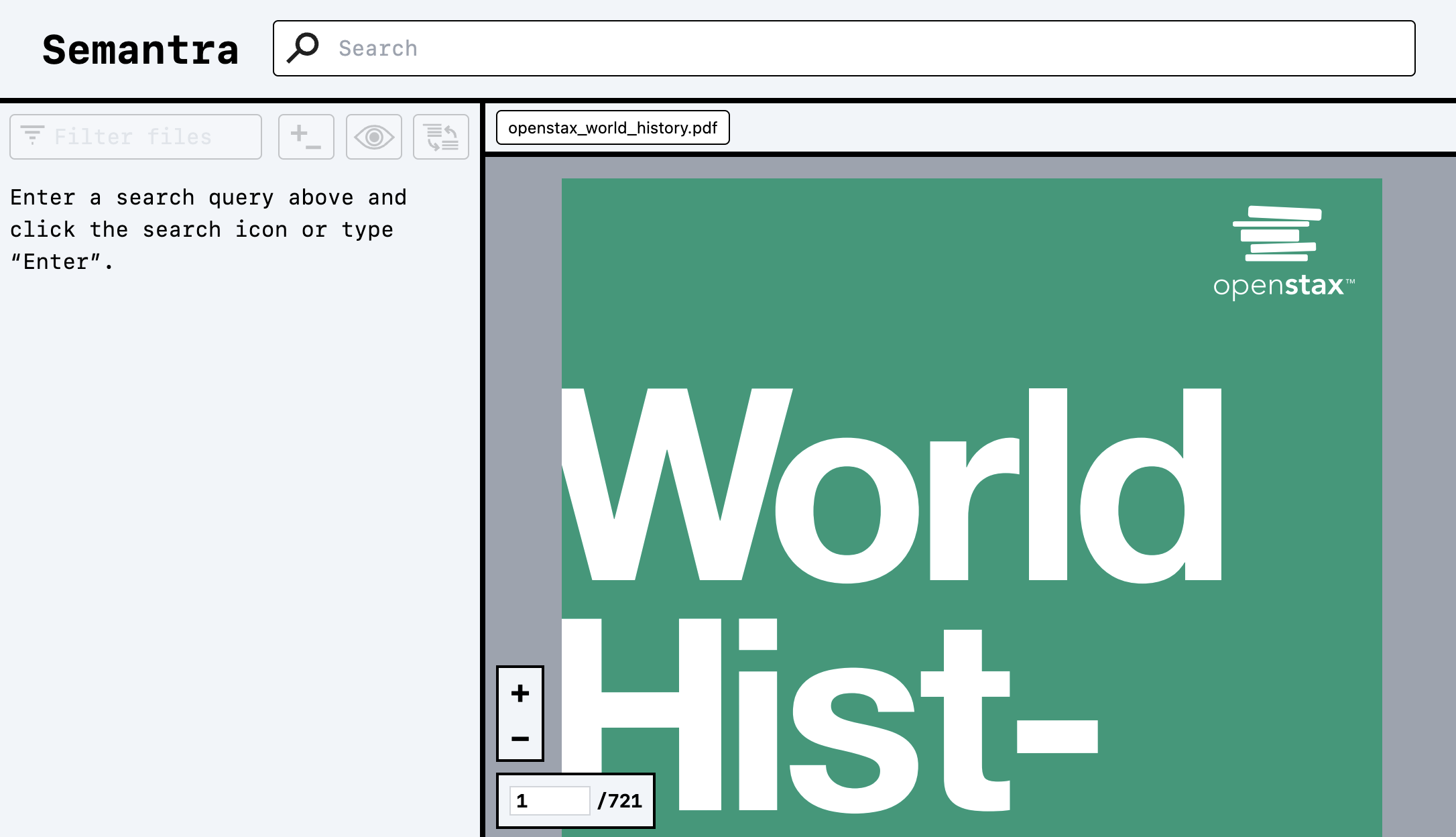
在搜索框中输入内容以开始语义查询。按Enter键或点击搜索图标执行查询。
搜索结果将按最相关文档的顺序出现在左侧窗格中:
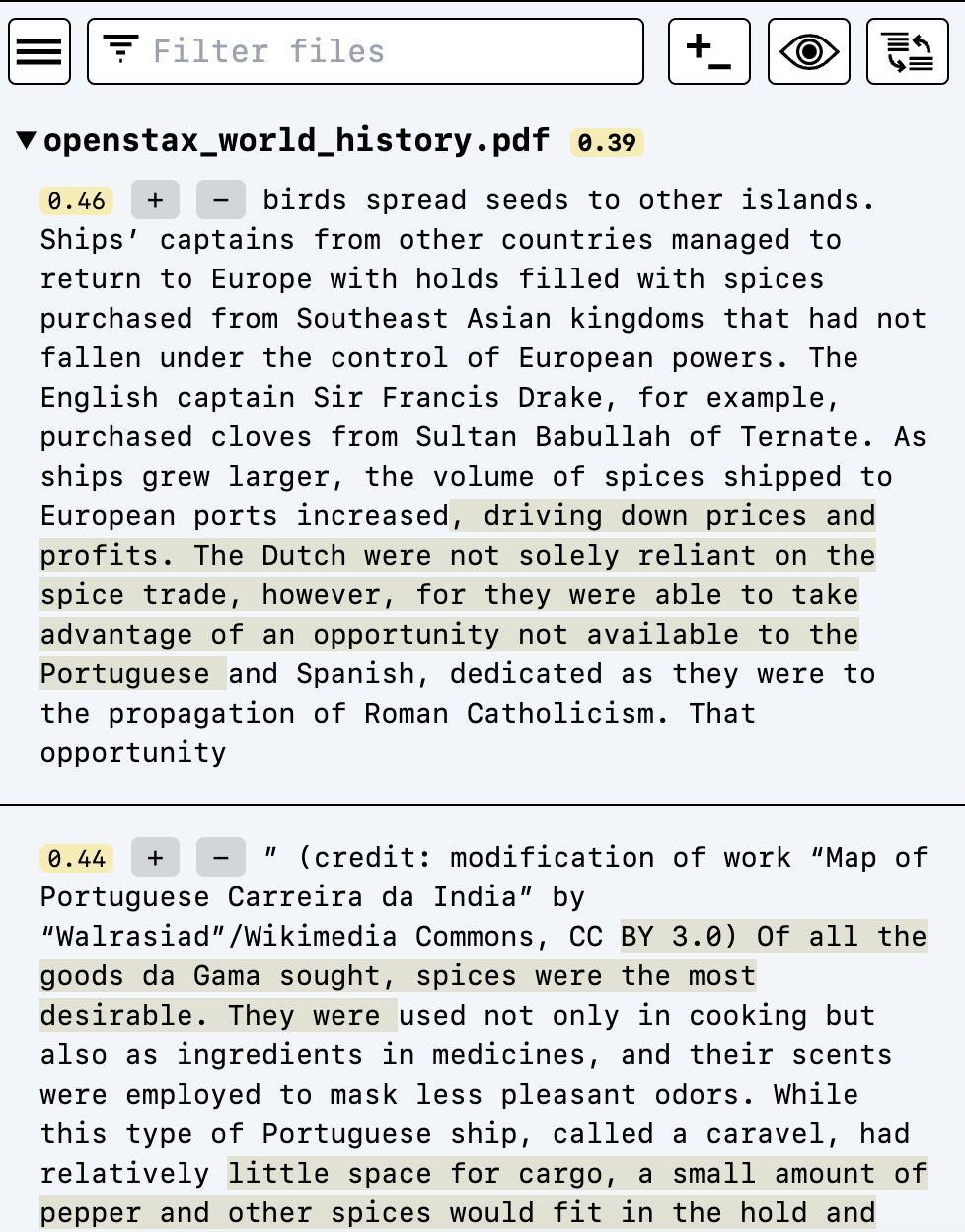
黄色分数显示0-1.00的相关性。0.50范围内的任何分数都表示强匹配。浅褐色高亮将在搜索结果上流动显示,解释与你的查询最相关的部分。
点击搜索结果的文本将导航到相关文档的相应部分。

点击与搜索结果相关的加号/减号按钮将正面/负面标记这些结果。重新运行查询将使这些额外的查询参数生效。
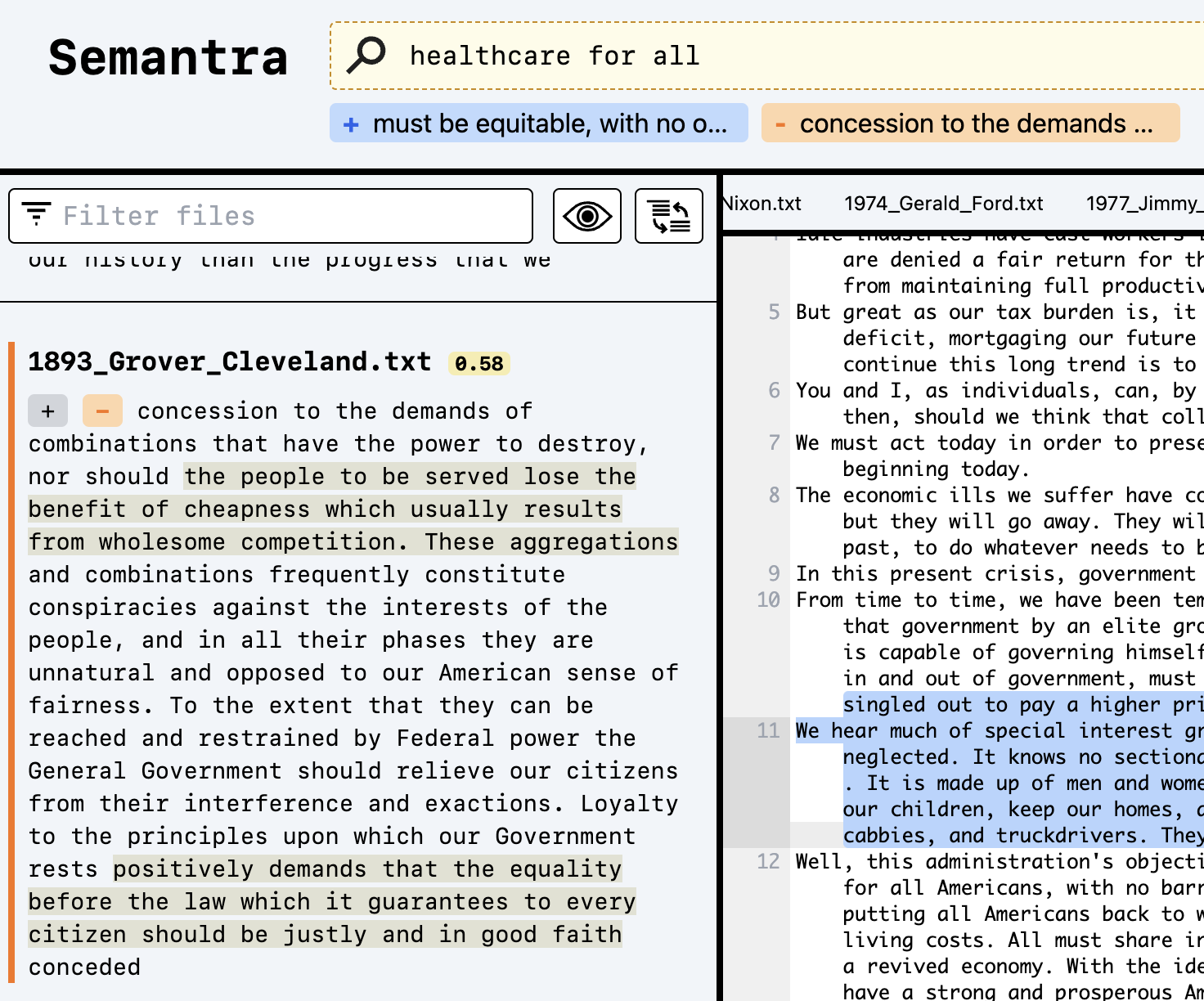
最后,可以在查询文本中使用加号/减号来添加和减去文本查询,以塑造精确的语义含义。

快速概念
使用语义搜索引擎与精确文本匹配算法有根本的不同。
首先,对于给定的查询,总是会有搜索结果,无论它多么不相关。分数可能非常低,但结果永远不会完全消失。这是因为使用查询算术的语义搜索通常会在非常微小的分数差异中揭示有用的结果。结果将始终按相关性排序,并且每个文档只显示前10个结果,因此较低分数的结果会自动被截断。 另一个区别是,如果你查询的内容直接出现在文档中,Semantra不一定会找到精确的文本匹配。从宏观层面来看,这是因为在不同的上下文中,单词可能有不同的含义,例如"leaves"这个词可以指树上的叶子,也可以指某人离开。Semantra使用的嵌入模型会将所有文本和你输入的查询转换成可以进行数学比较的长数字序列,在这个意义上,精确的子字符串匹配并不总是重要的。有关嵌入的更多信息,请参阅嵌入概念文档。
命令行参考
semantra [选项] [文件名]...
选项
--model [openai|minilm|mpnet|sgpt|sgpt-1.3B]:用于嵌入的预设模型。更多信息请参见模型指南(默认:mpnet)--transformer-model 文本:用于嵌入的自定义Huggingface transformers模型名称(应只指定--model和--transformer-model中的一个)。更多信息请参见模型指南--windows 文本:要提取的嵌入窗口。格式为"大小[_偏移=0][_回退=0]"的逗号分隔列表。一个大小为128、偏移为0、回退为16(128_0_16)的窗口将以128个部分重叠16个token的块嵌入文档。只有第一个窗口用于搜索。更多信息请参见窗口概念文档(默认:128_0_16)--encoding:用于读取文本文件的编码[默认:utf-8]--no-server:不启动UI服务器(仅处理)--port 整数:嵌入服务器使用的端口(默认:8080)--host 文本:嵌入服务器使用的主机(默认:127.0.0.1)--pool-size 整数:请求中要池化的最大嵌入token数--pool-count 整数:请求中要池化的最大嵌入数--doc-token-pre 文本:在transformer模型中每个文档前添加的token(默认:无)--doc-token-post 文本:在transformer模型中每个文档后添加的token(默认:无)--query-token-pre 文本:在transformer模型中每个查询前添加的token(默认:无)--query-token-post 文本:在transformer模型中每个查询后添加的token(默认:无)--num-results 整数:每个文件为查询检索的结果(邻居)数量(默认:10)--annoy:使用Annoy进行近似kNN查询(以轻微的准确性损失换取更快的查询速度);如果为false,则使用精确的穷举kNN(默认:True)--num-annoy-trees 整数:使用Annoy进行近似kNN时的树数量(默认:100)--svm:使用SVM而不是任何类型的kNN进行查询(较慢,且仅适用于对称模型)--svm-c 浮点数:SVM正则化参数;较高的值对错误预测的惩罚更重(默认:1.0)--explain-split-count 整数:用于解释查询的给定窗口的分割数量(默认:9)--explain-split-divide 整数:用于解释查询时将窗口大小除以的因子,以获得每个分割长度(默认:6)--num-explain-highlights 整数:用于解释查询时要突出显示的分割结果数量(默认:2)--force:即使有缓存也强制处理--silent:不打印进度信息--no-confirm:使用OpenAI处理时不显示成本并请求确认--version:打印版本并退出--list-models:列出预设模型并退出--show-semantra-dir:打印Semantra将用于存储处理文件的目录并退出--semantra-dir 路径:存储semantra文件的目录--help:显示此消息并退出
常见问题
它能使用ChatGPT吗?
不能,这是有意为之的。
Semantra不使用任何生成式模型,如ChatGPT。它仅用于语义查询文本,没有任何尝试解释、总结或综合结果的上层。生成式语言模型偶尔会产生表面上看似合理但最终不正确的信息,将验证的负担转嫁给用户。Semantra将原始资料视为唯一的真相来源,并努力展示基于更简单嵌入模型的人机交互搜索体验对用户更有用。
开发
Python应用程序位于src/semantra/semantra.py中,并作为标准Python命令行项目使用pyproject.toml进行管理。
本地Web应用程序使用Svelte编写,并作为标准npm应用程序进行管理。
要开发Web应用程序,请cd进入client目录,然后运行npm install。
要构建Web应用程序,运行npm run build。要在监视模式下构建Web应用程序并在有变更时重新构建,运行npm run build:watch。
贡献
该应用程序仍处于早期阶段,但欢迎贡献。如有任何错误或功能请求,请随时提交问题。











