
 访问官网
访问官网 Github
Github 论文
论文Kiwi : 智能韩语形态素分析器(Korean Intelligent Word Identifier)
x86_64:




其他:


Kiwi是一个追求高速和通用性能的韩语形态素分析器库。它作为开源项目公开,任何对韩语处理感兴趣的人都可以轻松使用。核心库是用C++实现的,正在准备跨多种编程语言使用的包装。
形态素分析基于世宗词性标签系统,模型训练采用了世宗计划语料库和所有人语料库。对于网络文本约87%,书写文本约94%的准确率可以分析韩语句子的形态素。此外,对于简单的拼写错误,模型可以自行纠正(0.13.0版本之后)。
由于还有很多不足之处,恳请开发者们多多关注和贡献。
特点
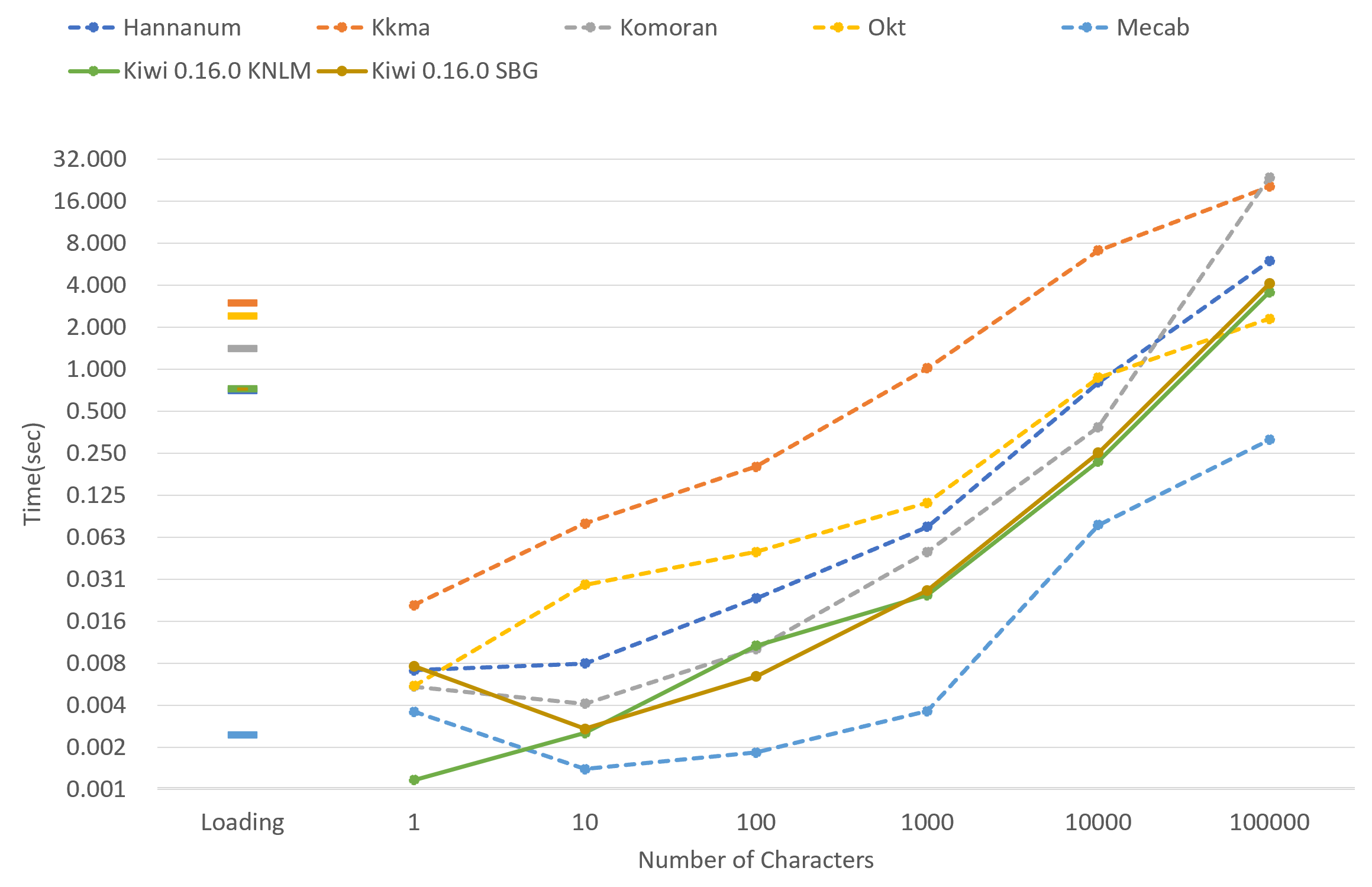
文本分析速度相比其他韩语形态素分析器相当快。(速度测试可以通过这段代码进行)
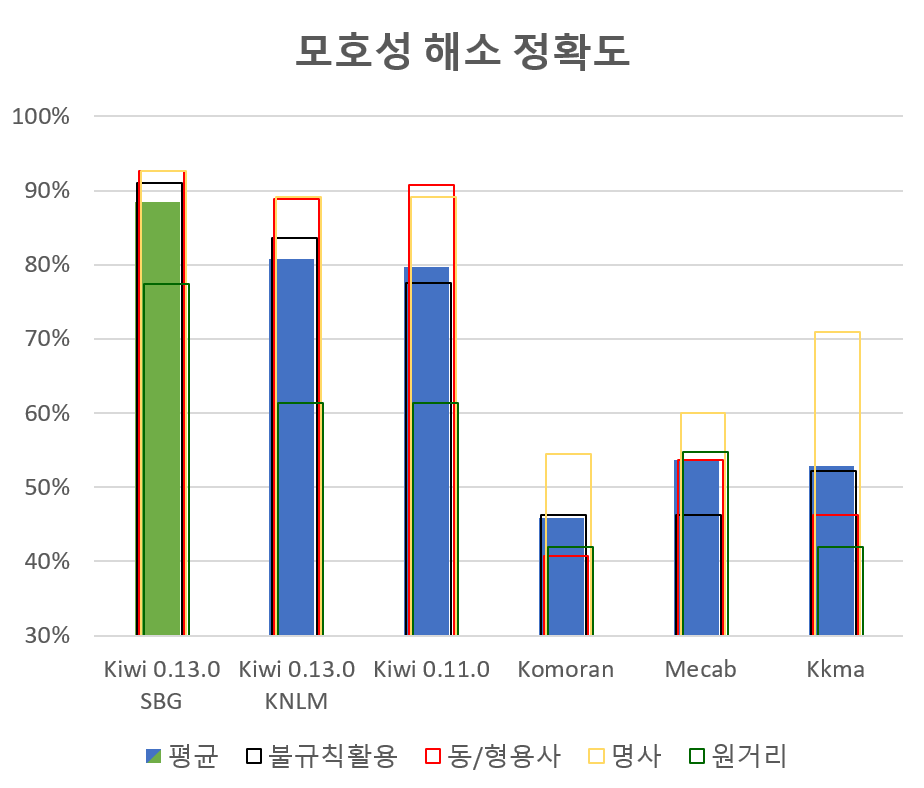
此外,自带轻量级语言模型,即使存在歧义的情况下也能相当准确地分析形态素。使用SBG模型时,消解性能显著提升。(消解性能评估可以在这个页面进行)
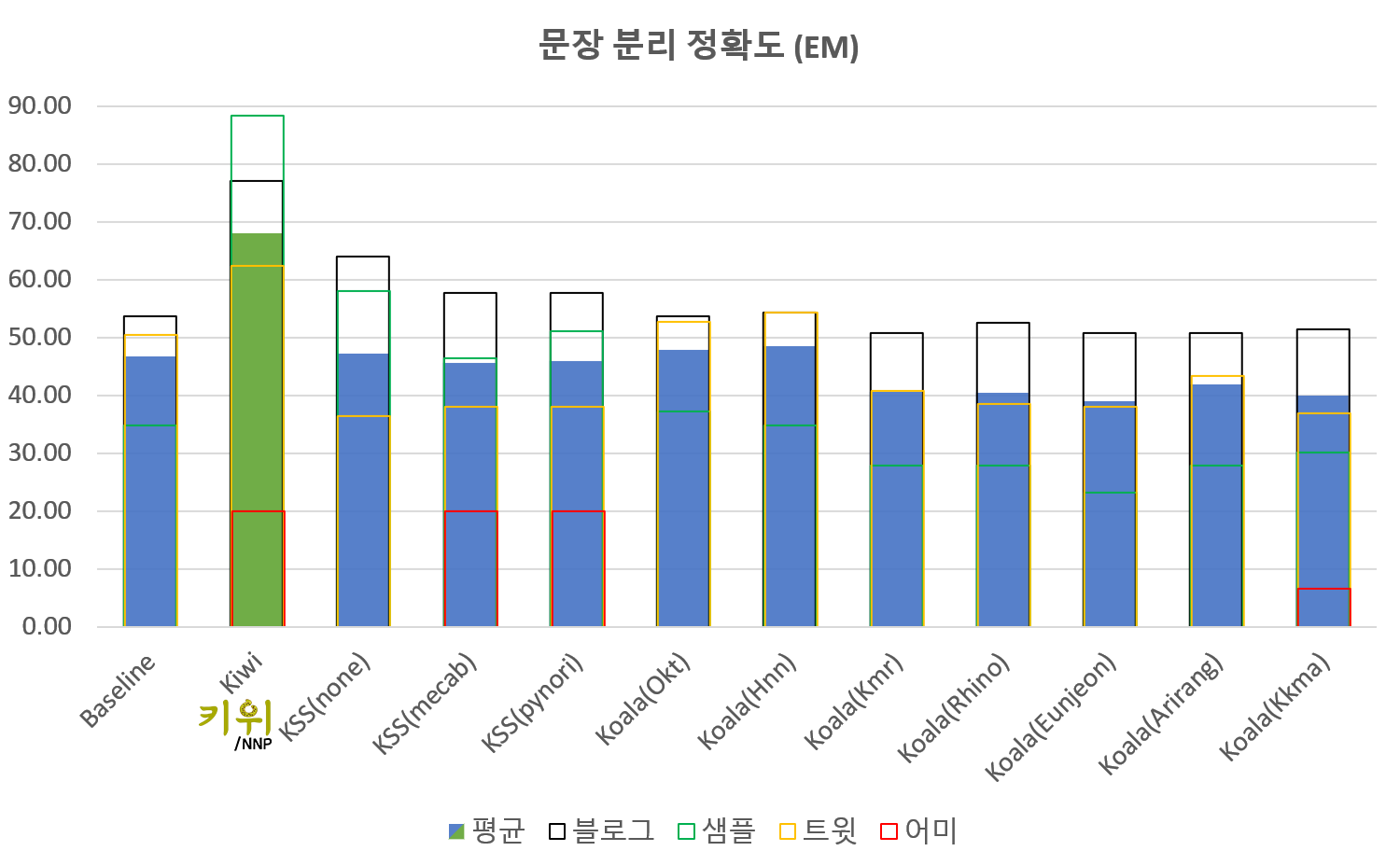
提供了包括句子分离功能在内的多种便捷功能。(句子分离性能评估可以在这个页面进行)
库层面支持多线程,因此需要分析大量文本时可以利用多核进行快速分析。此外,根据不同系统提供了小型/中型/大型模型供选择。
安装
C++
下载已编译的二进制文件
可以在https://github.com/bab2min/Kiwi/releases 下载编译好的Windows,Linux,macOS版本的库文件和模型文件。
Windows
使用Visual Studio 2019及以上版本运行Kiwi.sln文件进行编译。
Linux
在克隆这个仓库后,使用cmake>=3.12进行编译。
由于模型文件容量较大,通过Git LFS进行共享。因此,在git clone之前,请确保已安装Git LFS。
gcc >= 5.0或其他兼容c++11的编译环境
$ git clone https://github.com/bab2min/Kiwi
$ cd Kiwi
$ git lfs pull
$ git submodule sync
$ git submodule update --init --recursive
$ mkdir build && cd build
$ cmake -DCMAKE_BUILD_TYPE=Release ../
$ make
$ make install
$ ldconfig
gcc >= 4.8, < 5.0
在像Centos5只支持gcc 4.8的环境下,需要将googletest的版本降到1.8.x才能编译。
$ git clone https://github.com/bab2min/Kiwi
$ cd Kiwi
$ git lfs pull
$ git submodule sync
$ git submodule update --init --recursive
$ cd third_party/googletest && git checkout v1.8.x && cd ../../
$ mkdir build && cd build
$ cmake -DCMAKE_BUILD_TYPE=Release ../
$ make
$ make install
$ ldconfig
为了确认安装是否顺利,可以运行kiwi-evaluator。
$ ./kiwi-evaluator --model ../ModelGenerator ../eval_data/* --sbg
Loading Time : 981.745 ms
ArchType : avx2
LM Size : 34.1853 MB
Mem Usage : 278.129 MB
Test file: eval_data/web.txt
0.862114, 0.852863
Total (158 lines) Time : 301.702 ms
Time per Line : 1.9095 ms
================
Test file: eval_data/written.txt
0.942892, 0.943506
Total (33 lines) Time : 62.3999 ms
Time per Line : 1.89091 ms
================
Test file: eval_data/web_with_typos.txt
0.754417, 0.720886
Total (97 lines) Time : 99.7661 ms
Time per Line : 1.02852 ms
================
================
Avg Score
0.853141, 0.839085
================
为了确认0.13.0版本之后新增的拼写错误纠正功能是否正常工作,可以按以下方式运行。
$ ./kiwi-evaluator --model ../ModelGenerator ../eval_data/* --sbg --typo 6
Loading Time : 9414.45 ms
ArchType : avx2
LM Size : 34.1853 MB
Mem Usage : 693.945 MB
Test file: eval_data/web.txt
0.86321, 0.85566
Total (158 lines) Time : 432.236 ms
Time per Line : 2.73567 ms
================
Test file: eval_data/written.txt
0.941712, 0.942217
Total (33 lines) Time : 95.3079 ms
Time per Line : 2.88812 ms
================
Test file: eval_data/web_with_typos.txt
0.869582, 0.865393
Total (97 lines) Time : 169.416 ms
Time per Line : 1.74656 ms
================
================
Avg Score
0.891501, 0.887757
================
C API
请参考include/kiwi/capi.h。
下载已编译的二进制文件
可以在https://github.com/bab2min/Kiwi/releases 下载编译好的Windows,Linux,macOS版本的库文件和模型文件。
C# 封装
https://github.com/bab2min/kiwi-gui
Python3 封装
同时有提供Python3的API,名为Kiwipiepy。关于它的更多信息,请参考https://github.com/bab2min/kiwipiepy。
Java 封装
在Java 1.8及以上版本可用的KiwiJava作为Java绑定提供。关于它的更多信息,请参考bindings/java。
R 包装器
GO 包装器
Web Assembly (Javascript/Typescript)
RicBent贡献的Web Assembly绑定。详情请参考bindings/wasm。
应用程序
Kiwi也以基于C#的GUI形式提供。如果需要使用形态素分析器,但没有编程知识,可以使用此程序。该程序仅在Windows上运行。可以从https://github.com/bab2min/kiwi-gui 下载。
更新日志
有关更新日志,请参考发布说明。
词性标签
我们以世宗词性标签为基础,并添加/修改了一些词性标签。
| 大类 | 标签 | 说明 |
|---|---|---|
| 名词 (N) | NNG | 普通名词 |
| NNP | 专有名词 | |
| NNB | 依存名词 | |
| NR | 数词 | |
| NP | 代词 | |
| 动词 (V) | VV | 动词 |
| VA | 形容词 | |
| VX | 辅助动词 | |
| VCP | 肯定指示词(是) | |
| VCN | 否定指示词(不是) | |
| 冠形词 | MM | 冠形词 |
| 副词 (MA) | MAG | 普通副词 |
| MAJ | 连接副词 | |
| 感叹词 | IC | 感叹词 |
| 助词 (J) | JKS | 主格助词 |
| JKC | 补格助词 | |
| JKG | 冠形格助词 | |
| JKO | 目的格助词 | |
| JKB | 副词格助词 | |
| JKV | 呼格助词 | |
| JKQ | 引用格助词 | |
| JX | 补助助词 | |
| JC | 连接助词 | |
| 词尾 (E) | EP | 先语末尾 |
| EF | 终结尾 | |
| EC | 连接尾 | |
| ETN | 名词形转换尾 | |
| ETM | 冠形形转换尾 | |
| 前缀 | XPN | 名词前缀 |
| 后缀 (XS) | XSN | 名词派生后缀 |
| XSV | 动词派生后缀 | |
| XSA | 形容词派生后缀 | |
| XSM | 副词派生后缀* | |
| 词根 | XR | 词根 |
| 符号、外语、特殊字符 (S) | SF | 终止符号(. ! ?) |
| SP | 分隔符号(, / : ;) | |
| SS | 引号及括号(' " ( ) [ ] < > { } ― ‘ ’ “ ” ≪ ≫ 等) | |
| SSO | SS中的左引号* | |
| SSC | SS中的右引号* | |
| SE | 省略号(…) | |
| SO | 连接符号(- ~) | |
| SW | 其他特殊字符 | |
| SL | 字母(A-Z a-z) | |
| SH | 汉字 | |
| SN | 数字(0-9) | |
| SB | 有顺序的项目符号(例如:가. 나. 1. 2. 가) 나) 等)* | |
| 无法分析 | UN | 无法分析* |
| 网页 (W) | W_URL | URL 地址* |
| W_EMAIL | 电子邮件地址* | |
| W_HASHTAG | 标签(#abcd)* | |
| W_MENTION | @提及(@abcd)* | |
| W_SERIAL | 序列号(电话号码,银行账号,IP地址等)* | |
| W_EMOJI | 表情符号* | |
| 其他 | Z_CODA | 附加尾音* |
| USER0~4 | 用户自定义标签* |
* 与世宗词性标签不同的是,我们采用了独特的标签。
自0.12.0版本起,VV、VA、VX、XSA标签后可附加表示是否具有不规则变形的后缀-R与-I。其中-R表示规则变形,-I表示不规则变形。
性能指标
| 模型(文件大小) | 网页 | 精炼网页 | 新闻 | 文学 |
|---|---|---|---|---|
| 小型(15.9MB) | 86.85 | 93.58 | 89.73 | 95.19 |
| 中型(39.9MB) | 87.09 | 94.12 | 91.23 | 96.73 |
| 大型(90.4MB) | 86.99 | 93.47 | 92.37 | 97.68 |
结果示例
프랑스의 세계적인 의상 디자이너 엠마누엘 웅가로가 실내 장식용 직물 디자이너로 나섰다.
(正解) 프랑스/NNP 의/JKG 세계/NNG 적/XSN 이/VCP ㄴ/ETM 의상/NNG 디자이너/NNG 엠마누엘/NNP 웅가로/NNP 가/JKS 실내/NNG 장식/NNG 용/XSN 직물/NNG 디자이너/NNG 로/JKB 나서/VV 었/EP 다/EF ./SF
(Kiwi) 프랑스/NNP 의/JKG 세계/NNG 적/XSN 이/VCP ᆫ/ETM 의상/NNG 디자이너/NNG 엠마누/NNP 에/JKB ᆯ/JKO 웅가로/NNP 가/JKS 실내/NNG 장식/NNG 용/XSN 직물/NNG 디자이너/NNG 로/JKB 나서/VV 었/EP 다/EF ./SF
둥글둥글한 돌은 아무리 굴러도 흔적이 남지 않습니다. (정답) 둥글둥글/MAG 하/XSA ㄴ/ETM 돌/NNG 은/JX 아무리/MAG 구르/VV 어도/EC 흔적/NNG 이/JKS 남/VV 지/EC 않/VX 습니다/EF ./SF (Kiwi) 둥글둥글/MAG 하/XSA ᆫ/ETM 돌/NNG 은/JX 아무리/MAG 구르/VV 어도/EC 흔적/NNG 이/JKS 남/VV 지/EC 않/VX 습니다/EF ./SF
하늘을 훨훨 나는 새처럼 (정답) 하늘/NNG 을/JKO 훨훨/MAG 날/VV 는/ETM 새/NNG 처럼/JKB (Kiwi) 하늘/NNG 을/JKO 훨훨/MAG 날/VV 는/ETM 새/NNG 처럼/JKB
아버지가방에들어가신다 (정답) 아버지/NNG 가/JKS 방/NNG 에/JKB 들어가/VV 시/EP ㄴ다/EF (Kiwi) 아버지/NNG 가/JKS 방/NNG 에/JKB 들어가/VV 시/EP ᆫ다/EC
## 데모
https://lab.bab2min.pe.kr/kiwi 에서 데모를 실행해 볼 수 있습니다.
## 라이센스
Kiwi는 LGPL v3 라이센스로 배포됩니다.
이메일: bab2min@gmail.com
블로그: http://bab2min.tistory.com/560
## 기여하기
자세한 내용은 [CONTRIBUTING.md](CONTRIBUTING.md) 에서 확인해주세요.
## 인용하기
DOI 혹은 아래의 BibTex를 이용해 인용해주세요.
[](https://doi.org/10.23287/KJDH.2024.1.1.6)
```text
@article{43508,
title = {Kiwi: 통계적 언어 모델과 Skip-Bigram을 이용한 한국어 형태소 분석기 구현},
journal = {디지털인문학},
volume = {1},
number = {1},
page = {109-136},
year = {2024},
issn = {3058-311X},
doi = {https://doi.org/10.23287/KJDH.2024.1.1.6},
url = {https://kjdh/v.1/1/109/43508},
author = {민철 이},
keywords = {한국어, 자연어처리, 형태소 분석기, 모호성 해소, 언어 모델},
abstract = {한국어 형태소 분석 시 모델이 마주하는 어려움 중 하나는 모호성이다. 이는 한국어에서 기저형이 전혀 다른 형태소 조합이 동일한 표면형을 가질 수 있기 때문에 발생하며 이를 바르게 분석하기 위해서는 문맥을 고려하는 능력이 모델에게 필수적이다. 형태소 분석기 Kiwi는 이를 해결하기 위해 근거리 맥락을 고려하는 통계적 언어 모델과 원거리 맥락을 고려하는 Skip-Bigram 모델을 조합하는 방식을 제안한다. 제안된 방식은 모호성 해소에서 평균 정확도 86.7%를 달성하여 평균 50~70%에 머무르는 기존의 오픈소스 형태소 분석기, 특히 딥러닝 기반의 분석기들보다도 앞서는 결과를 보였다. 또한 최적화된 경량 모델을 사용한 덕분에 타 분석기보다 빠른 속도를 보여 대량의 텍스트를 분석하는 데에도 유용하게 쓰일 수 있다. 오픈소스로 공개된 Kiwi는 전술한 특징들 덕분에 텍스트 마이닝, 자연어처리, 인문학 등 다양한 분야에서 널리 사용되고 있다. 본 연구는 형태소 분석의 정확도와 효율성을 모두 개선했으나, 미등록어 처리와 한국어 방언 분석 등의 과제에서 한계를 보여 이에 대한 추가 보완이 필요하다.},
}
@article{43508,
title = {Kiwi: Developing a Korean Morphological Analyzer Based on Statistical Language Models and Skip-Bigram},
journal = {Korean Journal of Digital Humanities},
volume = {1},
number = {1},
page = {109-136},
year = {2024},
issn = {3058-311X},
doi = {https://doi.org/10.23287/KJDH.2024.1.1.6},
url = {https://kjdh/v.1/1/109/43508},
author = {Min-chul Lee},
keywords = {한국어, 자연어처리, 형태소 분석기, 모호성 해소, 언어 모델},
abstract = {One of the challenges faced by models in Korean morphological analysis is ambiguity. This arises because different combinations of morphemes with completely different base forms can share the same surface form in Korean, necessitating the model's ability to consider context for accurate analysis. The morphological analyzer Kiwi addresses this issue by proposing a combination of a statistical language model that considers local context and a Skip-Bigram model that considers global context. This proposed method achieved an average accuracy of 86.7% in resolving ambiguities, outperforming existing open-source morphological analyzers, particularly deep learning-based ones, which typically achieve between 50-70%. Additionally, thanks to the optimized lightweight model, Kiwi shows faster speeds compared to other analyzers, making it useful for analyzing large volumes of text. Kiwi, released as open source, is widely used in various fields such as text mining, natural language processing, and the humanities due to these features. Although this study improved both the accuracy and efficiency of morphological analysis, it shows limitations in handling out-of-vocabulary problem and analyzing Korean dialects, necessitating further improvements in these areas.},
}











