
 访问官网
访问官网 Github
Github 文档
文档 论文
论文嘿,Jetson!
自动语音识别推理
作者:Brice Walker
本项目在 Keras/Tensorflow 中构建了一个可扩展的基于注意力机制的语音识别平台,用于在 Nvidia Jetson 嵌入式计算平台上进行边缘 AI 推理。这个自动语音识别的实际应用受到了我之前在心理健康领域工作的启发。该项目开启了构建实时治疗干预推理和反馈平台的旅程。最终目标是开发一个能够为治疗师提供实时干预效果反馈的工具,但设备端语音识别在移动设备、机器人或其他不适合使用基于云的深度学习的领域也有许多应用。本项目重点是应用数据科学,而非学术研究。
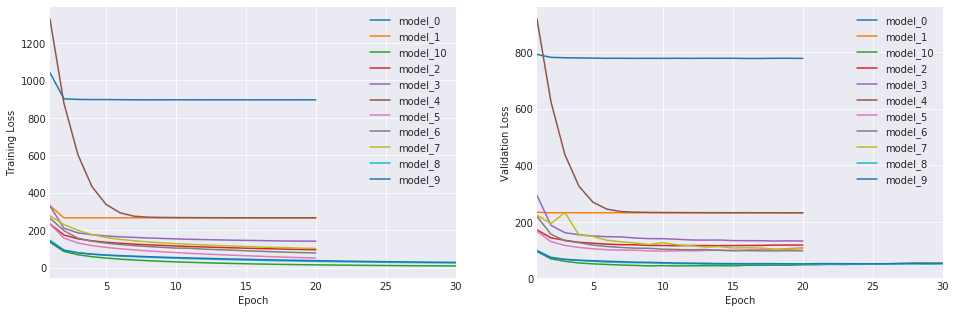
最终的生产模型由一个深度神经网络组成,包含 3 层扩张卷积神经元、7 层双向循环神经元(GRU 单元)、1 层注意力层和 2 层时间分布式全连接神经元。该模型使用了 CTC 损失函数、Adam 优化器、批量归一化、扩张卷积、循环dropout、双向层和基于注意力的机制。模型在 Nvidia GTX1070(8G) GPU 上训练了 30 个 epoch,总训练时间约为 6.5 天。模型在测试集上的预测与真实转录的整体余弦相似度约为 78%(验证集上为 80%),而测试集上的整体词错误率约为 18%(验证集上为 16%)。
本项目还包括一个 Flask Web 服务器,用于使用 REST API 部署应用语音推理引擎。
大纲
入门
我提供了使用 Ubuntu 18.04 LTS 下载项目、准备数据、训练模型和部署 Web 应用的完整说明。这些说明尚未在其他平台上测试。
下载代码仓库
你需要使用 git 克隆仓库(你还需要 git-lfs),运行以下命令:
sudo apt-get update
sudo apt-get install git
sudo apt-get install git-lfs
git clone https://github.com/bricewalker/Hey-Jetson.git
准备数据集
从 LibriSpeech ASR 语料库 下载数据集。
确保下载 train-clean-100、train-clean-360 和 train-other-500 数据集,并将它们合并到 LibriSpeech 目录下的一个名为 'train' 的文件夹中。你还需要将 test-clean/test-other 数据集合并到一个名为 'test' 的文件夹中,以及将 dev-clean/dev-other 数据集合并到一个名为 'dev' 的文件夹中。
使用从 Baidu Research 的 Deep Speech GitHub 仓库 借鉴的一组脚本来准备音频文件。
flac_to_wav.sh 将所有 flac 文件转换为 .wav 格式,create_desc_json.py 将为每个数据集创建一个语料库:这将是一个 JSON 格式的字典,包括文件路径、文件长度和真实标签。
要运行这个脚本,你需要获取 ffmpeg/libav 包。 使用以下命令:
sudo apt-get install ffmpeg
或者:你可以从源代码下载并构建。
从包含数据集的目录运行 flac_to_wav.sh。根据你的机器性能,这可能需要一段时间:
flac_to_wav.sh
现在导航到你的代码仓库并运行 create_desc_json.py,指定数据集的路径和语料库文件的名称,命令应该如下所示:
python create_desc_json.py /home/brice/LibriSpeech/train train_corpus.json
python create_desc_json.py /home/brice/LibriSpeech/dev valid_corpus.json
python create_desc_json.py /home/brice/LibriSpeech/test test_corpus.json
准备开发环境
建议在训练服务器上使用 Python 3.6+ 的 conda 环境。
你可以从 anaconda.com 下载 anaconda 或从 conda.io 下载 miniconda。
要准备开发环境,首先在终端中导航到仓库中的 conda 文件夹,然后使用提供的 conda 环境文件创建环境:
cd conda
conda env create -f environment.yml
注意:这依赖于一些预构建的conda包,用于SoundFile和python_speech_features。你可能会遇到这些包的问题,所以我提供了conda build的配方,用于在下载预编译包出现问题时构建包。Soundfile依赖于libsndfile,这可能会给你带来麻烦,所以我包含了一个有时在Windows上安装失败的dll文件。你可能需要在基于linux/unix的系统上手动安装libsndfile。
然后使用以下命令激活环境:
conda activate heyjetson
如果你更喜欢使用pip来安装和管理依赖项,你可以创建一个虚拟环境并使用提供的requirements文件安装依赖项。 Linux/Unix系统:
python -m venv venv
source venv/bin/activate
pip install -r server_requirements.txt
或在Windows上:
python -m venv venv
venv/scripts/activate.bat
pip install -r server_requirements.txt
注意:为了利用Tensorflow/Keras内的GPU计算能力,你需要安装所需的Nvidia依赖项,CUDA 9.0和cuDNN 7。
训练模型
现在你可以运行train_model.py脚本来训练完整的RNN:
python train_model.py
或者,你可以在Jupyter中运行提供的notebook,以便详细了解建模过程并深入探索自动语音识别。
准备基于Jetson的生产服务器进行部署
为了准备Jetson部署推理引擎,你需要用最新版本的L4T刷写它。建议你通过在Ubuntu服务器上下载并安装JetPack 4.2来完成此操作,然后按照附带的说明刷写Jetson。你需要确保选择预安装CUDA 10.0和cuDNN 7.6.0到设备上的选项。
然后你需要安装pip和python-dev:
sudo apt-get install python3-pip python3-dev
建议你在虚拟环境中使用Python 3.5+作为推理引擎。要这样做,导航到项目目录并运行:
python -m venv venv
然后激活环境:
source venv/bin/activate
然后你可以安装所需的依赖项:
pip install -r jetson_requirements.txt
注意:你可能需要使用apt-get安装一些库,命令类似这样:
sudo apt-get install python3-<库名>
你需要在TX2上从源代码构建TensorFlow:
要从源代码构建TensorFlow,请按照JetsonHacks的说明进行操作。
你可能可以从Nvidia的Jason提供的wheel文件安装TensorFlow。
运行推理服务器
首先导航到项目仓库并将服务器路径导出为环境变量:
echo "export FLASK_APP=inference.py" >> ~/.profile
最后,使用以下命令初始化Web应用:
flask run
现在你可以在浏览器中访问并测试推理引擎,地址为http://127.0.0.1:5000或http://localhost:5000。
发布Web应用
不建议在生产环境中部署Flask服务器。建议使用更强大的服务器,如gunicorn。然后你可以使用反向代理,如NGINX,将本地Web服务器发布到互联网。你可以使用Supervisor等程序来自动化这个过程。
要这样做,请运行:
sudo apt-get -y update
sudo apt-get -y install supervisor nginx
你应该通过运行以下命令测试gunicorn Web服务器:
gunicorn -b localhost:8000 -w 1 inference:app
这应该会启动1个Web服务器实例(不允许多人同时访问网站)。你应该能够在http://127.0.0.1:8000或http://localhost:8000访问服务器。
如果这正常工作,你可以设置Supervisor来监控服务器并确保它始终运行,方法是创建一个配置文件:
sudo gedit /etc/supervisor/conf.d/inference.conf
文件内容应该类似这样:
[program:inference]
command=/home/brice/Hey-Jetson/venv/bin/gunicorn -b localhost:8000 -w 1 inference:app
directory=/home/brice/Hey-Jetson
user=ubuntu
autostart=true
autorestart=true
stopasgroup=true
killasgroup=true
注意:在这里,我创建了一个单独的用户账户来运行服务器,以防止外部人员获取对本地设备的访问权限。这是通过以下命令完成的:
sudo adduser --gecos "" ubuntu
sudo usermod -aG sudo ubuntu
现在,你需要使用以下命令重新加载supervisor服务:
sudo supervisorctl reload
你的服务器现在应该正在运行并被监控。
要设置NGINX反向代理,首先你需要使用以下命令创建临时的自签名SSL证书:
mkdir certs
openssl req -new -newkey rsa:4096 -days 365 -nodes -x509 \
-keyout certs/key.pem -out certs/cert.pem
现在,你可以使用这些命令为NGINX创建配置文件:
sudo rm /etc/nginx/sites-enabled/default
sudo gedit /etc/nginx/sites-enabled/inference
配置文件的内容应该如下所示:
server {
# 监听80端口(http)
listen 80;
server_name heyjetson.com;
location / {
# 将任何请求重定向到相同URL的https版本
return 301 https://$host$request_uri;
}
}
server {
# 监听443端口(https)
listen 443 ssl;
server_name heyjetson.com;
# 自签名SSL证书的位置
ssl_certificate /home/brice/Hey-Jetson/certs/cert.pem;
ssl_certificate_key /home/brice/Hey-Jetson/certs/key.pem;
# 将访问和错误日志写入/var/log
access_log /var/log/inference_access.log;
error_log /var/log/inference_error.log;
location / {
# 将应用请求转发到gunicorn服务器
proxy_pass http://localhost:8000;
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
location /static {
# 直接处理静态文件,不转发到应用
alias /home/brice/Hey-Jetson/app/static;
expires 30d;
}
}
保存文件后,你可以使用以下命令重新加载NGINX服务器:
sudo service nginx reload
在将你的域名指向本地服务器之前,你会想要获取一个正式的SSL证书,这可以通过certbot完成。可以使用以下命令:
sudo apt-get update
sudo apt-get install software-properties-common
sudo add-apt-repository ppa:certbot/certbot
sudo apt-get update
sudo apt-get install python-certbot-nginx
sudo certbot --nginx
或者,你可以使用我提供的便捷脚本来运行服务器。你需要更改脚本指向的目录,然后使用以下命令运行:
./server.sh
你的网络服务器现在应该已经上线了。
介绍
这个端到端的机器学习项目探索了为机器学习算法准备音频文件的方法,然后构建了一系列越来越复杂的序列到序列神经网络,用于字符级语音序列模型。对于这个项目,我选择了循环神经网络,因为它们允许我们利用深度神经网络的力量来解决时间序列问题,并且与其他模型相比,可以在GPU上快速训练。我选择字符级语音建模是因为它提供了更准确的语言描述,并且可以构建一个能够捕捉人与人之间深度个人对话中细微差别的系统。此外,这个项目还探索了模型性能的衡量方法,并基于训练好的模型进行预测。最后,我为一个网络应用构建了一个推理引擎,用于实时语音预测。
自动语音识别
语音识别模型基于一个称为语音识别基本方程的统计优化问题。给定一系列观察结果,我们寻找最可能的序列。因此,使用贝叶斯理论,我们寻找能够最大化给定观察结果下单词或字符后验概率的单词或字符序列。语音识别问题就是在这个模型中搜索最佳序列。
字符级语音识别可以分为两部分:声学模型,描述给定字符序列C的声学观察O的分布;以及仅基于字符序列的语言模型,它为每个可能的字符序列分配一个概率。这个序列到序列模型将声学模型和语言模型结合到一个神经网络中,尽管如果你想加快训练速度并提高性能,可以从kaldi获取预训练的语言模型。
问题陈述
我的目标是使用TensorFlow中的循环神经网络构建一个字符级ASR系统,该系统可以在基于Nvidia Pascal/Volta的GPU上运行推理,词错率低于20%。
工具
本项目使用的工具包括:
- Ubuntu
- Python
- Anaconda
- HTML
- CSS
- JavaScript
- VS Code
- Jupyter Notebook
- Keras
- TensorFlow
- Sci-kit Learn
- matplotlib
- seaborn
- Azure Cognitive Services Speech API
- gunicorn
- CUDA
- cuDNN
- NGINX
- Supervisor
- Certbot
数据集
主要使用的数据集是LibriSpeech ASR语料库,其中包含1000小时的录音。用于训练模型的是该数据集中960小时的10-15秒音频文件子集。该数据集由LibriVox项目中朗读有声书的16kHz英语口语音频文件组成。音频文件长度在2-15秒之间,均为16kHz采样率的英语口语,源自LibriVox项目的有声书朗读。这些音频文件被转换为单声道WAV/WAVE文件(.wav扩展名),比特率为64k,采样率为16kHz。它们以PCM格式编码,然后被剪切/填充至统一的10秒长度。对文本转录的预处理技术包括去除除撇号外的所有标点符号,并将所有字符转换为小写。关于处理此类数据的一些困难的概述可以在这里找到。
特征提取/工程
语音识别有三种主要的特征提取方法。这包括使用原始音频形式、声谱图和MFCC。在这个项目中,我创建了一个字符级序列模型。这使我能够在有限词汇的数据集上训练模型,从而更好地泛化到更独特/罕见的单词。缺点是这些模型计算成本更高,更难解释/理解,而且由于序列可能很长,它们更容易受到梯度消失或爆炸问题的影响。
本项目探索了以下声学建模的特征提取方法:
原始音频波形
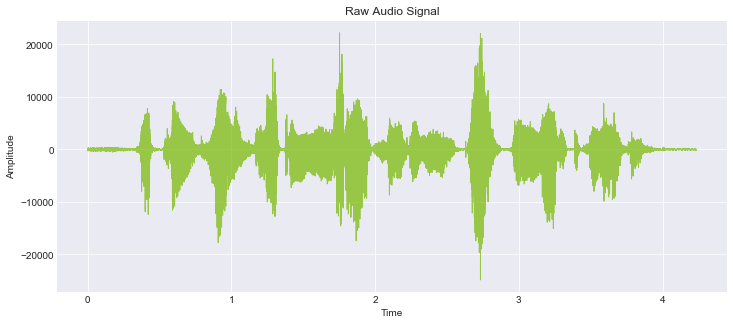
这种方法使用音频文件的原始波形,是一个一维振幅向量,其中X = [x1, x2, x3...]。
声谱图
这将原始音频波形转换为二维张量,第一维对应时间(横轴),第二维对应频率(纵轴)而不是振幅。在这个转换过程中,我们会损失一些信息,因为我们取FFT功率的对数。这给我们161个特征,因此每个特征对应99-100 Hz之间的某个值。这可以写成log |FFT(X)|^2。
MFCC
与声谱图类似,这将音频波形转换为二维数组。它通过映射信号傅里叶变换的功率,然后对对数梅尔功率进行离散余弦变换来实现。与声谱图相比,这产生了一个维度减少的二维数组,有效地实现了声谱图的压缩并加快了训练速度,因为我们最终得到13个特征。
循环神经网络
对于这个项目,选择的架构是(循环)深度神经网络(RNN),因为它易于实现且可扩展性好。从本质上讲,这是一个机器翻译问题,因此编码器-解码器模型是一个合适的框架选择。循环神经元类似于前馈神经元,但它们还有向后指的连接。在每个时间步骤,每个神经元接收输入以及其自身在上一时间步骤的输出。每个神经元有两组权重,一组用于输入,另一组用于上一时间步骤的输出。每一层接收向量作为输入并输出一些向量。这个模型通过计算每个时间步骤t的前向传播,然后通过每个时间步骤进行反向传播来工作。在每个时间步骤,假设说话者已经说出了29个可能字符中的1个(26个字母,1个空格字符,1个撇号,以及1个用于填充短文件的空白/空字符,因为输入长度会有所不同)。该模型在每个时间步骤的输出将是每个可能字符的概率列表。
模型架构
Hey, Jetson!由声学模型和语言模型组成。声学模型对一段时间内的声学模型标签序列进行评分,而语言模型对字符序列进行评分。解码图然后将有效的声学标签序列映射到相应的字符序列。语音识别是通过解码图的路径搜索算法,其中路径的得分是解码图给出的得分和声学模型给出的得分之和。简而言之,语音识别是寻找同时最大化语言和声学模型得分的字符序列的过程。该模型架构松散地基于百度的Deep Speech 2项目,包括1层用于早期模式检测的卷积神经元,2层扩张卷积,7层双向GRU单元,以及2层时间分布式密集神经元。
CNN
本项目中的深度神经网络探索了使用由256个神经元组成的卷积神经网络来进行早期模式检测。初始卷积神经元层为循环网络进行特征提取。
扩张卷积
该模型还使用了扩张CNN层。扩张在CNN的卷积核中引入了间隔,使得感受野必须围绕区域而不是简单地以系统方式滑过窗口。这意味着卷积层可以捕捉到它所观察对象的全局上下文,同时仍然只有与标准形式相同数量的权重/输入。
批量归一化
Hey, Jetson!还使用了批量归一化,它将各层的激活值归一化为均值接近0、标准差接近1。这减少了梯度扩张并防止网络过拟合。
LSTM/GRU单元
我的RNN探索了使用长短期记忆单元和门控循环单元的层。LSTM包括遗忘门和输出门,通过允许单独控制遗忘内容和传递到下一个隐藏层的内容,从而对单元的记忆有更多控制。GRU是一种简化的长短期记忆循环神经元,参数比典型的LSTM少。它们通过单一的记忆更新门工作,以较少的计算成本提供了与传统LSTM相近的大部分性能。
双向层
本项目探索了将两个相反方向的隐藏层连接到同一输出,使其未来的输入信息可从当前状态获取。简而言之,这创建了两层神经元:一层沿时间正向遍历序列,另一层沿时间反向遍历。这使得输出层能够获取过去和未来状态的信息,意味着它将了解当前语音前后的字母。这可以带来性能的显著提升,但代价是增加了延迟。
循环丢弃
该模型还采用了随机丢弃单元的方法来防止模型过拟合。
注意力机制
模型的解码器部分包括在每个时间步"关注"音频剪辑不同部分的能力。这让模型能够根据输入和目前预测的输出来学习应该关注什么。注意力机制允许网络通过访问其内部记忆(即编码器的隐藏状态,也就是RNN层)来回顾输入序列。
时间分布密集层
ASR模型探索了在输入序列的每个时间片段上添加普通密集神经元层。
损失函数
我使用的损失函数是连接主义时序分类(CTC)的自定义实现,这是顺序目标函数的一种特殊情况,它解决了交叉熵中强制模型将输入数据的每一帧链接到标签的部分建模负担。CTC的标签集在其字母表中包含一个"空白"符号,因此如果数据帧不包含任何语音,CTC系统可以输出"空白",表示没有足够的信息来分类输出。这还有额外的好处,允许我们有不同长度的输入/输出,因为短文件可以用"空白"字符填充。该函数只观察路径上的标签序列,忽略标签与声学数据的对齐。
性能
语言建模是语音识别系统的一个组成部分,用于估计口语声音的先验概率,是系统对可能出现的字符序列的认知。该系统使用基于类的语言模型,这允许它通过语音识别器(系统的第一部分)的词汇表来缩小搜索范围,因为它很少会看到像"狗吃了沙子水"这样的句子,所以它会假设"的"在"沙子"这个词之后出现的可能性不大。我们通过为每个可能的句子分配概率,然后选择具有最高先验概率的字符来实现这一点。语言模型平滑(通常称为折扣)将帮助我们克服这样一个问题:这会创建一个对训练中未见过的任何内容分配0概率的模型。这是通过按照字符的一元概率比例,为所有可能出现的情况分配非零概率来实现的。这克服了传统基于n-gram建模的限制,而这一切都得益于循环神经网络中添加的时间序列维度。
最佳性能的模型被认为是对测试集中实际出现的字符给予最高概率的模型,因为它在实际未出现的字符上浪费较少的概率。
模型预测与测试集中真实转录的整体余弦相似度约为78%(验证集上为80%),而整体词错误率在测试集上约为18%(验证集上为16%)。
推理
最后,我展示了如何导出模型以进行快速本地推理。该模型可以在1-5秒的范围内生成文本转录,实现亚实时推理。项目以flask网络应用的形式部署到网络上,使用基于Python的REST API。网络应用使用HTML和CSS构建,然后通过gunicorn服务器和NGINX反向代理发布。该网络应用包含一个推理引擎,允许用户上传自定义录音以使用生产神经网络进行快速推理。该应用还包括性能和可视化引擎,使用户能够更仔细地检查开发过程中使用的数据集,并对模型的性能进行基准测试。该应用还包含了与Microsoft Azure认知服务API的语音转文本功能的接口,以便用户可以将模型与其他基于云的语音服务进行比较。同时还提供了一个使用Microsoft语音转文本平台的自动语音识别JavaScript API。最后,开发了一个使用Microsoft认知服务的情感分析引擎,让用户能够评估如何对模型预测的转录进行情感分析,以开始衡量对话和治疗互动的效果。假设情感分析可能有助于确定某人是否对治疗干预反应积极,因为他们的回应内容可能更积极而非消极。
结论
这就是模型构建演示的全部内容。现在,您已经从头开始训练了一个性能强大的用于语音识别的循环神经网络,其词错率低于20%,并已使用flask网络应用框架将其部署到网络上。
下一步
该项目的后续步骤以及您可以自行尝试的内容包括:
- 构建一个更深层次的模型,增加更多层。
- 在有背景噪音的音频上训练模型。
- 使用Mozilla的Common Voice数据集训练模型,参考这个项目来识别说话者的性别和口音。
- 在对话语音上训练模型,例如Buckeye语料库、Santa Barbara语料库或COSINE语料库中的语音。
- 开发一个处理包含敏感个人信息的语音的生产系统,参考这篇论文。
- 存储用户录制的音频,用于在线训练模型以提高性能。
- 使用TensorFlow重新创建模型,以提高性能。Mozilla已经展示了TensorFlow在自动语音识别方面的强大能力。
- 仅使用原始音频文件训练模型,如Pannous的这个项目。
- 训练模型以识别个别说话者,如Google使用VoxCeleb数据集所做的那样。
- 训练模型以识别说话者的情绪水平。Github上有许多示例。
- 使用Nvidia的开发者指南和RESTful接口,将推理引擎转换为Nvidia的TensorRT推理平台。
- 在其他语言上训练模型,如百度的Deep Speech 2。
- 尝试转录器模型,如百度在Deep Speech 3中所做的那样。
- 构建一个更传统的编码器/解码器模型,如Lu等人所概述的。
- 除了注意力机制外,向模型添加其他增强方法。
- 向LSTM单元添加窥视孔连接。
- 添加隐马尔可夫模型/高斯混合模型。
- 使用预训练的语言模型,如kaldi的这个模型。
- 构建一个计算字符级错误率的度量。
- 将词错误率降低到10%以下。
- 在模型中包含实体提取,使其能够开始识别讨论主题。
- 实现唤醒词检测引擎。
特别感谢
我要感谢以下人员/组织的支持和培训:
- General Assembly 的教学人员,包括 Charles Rice、Riley Davis 和 David Yerrington,感谢他们在数据科学和机器/深度学习方面的出色培训。
- deeplearning.ai 的 Andrew Ng,感谢他开发的 Coursera 序列模型课程,帮助我理解了循环神经网络背后的数学原理。
- 微软公司,感谢他们在 edX 平台上提供的语音识别系统课程,帮助我了解了语音识别系统的历史和理论。
- Udacity 的 Alexis Cook 和工作人员、IBM 的 Watson 团队以及亚马逊 Alexa 团队,感谢他们在 Udacity 平台上提供的人工智能课程,帮助我学会如何将知识应用于实际数据集。
- 洛桑联邦理工学院的 Paolo Prandoni 和 Martin Vetterli,感谢他们在 Coursera 上教授的数字信号处理课程,帮助我理解了傅里叶变换背后的数学原理。
- Nvidia 的工作人员,感谢他们帮助我学习如何在 Jetson 上运行推理。
- General Assembly 的西雅图 DSI-3 cohort,感谢他们支持我的学习之旅,并在这个项目的开发阶段给予我良好的建设性反馈。
- Miguel Grinberg,感谢他的书籍和在线 Flask 教程,帮助我学习如何部署 Flask web 应用。
- Jetson Hacks,感谢他们提供了多个教程和代码库,帮助我学习如何在 Jetson 上开发。
贡献
如果您想为这个项目做出贡献,请 fork 并提交 pull request。我始终欢迎反馈意见,也非常希望得到这个项目的帮助。











