
 访问官网
访问官网 Github
Github Huggingface
Huggingface镜像
在你的笔记本电脑上实现可定制的AI驱动镜像。

镜像是一个网页应用,它持续监测来自网络摄像头的实时视频流,并做出回应评论。
- 100%本地和私密: 尝试各种想法。不用担心,一切都在你的笔记本电脑上进行,无需互联网连接。
- 免费: 由于AI模型完全在你的机器上运行,你可以一直运行它并尝试不同的东西。
- 可定制: 只需更改提示(或调整代码),你就可以轻松地重新设定镜像来做不同的事情。
工作原理
观看镜像运行的视频:
- 当你启动应用时,浏览器会请求网络摄像头权限。
- 当你允许使用网络摄像头时,它会开始向AI(Bakllava,运行在llama.cpp上)传输视频流。
- AI会分析图像并实时传输响应,前端会实时打印这些响应。
使用方法
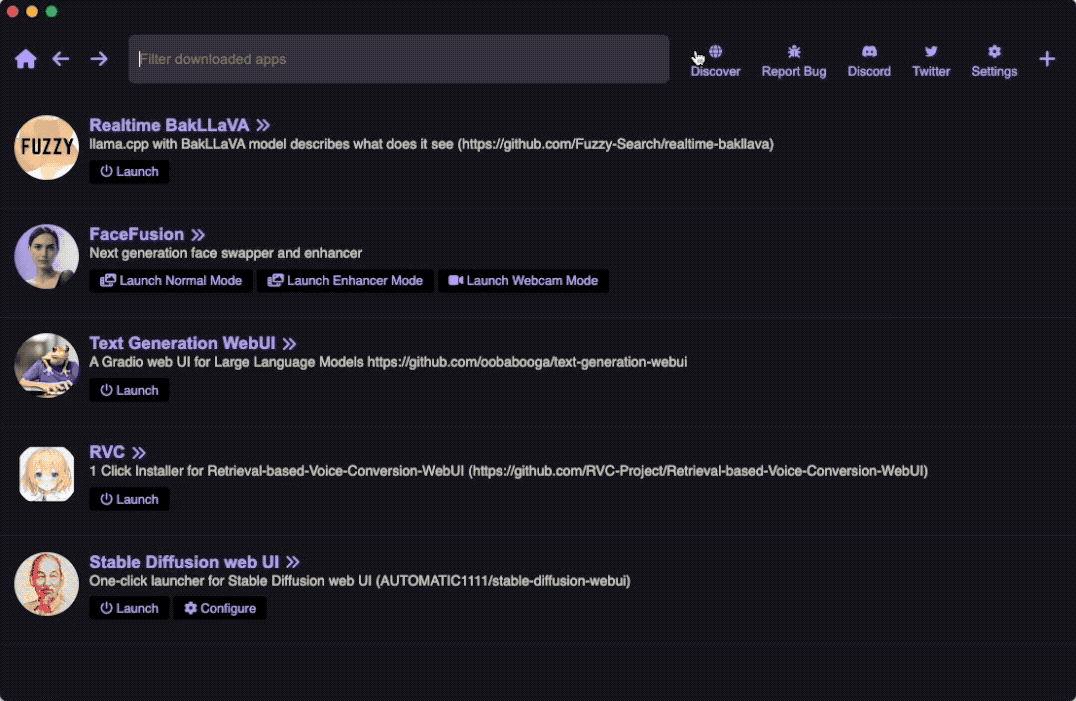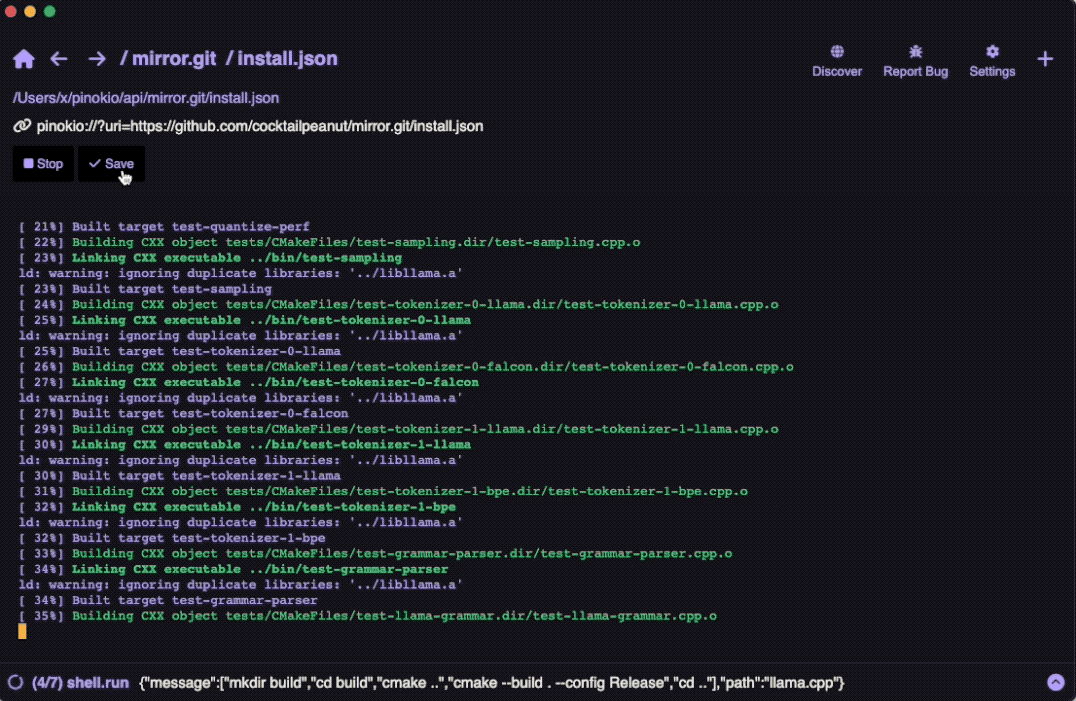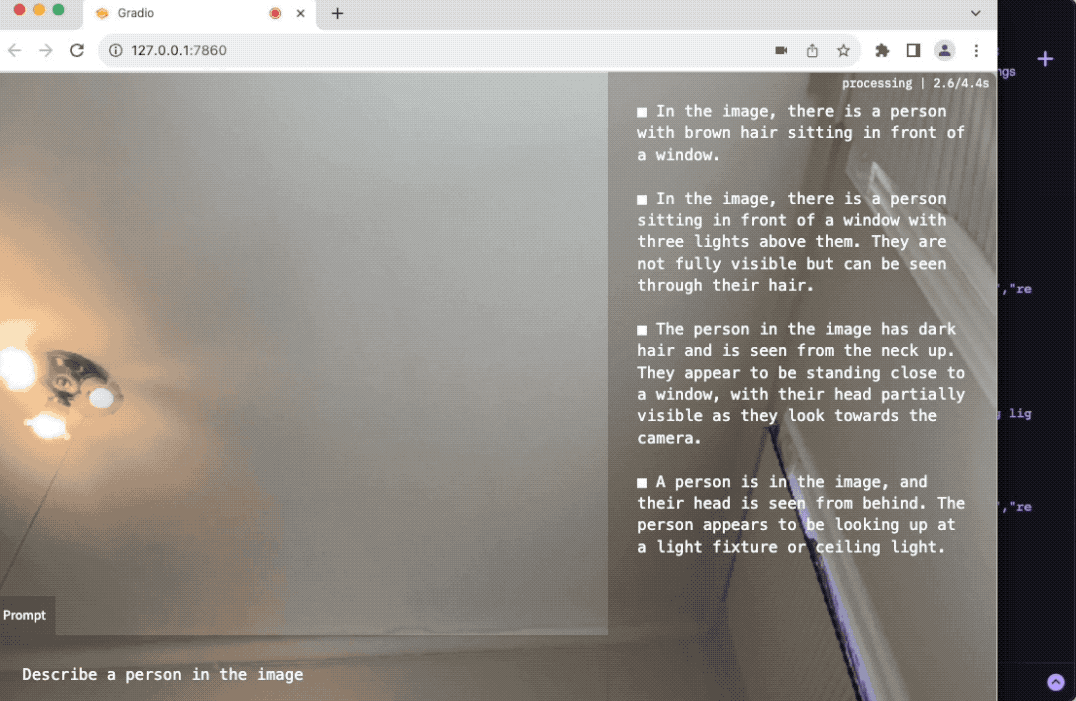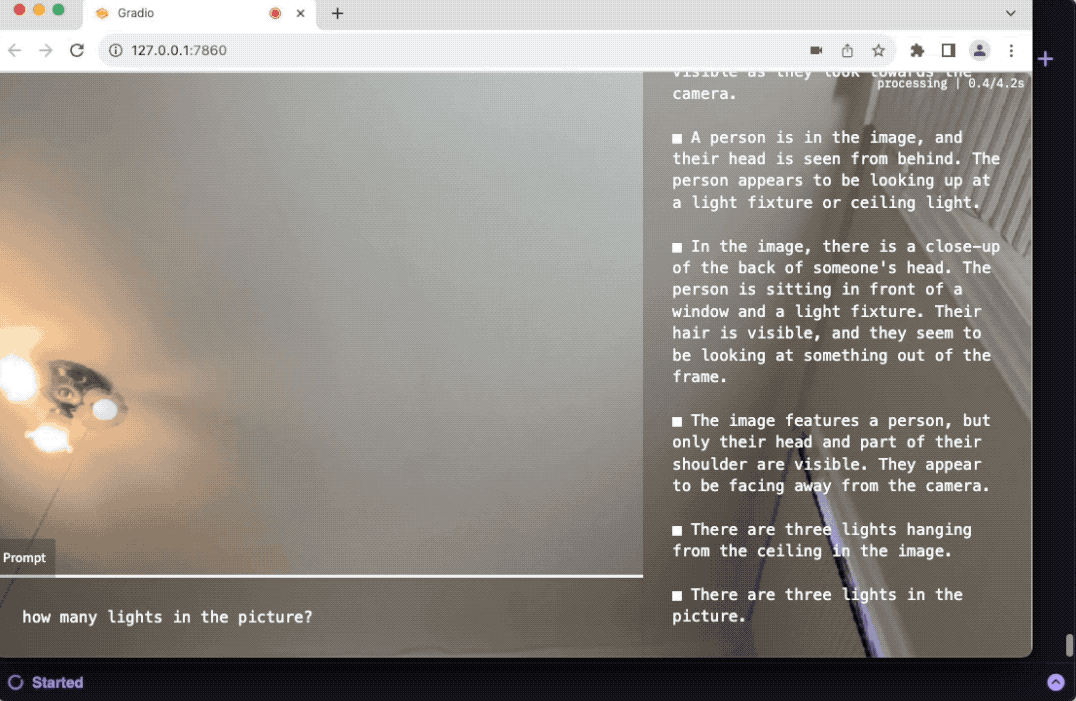
当你启动网页界面时,它会立即开始基于提示"描述图像中的人"来传输AI的响应。
你可以编辑这个字段,让镜像开始传输你想要的任何内容
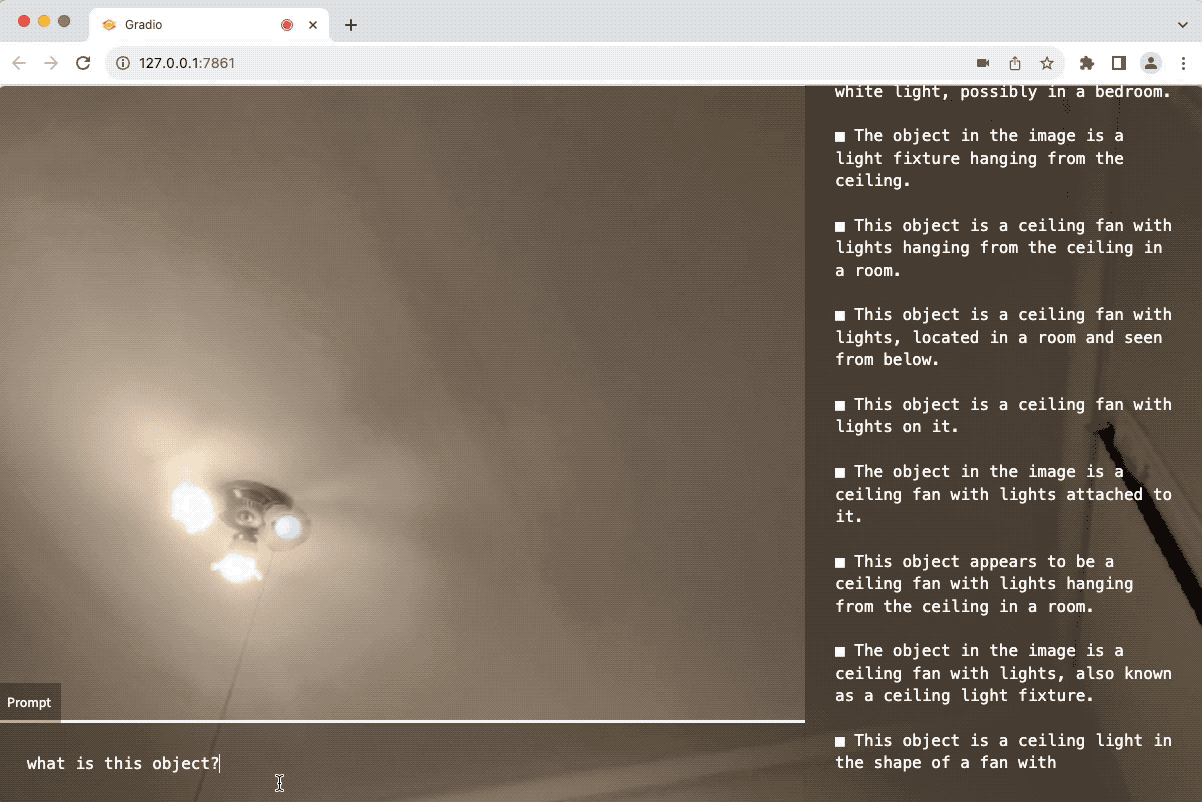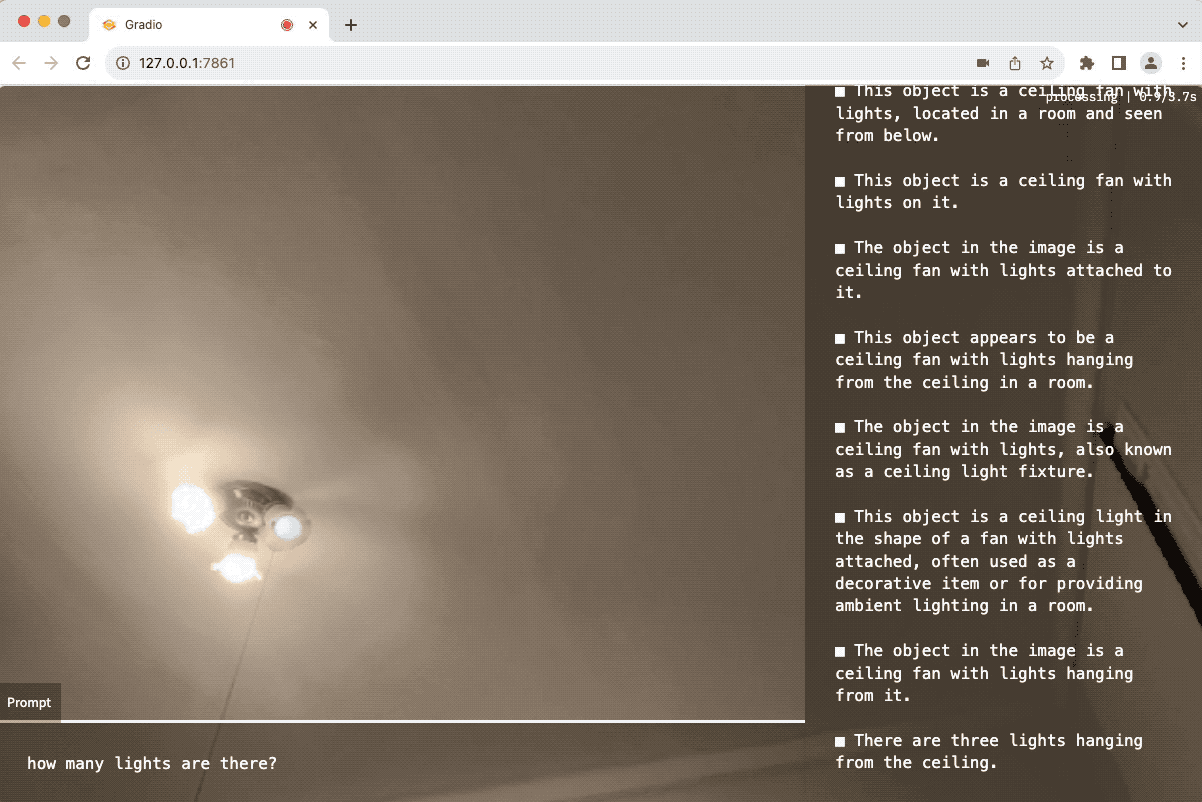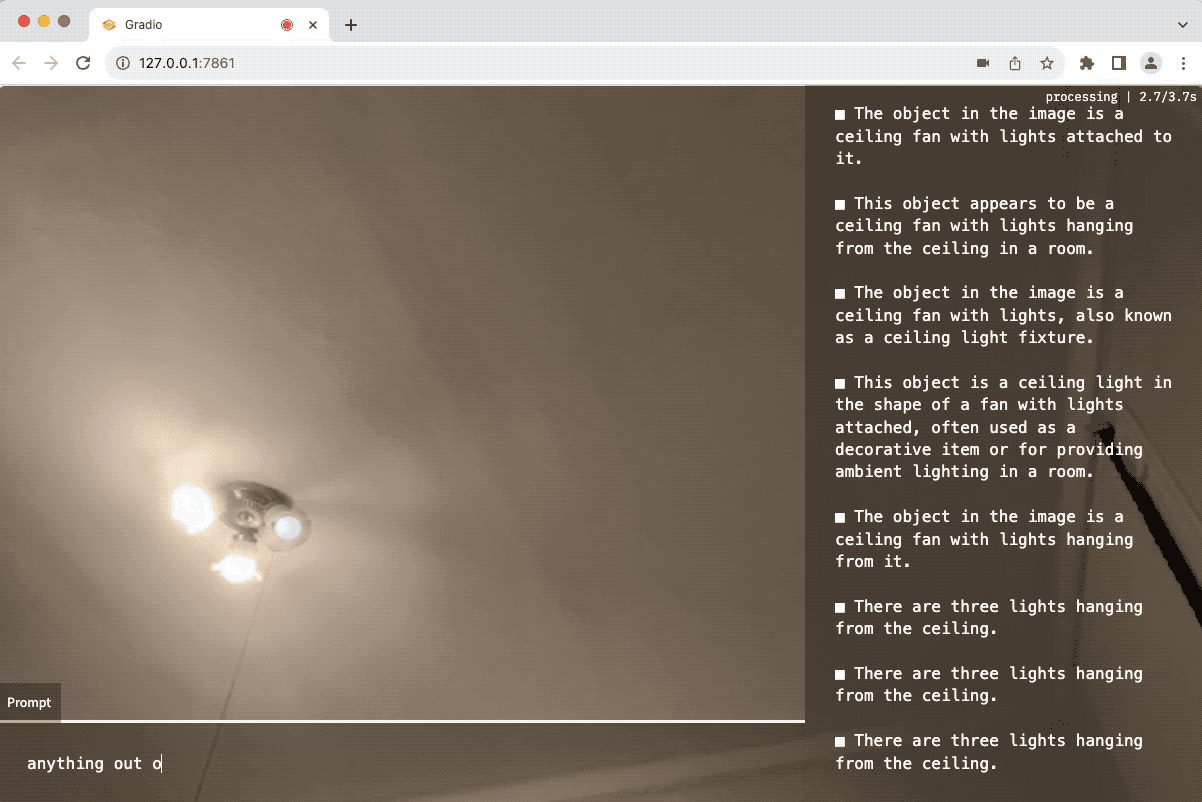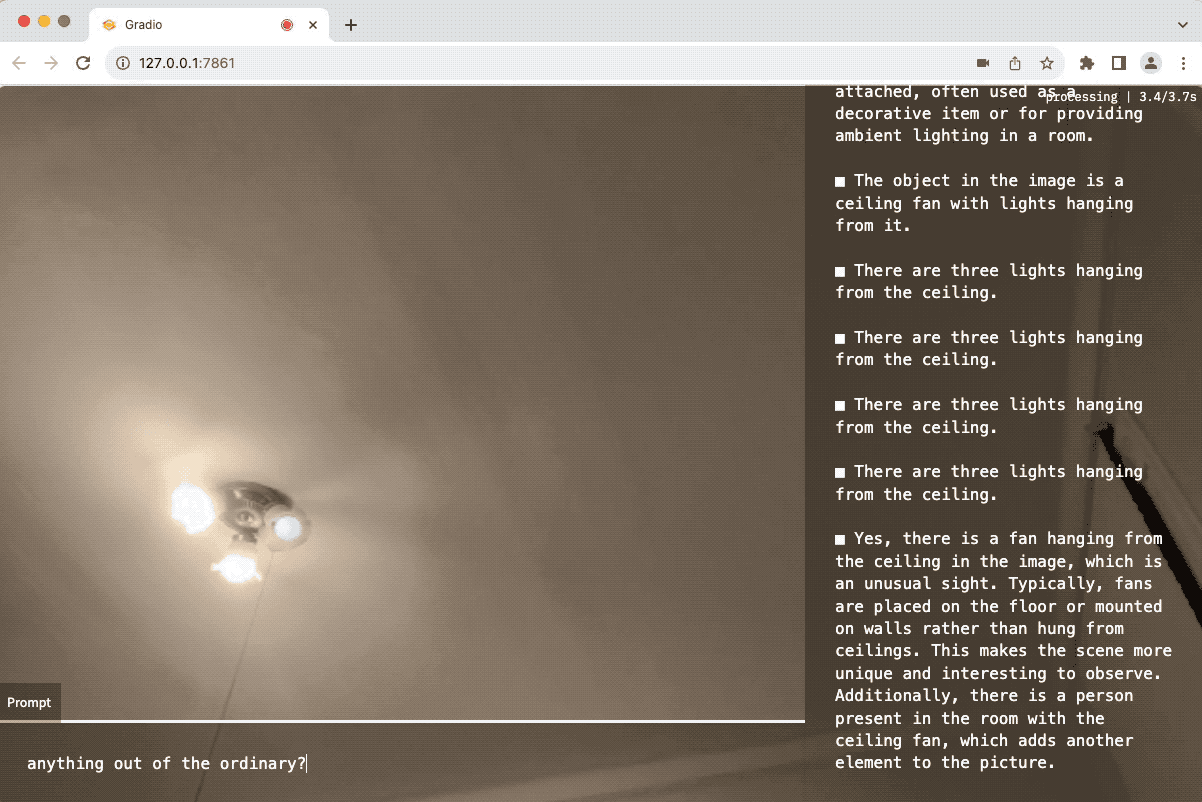
你可以尝试的一些示例提示:
- 我手里拿的是什么物品?
- 这个人在做什么?
- 描述图像中的一些值得注意的事件。
- 这张图片中有多少人?
- 如果你看到任何奇怪的东西,请告诉我。
安装
[推荐] 一键安装
使用Pinokio尝试一键安装:https://pinokio.computer/item?uri=https://github.com/cocktailpeanut/mirror
确保使用最新版本的Pinokio(0.1.49及以上)
镜像有很多组成部分,所以如果你不使用一键安装程序,可能需要大量工作:
- 协调多个后端(llama.cpp服务器和gradio网页界面服务器)
- 安装先决条件,如cmake、visual studio(Windows)、ffmpeg等。
如果你想手动安装,请转到以下部分。
手动安装
请注意,本节提到的所有内容基本上就是一键安装程序自动完成的内容,适用于Mac、Windows和Linux。因此,如果你在尝试手动运行镜像时遇到困难,可以尝试一键安装。
1. 克隆此仓库
git clone https://github.com/cocktailpeanut/mirror
2. 克隆llama.cpp
git clone https://github.com/ggerganov/llama.cpp
3. 下载AI模型
将以下bakllava模型文件下载到llama.cpp/models文件夹
- https://huggingface.co/mys/ggml_bakllava-1/resolve/main/ggml-model-q4_k.gguf
- https://huggingface.co/mys/ggml_bakllava-1/resolve/main/mmproj-model-f16.gguf
4. 构建llama.cpp
cd llama.cpp
mkdir build
cd build
cmake ..
cmake --build . --config Release
5. 安装依赖
创建虚拟环境并安装依赖
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
6. 安装先决条件
安装FFMPEG:https://ffmpeg.org/download.html
7. 启动llama.cpp服务器
首先启动llama.cpp服务器:
Windows
cd llama.cpp\build\bin
Release\server.exe -m ..\..\ggml-model-q4_k.gguf --mmproj ..\..\mmproj-model-f16.gguf -ngl 1
Mac和Linux
cd llama.cpp\build\bin
./server -m ..\..\ggml-model-q4_k.gguf --mmproj ..\..\mmproj-model-f16.gguf -ngl 1
8. 启动网页界面
首先激活环境:
source venv/bin/activate
然后运行app.py文件
python app.py
致谢
- 后端代码受到Realtime Bakllava的启发和采用,该项目使用...
- Llama.cpp作为LLM服务器。
- Bakllava作为多模态AI模型。
- 网页界面使用gradio构建。











