
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档 论文
论文
提高扩散模型在内容一致性超分辨率上的稳定性

孙凌晨1,2 | 吴荣源1,2 | 张正强1,2 | 雍宏伟1 | 张磊1,2
1香港理工大学, 2OPPO研究院
⏰ 更新
- 2024.1.17: 添加Replicate演示
。
- 2024.1.16: 添加Gradio演示。
- 2024.1.14: 在inference_ccsr_tile.py中集成tile_diffusion和tile_vae以节省推理时的GPU内存。
- 2024.1.10: 更新CCSR colab演示。❤ 感谢camenduru的实现!
- 2024.1.4: 发布真实世界超分辨率的代码和模型。
- 2024.1.3: 论文发布。
- 2023.12.23: 代码库发布。
:star: 如果CCSR对您的图像或项目有帮助,请给这个仓库点个星。谢谢!:hugs:
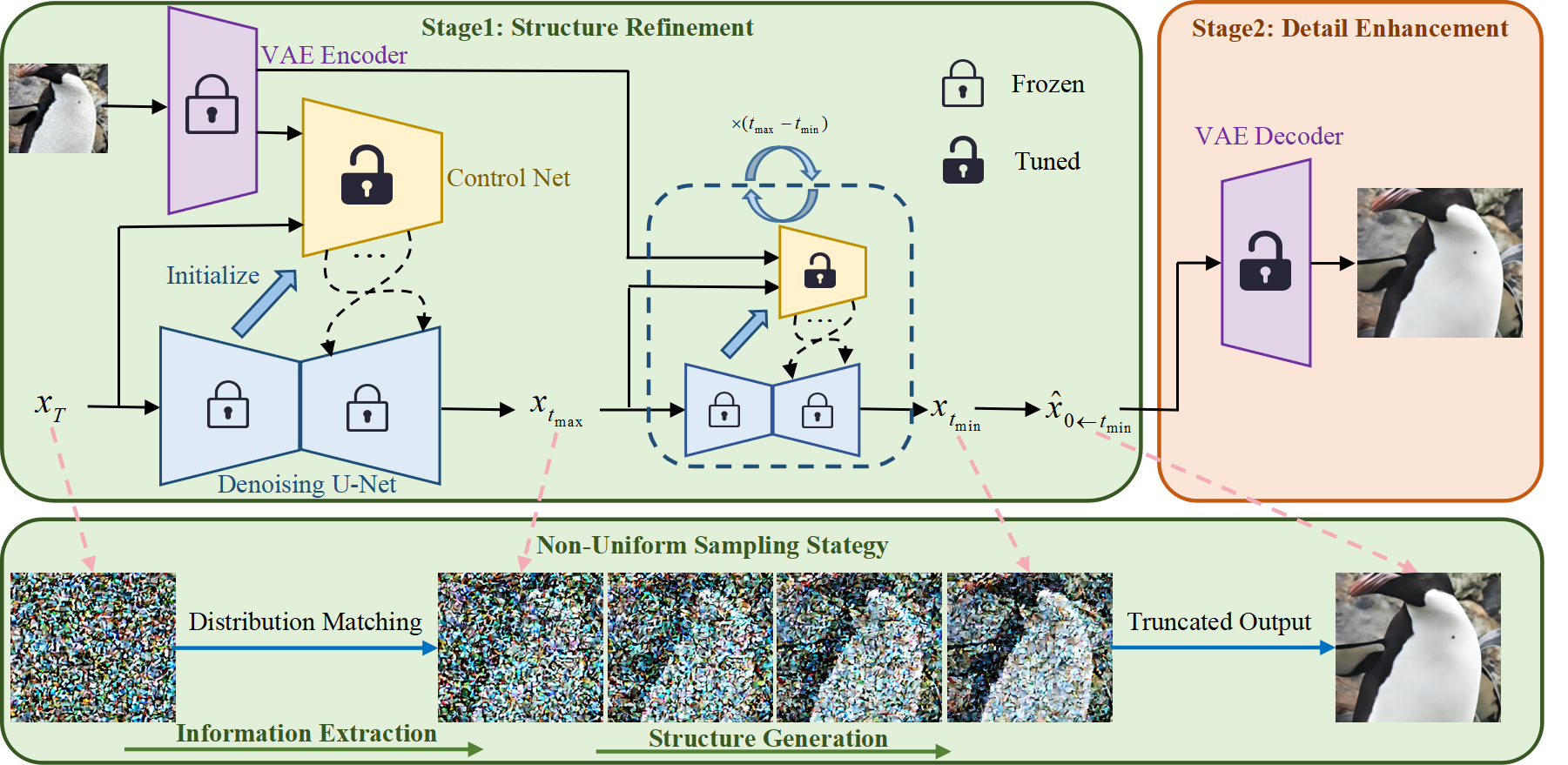
🌟 整体框架
😍 视觉效果
真实世界超分辨率演示






真实世界超分辨率对比
对于基于扩散模型的方法,为了更全面公平的比较,展示了10次运行中PSNR值最好和最差的两张恢复图像。

双三次插值超分辨率对比
 更多对比请参阅我们的论文详细内容。
更多对比请参阅我们的论文详细内容。
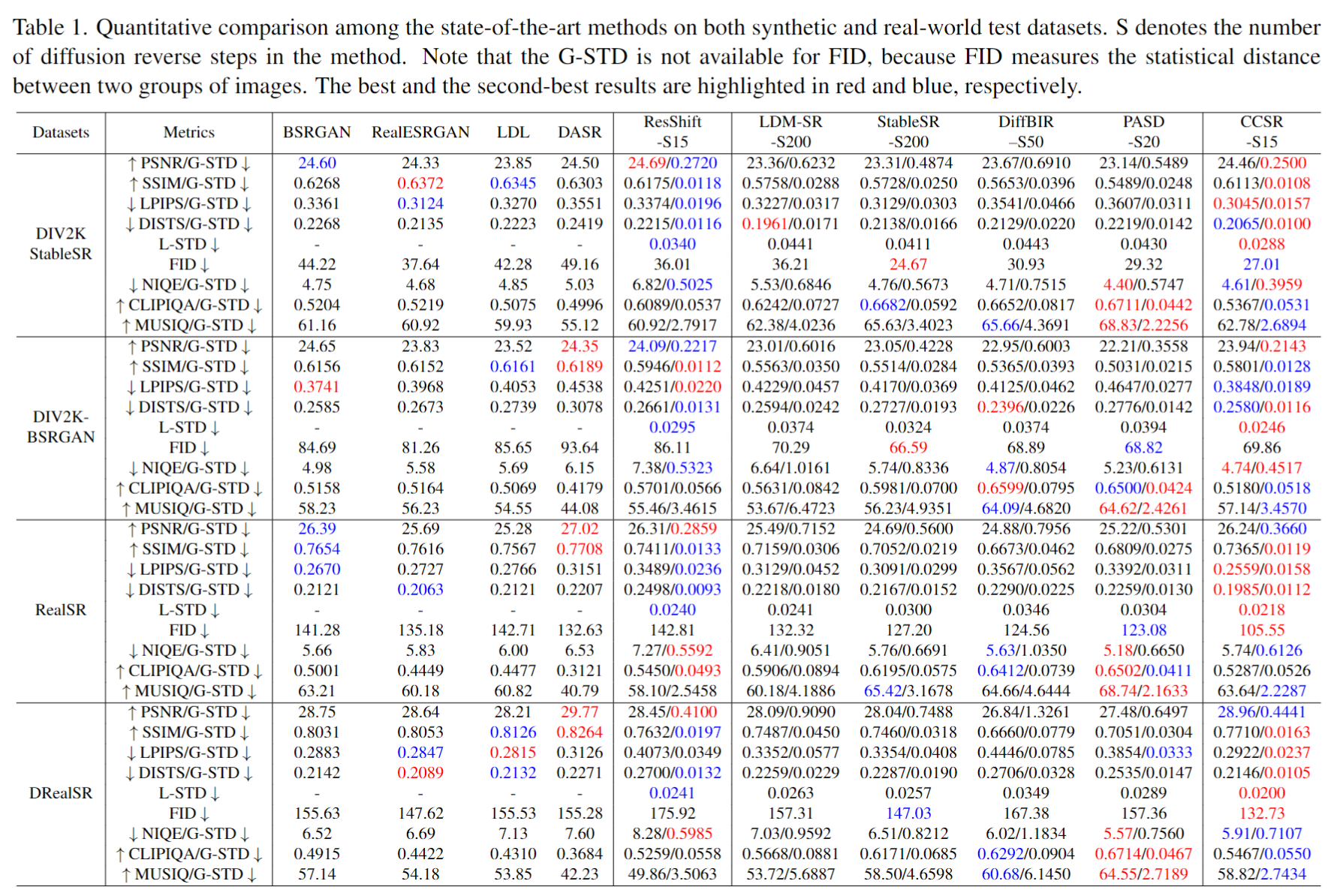
📝 定量对比
我们提出了新的稳定性指标,即全局标准差(G-STD)和局部标准差(L-STD),分别用于测量基于扩散的方法在图像级和像素级的超分辨率结果变化。
有关G-STD和L-STD的更多细节可以在我们的论文中找到。
⚙ 依赖和安装
## 克隆此仓库
git clone https://github.com/csslc/CCSR.git
cd CCSR
# 创建一个Python版本大于等于3.9的环境
conda create -n ccsr python=3.9
conda activate ccsr
pip install -r requirements.txt
pip install -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers
🍭 快速推理
步骤1: 下载预训练模型
- 从以下链接下载CCSR模型:
| 模型名称 | 描述 | 谷歌云盘 | 百度网盘 |
|---|---|---|---|
| real-world_ccsr.ckpt | 用于真实世界图像复原的CCSR模型。 | 下载 | 下载 (密码: CCSR) |
| bicubic_ccsr.ckpt | 用于双三次插值图像复原的CCSR模型。 | 下载 | 下载 |
步骤2: 准备测试数据
您可以将测试图像放在preset/test_datasets文件夹中。
步骤3: 运行测试命令
python inference_ccsr.py \
--input preset/test_datasets \
--config configs/model/ccsr_stage2.yaml \
--ckpt weights/real-world_ccsr.ckpt \
--steps 45 \
--sr_scale 4 \
--t_max 0.6667 \
--t_min 0.3333 \
--color_fix_type adain \
--output experiments/test \
--device cuda \
--repeat_times 1
我们将tile_diffusion和tile_vae集成到inference_ccsr_tile.py中,以节省推理时的GPU内存。 你可以根据设备的显存大小调整tile大小和步长。
python inference_ccsr_tile.py \
--input preset/test_datasets \
--config configs/model/ccsr_stage2.yaml \
--ckpt weights/real-world_ccsr.ckpt \
--steps 45 \
--sr_scale 4 \
--t_max 0.6667 \
--t_min 0.3333 \
--tile_diffusion \
--tile_diffusion_size 512 \
--tile_diffusion_stride 256 \
--tile_vae \
--vae_decoder_tile_size 224 \
--vae_encoder_tile_size 1024 \
--color_fix_type adain \
--output experiments/test \
--device cuda \
--repeat_times 1
你可以通过将repeat_time设置为N来获得N个不同的超分辨率结果,以测试CCSR的稳定性。数据文件夹应如下所示:
experiments/test
├── sample0 # 第一组超分辨率结果
└── sample1 # 第二组超分辨率结果
...
└── sampleN # 第N组超分辨率结果
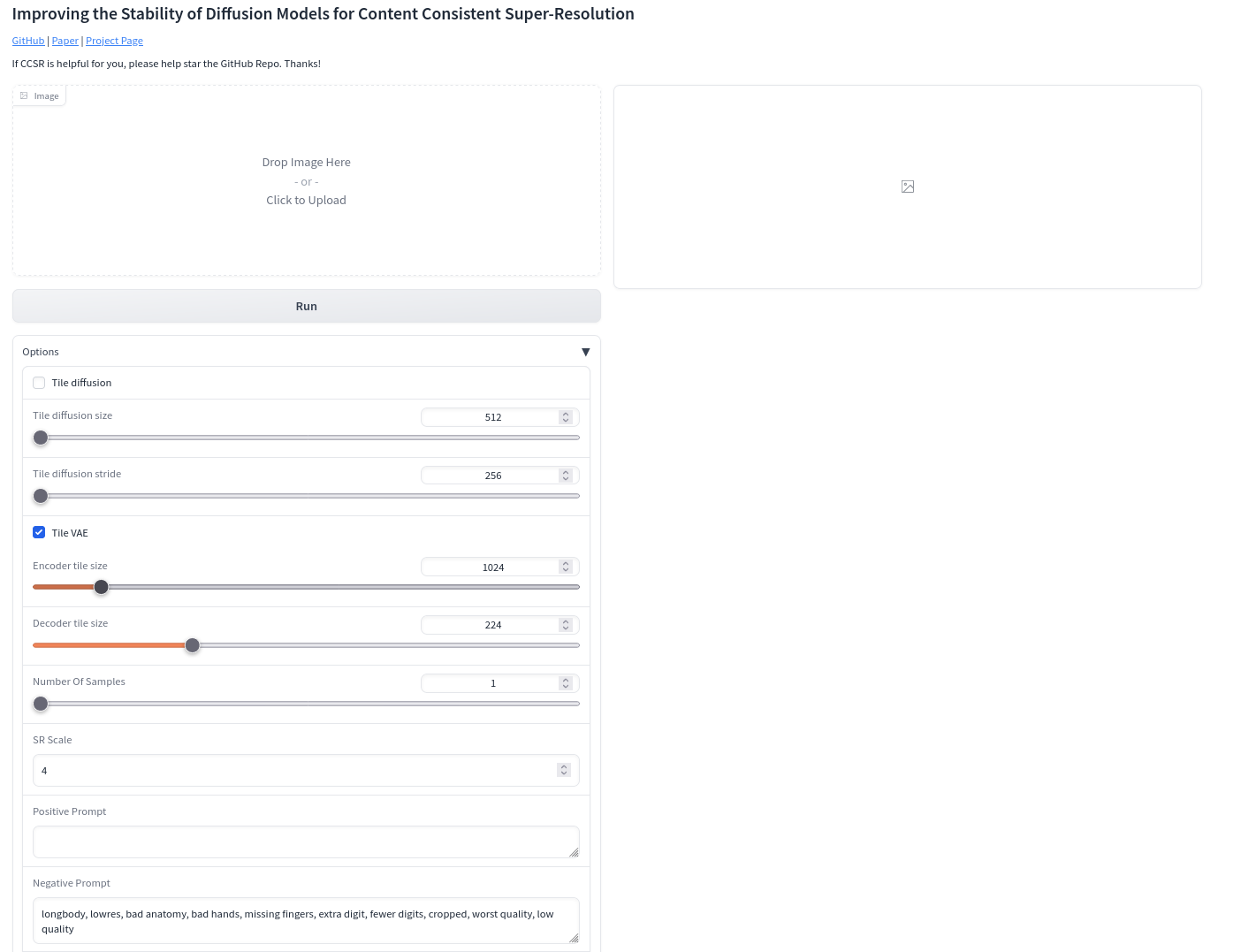
Gradio演示
下载模型real-world_ccsr.ckpt并将模型放入weights/,然后运行以下命令与gradio网站交互。
python gradio_ccsr.py \
--ckpt weights/real-world_ccsr.ckpt \
--config configs/model/ccsr_stage2.yaml \
--device cuda
📏 评估
-
计算每个恢复组的图像质量评估。
在cal_iqa.py中填写所需信息并运行,然后你可以在文件夹中获得评估结果,如下所示:
log_path ├── log_name_npy # 将每个恢复组的IQA值保存为npy文件 └── log_name.log # 日志记录 -
计算基于扩散的超分辨率方法的G-STD值。
在iqa_G-STD.py中填写所需信息并运行,然后你可以获得N个恢复组的平均IQA值和G-STD值。
-
计算基于扩散的超分辨率方法的L-STD值。
在iqa_L-STD.py中填写所需信息并运行,然后你可以获得L-STD值。
🚋 训练
步骤1: 准备训练数据
-
生成训练集和验证集的文件列表。
python scripts/make_file_list.py \ --img_folder [hq_dir_path] \ --val_size [validation_set_size] \ --save_folder [save_dir_path] \ --follow_links此脚本将收集
img_folder中的所有图像文件,并自动将它们分为训练集和验证集。你将在save_folder中得到两个文件列表,每个文件列表中的每一行包含一个图像文件的绝对路径:save_dir_path ├── train.list # 训练文件列表 └── val.list # 验证文件列表 -
配置训练集和验证集。
对于真实世界图像恢复,在以下配置文件中填写适当的值。
步骤2: 训练第一阶段模型
-
下载预训练的Stable Diffusion v2.1以提供生成能力。
wget https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.ckpt --no-check-certificate -
创建初始模型权重。
python scripts/make_stage2_init_weight.py \ --cldm_config configs/model/ccsr_stage1.yaml \ --sd_weight [sd_v2.1_ckpt_path] \ --output weights/init_weight_ccsr.ckpt -
配置训练相关信息。
在第一阶段训练的配置文件中填写适当的设置。
-
开始训练。
python train.py --config configs/train_ccsr_stage1.yaml
步骤3: 训练第二阶段模型
-
配置训练相关信息。
在第二阶段训练的配置文件中填写适当的设置。
-
开始训练。
python train.py --config configs/train_ccsr_stage2.yaml
引用
如果我们的代码对你的研究或工作有帮助,请考虑引用我们的论文。 以下是BibTeX引用:
@article{sun2023ccsr,
title={Improving the Stability of Diffusion Models for Content Consistent Super-Resolution},
author={Sun, Lingchen and Wu, Rongyuan and Zhang, Zhengqiang and Yong, Hongwei and Zhang, Lei},
journal={arXiv preprint arXiv:2401.00877},
year={2024}
}
许可证
本项目采用Apache 2.0许可证发布。
致谢
本项目基于ControlNet、BasicSR和DiffBIR。部分代码来自StableSR。感谢他们出色的工作。
联系方式
如有任何问题,请联系:ling-chen.sun@connect.polyu.hk











