
 访问官网
访问官网 Github
Github 文档
文档 论文
论文

数据工程师的数据应用性能监控


如果您喜欢DataFlint,请给我们一个⭐️,并加入我们的Slack社区,获取功能请求、支持等更多内容!
DataFlint是什么?
DataFlint是为大数据工程师打造的Apache Spark开源D-APM(数据应用性能监控)工具。
DataFlint的使命是将DataDog和New Relic等APM(应用性能监控)解决方案的开发体验带入大数据世界。
DataFlint通过开源库几分钟内即可安装完成,基于现有的Spark-UI基础设施运行,旨在帮助您解决大数据性能问题并调试故障!
演示
功能
- 📈 实时查询和集群状态
- 📊 查询分解与性能热图
- 📋 应用程序运行摘要
- ⚠️ 性能警报和建议
- 👀 识别查询失败
- 🤖 Spark AI助手
更多信息请参阅我们的功能
安装
Scala
通过sbt安装DataFlint:
libraryDependencies += "io.dataflint" %% "spark" % "0.2.3"
然后指示Spark加载DataFlint插件:
val spark = SparkSession
.builder()
.config("spark.plugins", "io.dataflint.spark.SparkDataflintPlugin")
...
.getOrCreate()
PySpark
在PySpark会话构建器中添加这两个配置:
builder = pyspark.sql.SparkSession.builder
...
.config("spark.jars.packages", "io.dataflint:spark_2.12:0.2.3") \
.config("spark.plugins", "io.dataflint.spark.SparkDataflintPlugin") \
...
Spark Submit
或者,通过在spark-submit命令中添加这两行,无需代码更改即可将DataFlint作为Spark ivy包安装:
spark-submit
--packages io.dataflint:spark_2.12:0.2.3 \
--conf spark.plugins=io.dataflint.spark.SparkDataflintPlugin \
...
使用
安装完成后,您将在Spark UI中看到一个"DataFlint"按钮,点击它即可开始使用DataFlint

其他安装选项
- 如果您的Spark集群使用Scala 2.13,我们也支持Scala 2.13,请将包名更改为io.dataflint:spark_2.13:0.2.3
- 更多安装选项,包括Python和k8s spark-operator,请参阅在Spark上安装文档
- 要在Spark历史服务器上安装DataFlint以观察已完成的运行,请参阅在Spark历史服务器上安装文档
- 要在DataBricks上安装DataFlint,请参阅在Databricks上安装文档
工作原理
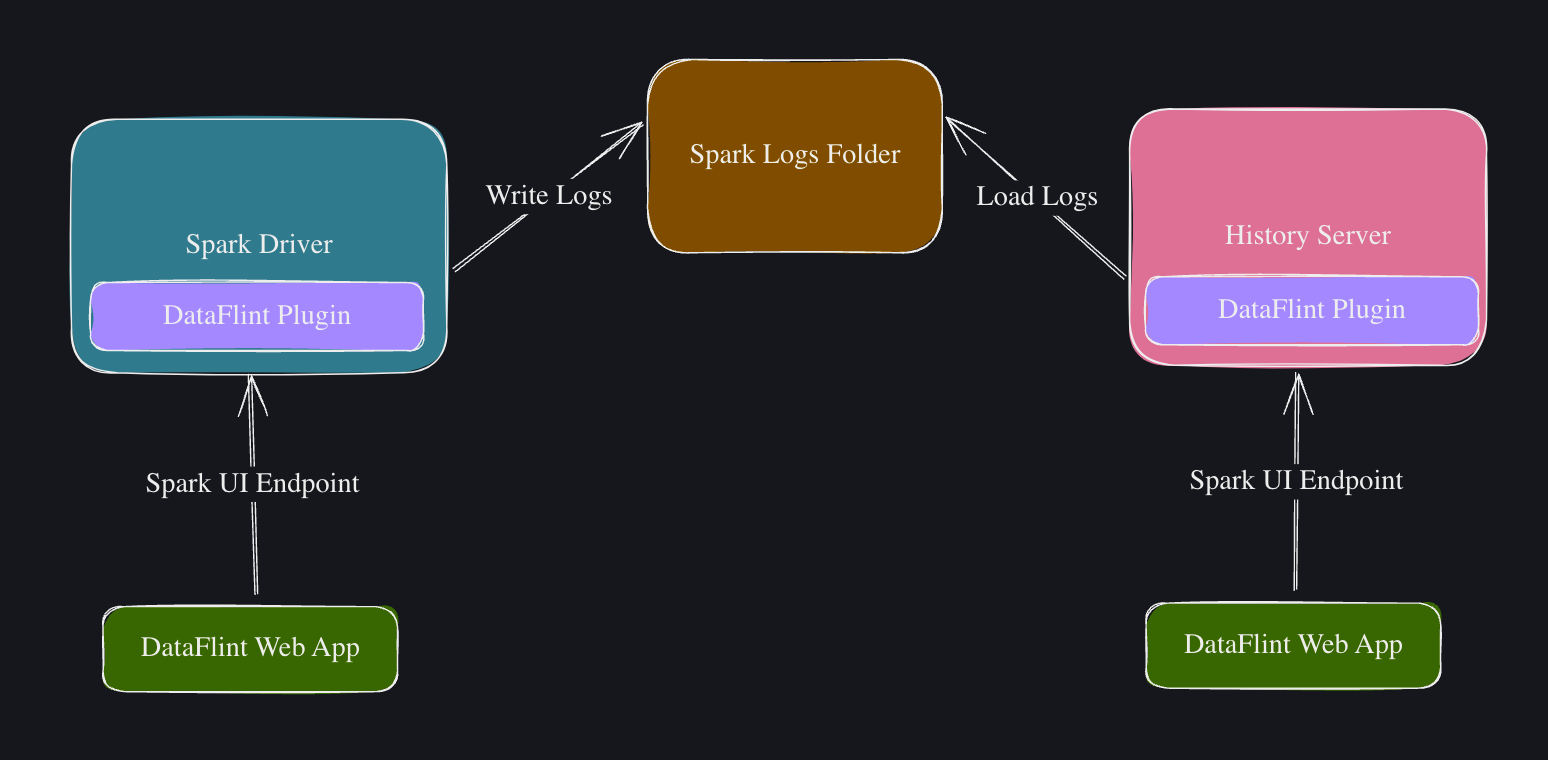
DataFlint作为插件安装在Spark驱动程序和历史服务器上。
该插件暴露了额外的HTTP资源,用于提供Spark UI中不可用的其他指标,以及一个现代化的SPA网络应用程序,可以从Spark获取数据而无需刷新页面。
更多信息,请参阅工作原理文档
文章
使用DataFlint修复Apache Spark中的小文件性能问题
兼容性矩阵
DataFlint需要Spark 3.2及以上版本,并支持Scala 2.12或2.13版本。
| Spark平台 | DataFlint实时 | DataFlint历史服务器 |
|---|---|---|
| 本地 | ✅ | ✅ |
| 独立模式 | ✅ | ✅ |
| Kubernetes Spark Operator | ✅ | ✅ |
| EMR | ✅ | ✅ |
| Dataproc | ✅ | ❓ |
| HDInsights | ✅ | ❓ |
| Databricks | ✅ | ❌ |
更多信息,请参阅支持的版本文档











