
 访问官网
访问官网 Github
Github 论文
论文HybridNets: 端到端感知网络
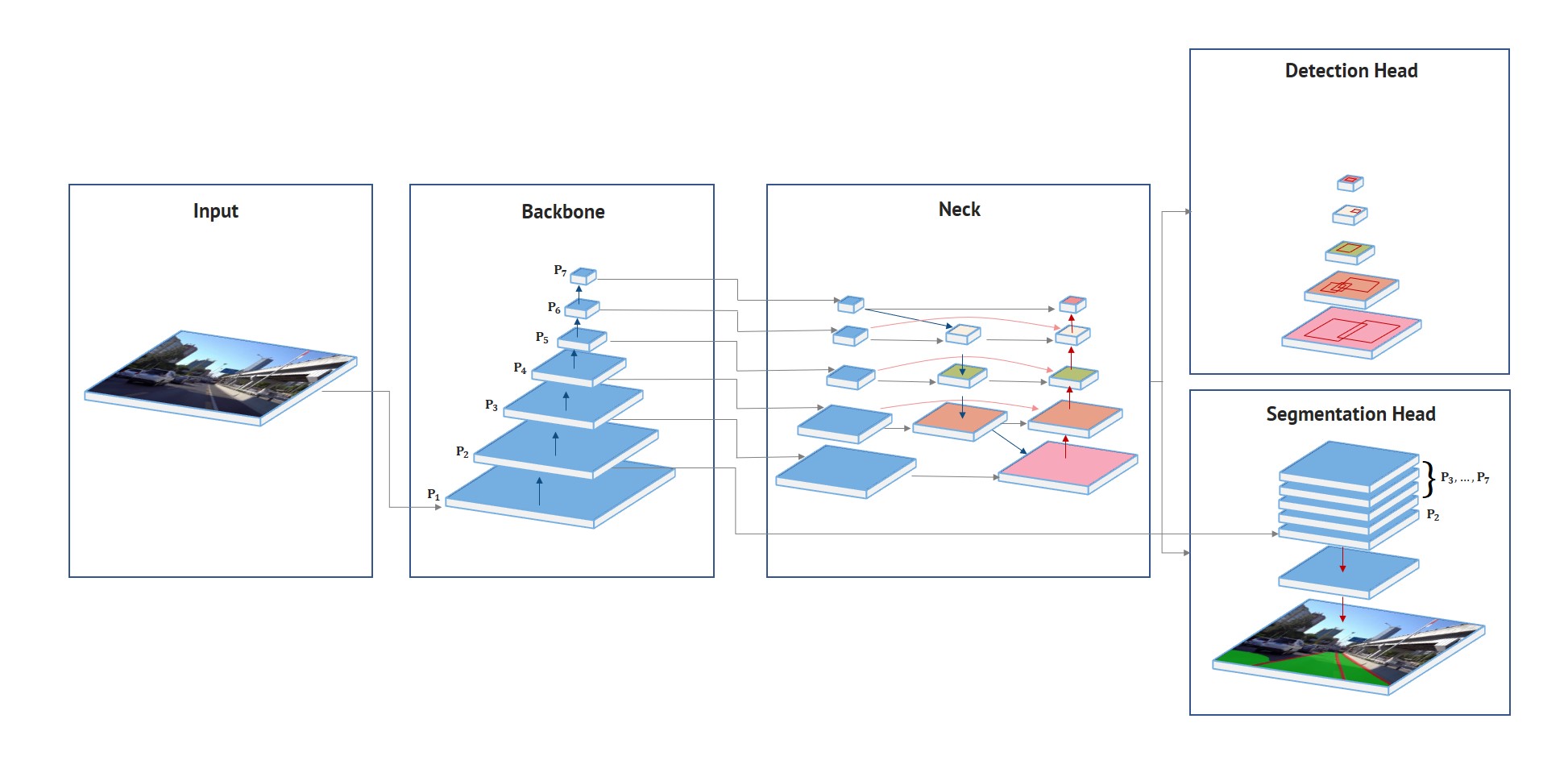 HybridNets 网络架构。
HybridNets 网络架构。
![]()
作者:Dat Vu, Bao Ngo, Hung Phan :email: FPT大学
(:email:) 通讯作者。
arXiv技术报告 (arXiv 2203.09035)
![]()
![]()
关于项目
HybridNets 是一个面向多任务的端到端感知网络。我们的工作集中在交通物体检测、可行驶区域分割和车道线检测上。HybridNets 能够在嵌入式系统上实时运行,并在 BDD100K 数据集上获得了最先进的物体检测和车道检测结果。

项目结构
HybridNets
│ backbone.py # 模型配置
| export.py # 更新于2022年10月:onnx权重及附带的.npy锚点
│ hubconf.py # Pytorch Hub入口点
│ hybridnets_test.py # 图像推理
│ hybridnets_test_videos.py # 视频推理
│ train.py # 训练脚本
│ train_ddp.py # 分布式数据并行训练(多GPU)
│ val.py # 验证脚本
│ val_ddp.py # 分布式数据并行验证(多GPU)
│
├───encoders # https://github.com/qubvel/segmentation_models.pytorch/tree/master/segmentation_models_pytorch/encoders
│ ...
│
├───hybridnets
│ autoanchor.py # 通过k-means生成新锚点
│ dataset.py # BDD100K数据集
│ loss.py # Focal损失,Tversky损失(dice)
│ model.py # 模型块
│
├───projects
│ bdd100k.yml # 项目配置
│
├───ros # C++ ROS路径规划包
│ ...
│
└───utils
| constants.py
│ plot.py # 绘制边界框
│ smp_metrics.py # https://github.com/qubvel/segmentation_models.pytorch/blob/master/segmentation_models_pytorch/metrics/functional.py
│ utils.py # 各种辅助函数(预处理,后处理,评估等)
开始使用 
安装
本项目使用 Python>=3.7 和 Pytorch>=1.10 开发。
git clone https://github.com/datvuthanh/HybridNets
cd HybridNets
pip install -r requirements.txt
演示
# 下载端到端权重
curl --create-dirs -L -o weights/hybridnets.pth https://github.com/datvuthanh/HybridNets/releases/download/v1.0/hybridnets.pth
# 图像推理
python hybridnets_test.py -w weights/hybridnets.pth --source demo/image --output demo_result --imshow False --imwrite True
# 视频推理
python hybridnets_test_videos.py -w weights/hybridnets.pth --source demo/video --output demo_result
# 结果将保存在名为 demo_result 的新文件夹中
使用方法
数据准备
推荐的数据集结构:
HybridNets
└───datasets
├───imgs
│ ├───train
│ └───val
├───det_annot
│ ├───train
│ └───val
├───da_seg_annot
│ ├───train
│ └───val
└───ll_seg_annot
├───train
└───val
在 projects/your_project_name.yml 中更新您的数据集路径。
对于 BDD100K:
训练
1) 编辑或创建新的项目配置,使用 bdd100k.yml 作为模板。数据增强参数在此处设置。
# 数据集的均值和标准差(RGB顺序)
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
# bdd100k 锚框
anchors_scales: '[2**0, 2**0.70, 2**1.32]'
anchors_ratios: '[(0.62, 1.58), (1.0, 1.0), (1.58, 0.62)]'
# BDD100K 官方支持 10 个类别
# obj_list: ['person', 'rider', 'car', 'truck', 'bus', 'train', 'motorcycle', 'bicycle', 'traffic light', 'traffic sign']
obj_list: ['car']
obj_combine: ['car', 'bus', 'truck', 'train'] # 如果是单类别,将这些类别合并为 obj_list 中的一个类别
# 留空列表 ([]) 则不合并类别
seg_list: ['road',
'lane']
seg_multilabel: false # 一个像素可以属于多个标签(如车道线 + 底层道路)
dataset:
dataroot: path/to/imgs
labelroot: path/to/det_annot
segroot:
# 必须与 seg_list 顺序一致
- path/to/da_seg_annot
- path/to/ll_seg_annot
fliplr: 0.5
flipud: 0.0
hsv_h: 0.015
hsv_s: 0.7
hsv_v: 0.4
...
2) 训练
python train.py -p bdd100k # 您的项目名称
-c 3 # effnet 骨干网络的系数,论文中的结果是 3
或 -bb repvgg_b0 # 使用 timm 更改骨干网络
-n 4 # num_workers
-b 8 # 每个 GPU 的批量大小
-w path/to/weight # 使用 'last' 从之前的会话恢复训练
--freeze_det # 冻结检测头,其他选项:--freeze_backbone, --freeze_seg
--lr 1e-5 # 学习率
--optim adamw # adamw | sgd
--num_epochs 200
请查看 python train.py --help 获取更多选项。
重要 (已废弃): 如果您想在多个 GPU 上训练,请使用 train_ddp.py。已在 NVIDIA DGX 上使用 8xA100 40GB 测试。
为什么我们没有将 DDP 合并到现有的 train.py 脚本中?
- 有太多的 if-else 语句。
- 不想破坏已经正常运行的功能。
- 懒。
2022年6月24日更新: 由于我们做了很多更改,train_ddp.py 已经失效。因此,我们决定编写一个支持 DDP 的合并版 train.py,以便于维护。同时,如果您确实需要使用,请克隆这个提交,其中包含一个可用的 train_ddp.py 脚本。
3) 评估
python val.py -w checkpoints/weight.pth
同样,查看 python val.py --help 获取更多选项。
验证过程被终止了!我该怎么办? => 这是因为我们使用了 0.001 的默认置信度阈值来与其他网络进行比较。因此,在计算指标时,需要处理大量的边界框,导致内存不足,最终在下一个 epoch 开始前使程序崩溃。
话虽如此,有多种方法可以解决这个问题,请选择最适合您的方法:
- 在高内存实例上训练(这里的内存指主内存,而非GPU的显存)。供您参考,我们只能在64GB内存的机器上验证合并后的"汽车"类别。
- 使用
python train.py --cal_map False进行训练,以在验证时不计算指标。这个选项只会打印验证损失。当损失趋于平稳且条件允许时,可以租用一台高内存实例,使用python val.py -w checkpoints/xxx_best.pth来验证最佳权重。我们实际上就是这样做来节省成本的。 - 根据您的应用和最终目标,使用
python train.py --conf_thres 0.5或python val.py --conf_thres 0.5来降低置信度阈值。除非您是在帮助我们进行实验:smiling_face_with_three_hearts:或与我们竞争:angry:,否则不必追求最佳召回率。
4) 导出
python export.py -w checkpoints/weight.pth --width 640 --height 384
这会自动创建一个ONNX权重文件和一个anchor_{H}_{W}.npy文件,用于后处理。使用示例请参考ROS部分。
训练技巧
锚框 :anchor:
如果您的数据集本质上与COCO或BDD100K不同,或者训练后的检测指标不如预期,您可以尝试在project.yml中启用自动锚框:
...
model:
image_size:
- 640
- 384
need_autoanchor: true # 设置为true以运行自动锚框
pin_memory: false
...
这会自动为您的数据集找到最佳的锚框比例和锚框比率组合。然后您可以手动编辑project.yml并禁用自动锚框。
如果您想碰碰运气,可以尝试修改backbone.py中的base_anchor_scale:
class HybridNetsBackbone(nn.Module):
...
self.pyramid_levels = [5, 5, 5, 5, 5, 5, 5, 5, 6]
self.anchor_scale = [1.25,1.25,1.25,1.25,1.25,1.25,1.25,1.25,1.25,]
self.aspect_ratios = kwargs.get('ratios', [(1.0, 1.0), (1.4, 0.7), (0.7, 1.4)])
...
以及model.py:
class Anchors(nn.Module):
...
for scale, ratio in itertools.product(self.scales, self.ratios):
base_anchor_size = self.anchor_scale * stride * scale
anchor_size_x_2 = base_anchor_size * ratio[0] / 2.0
anchor_size_y_2 = base_anchor_size * ratio[1] / 2.0
...
以了解锚框的工作原理。
一图胜千言,您可以使用锚框计算工具来可视化您的锚框。
训练阶段
我们尝试了不同的训练阶段,发现以下设置效果最佳:
--freeze_seg True~ 200轮--freeze_backbone True --freeze_det True~ 50轮- 端到端训练 ~ 50轮
原因是检测头在早期较难收敛,所以我们基本上跳过了分割头,先专注于检测。
结果
交通物体检测
| 结果 | 可视化 | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|


可行驶区域分割
| 结果 | 可视化 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
 
|
车道线检测
| 结果 | 可视化 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|



原始视频 由 Hanoi Life 提供
许可证
根据MIT许可证分发。更多信息请参见LICENSE。
致谢
没有以下作者的出色工作,我们的工作将无法完成:
引用
如果您认为我们的论文和代码对您的研究有用,请考虑给予星星 :star: 和引用 :pencil: :
@misc{vu2022hybridnets,
title={HybridNets: End-to-End Perception Network},
author={Dat Vu and Bao Ngo and Hung Phan},
year={2022},
eprint={2203.09035},
archivePrefix={arXiv},
primaryClass={cs.CV}
}











