
 访问官网
访问官网 Github
Github 文档
文档 论文
论文
 Jupyter Scatter
Jupyter Scatter






功能?
- 🖱️ 交互性:通过鼠标或 Python API 交互式地平移、缩放和选择数据点。
- 🚀 可扩展性:借助 WebGL 渲染,可流畅绘制多达数百万个数据点。
- 🔗 互联性:在多个散点图实例之间同步视图、悬停和选择。
- ✨ 有效默认值:依赖 Jupyter Scatter 默认选择感知有效的点颜色和不透明度。
- 📚 友好 API:享受与 Pandas DataFrames 深度集成的可读 API。
- 🛠️ 可集成性:通过观察其 traitlets 在自己的小部件中使用 Jupyter Scatter。
为什么?
想象一下,尝试以 2D 散点图的形式探索数百万个数据点的数据集。除了绘图,探索通常涉及三个方面:首先,我们希望交互式地调整视图(例如,通过平移和缩放)和视觉点编码(例如,点的颜色、不透明度或大小)。其次,我们希望能够选择和突出显示数据点。第三,我们希望比较多个数据集或同一数据集的多个视图(例如,通过同步交互)。jupyter-scatter 的目标是支持这三个要求,并可扩展到数百万个点。
如何实现?
在内部,Jupyter Scatter 使用 regl-scatterplot 进行 WebGL 渲染,使用 traitlets 实现 JS 和 iPython 内核之间的双向通信,并使用 anywidget 组合小部件。
目录
安装
pip install jupyter-scatter
如果你使用的是 JupyterLab <=2:
jupyter labextension install @jupyter-widgets/jupyterlab-manager jupyter-scatter
有关最小工作示例,请查看 test-environments。
入门
[!提示] 访问 jupyter-scatter.dev 了解 Jupyter Scatter 所有基本功能的详细信息,并查看我们来自 SciPy '23 的全面教程。
最简单的示例
在最简单的情况下,你可以按如下方式将 x/y 坐标传递给绘图函数:
import jscatter
import numpy as np
x = np.random.rand(500)
y = np.random.rand(500)
jscatter.plot(x, y)

Pandas 示例
假设你的数据存储在如下所示的 Pandas 数据框中:
import pandas as pd
# 只是一些随机的浮点数和整数值
data = np.random.rand(500, 4)
df = pd.DataFrame(data, columns=['mass', 'speed', 'pval', 'group'])
# 我们将 `group` 列转换为字符串,以确保它被识别为分类数据。
# 这在高级示例中会很有用。
df['group'] = df['group'].map(lambda c: chr(65 + round(c)), na_action=None)
| x | y | value | group | |
|---|---|---|---|---|
| 0 | 0.13 | 0.27 | 0.51 | G |
| 1 | 0.87 | 0.93 | 0.80 | B |
| 2 | 0.10 | 0.25 | 0.25 | F |
| 3 | 0.03 | 0.90 | 0.01 | G |
| 4 | 0.19 | 0.78 | 0.65 | D |
然后,你可以通过引用列名来可视化这些数据:
jscatter.plot(data=df, x='mass', y='speed')
显示结果散点图

高级示例
通常,你想要自定义视觉编码,例如点的颜色、大小和不透明度。
jscatter.plot(
data=df,
x='mass',
y='speed',
size=8, # 静态编码
color_by='group', # 数据驱动编码
opacity_by='density', # 视图驱动编码
)

在上面的示例中,我们选择了静态点大小为 8。相比之下,点的颜色是数据驱动的,根据分类 group 值分配。点的不透明度是视图驱动的,由当前视图中可见的点数动态定义。
还要注意 jscatter 如何根据用于颜色编码的数据类型默认使用适当的颜色映射。在这个示例中,由于数据类型为 categorical 且类别数少于 9,jscatter 使用了来自 Okabe 和 Ito 的色盲安全色图。
**重要提示:**为了让 jscatter 识别分类数据,相应列的 dtype 需要是 category!
当然,你可以自定义颜色映射和许多其他视觉编码参数,如下所示。
函数式 API 示例
当你想要自定义大量属性时,平面 API 可能会变得overwhelming。因此,jscatter 提供了一个函数式 API,按类型对属性进行分组,并通过具有意义的命名方法暴露它们。
scatter = jscatter.Scatter(data=df, x='mass', y='speed')
scatter.selection(df.query('mass < 0.5').index)
scatter.color(by='mass', map='plasma', order='reverse')
scatter.opacity(by='density')
scatter.size(by='pval', map=[2, 4, 6, 8, 10])
scatter.height(480)
scatter.background('black')
scatter.show()
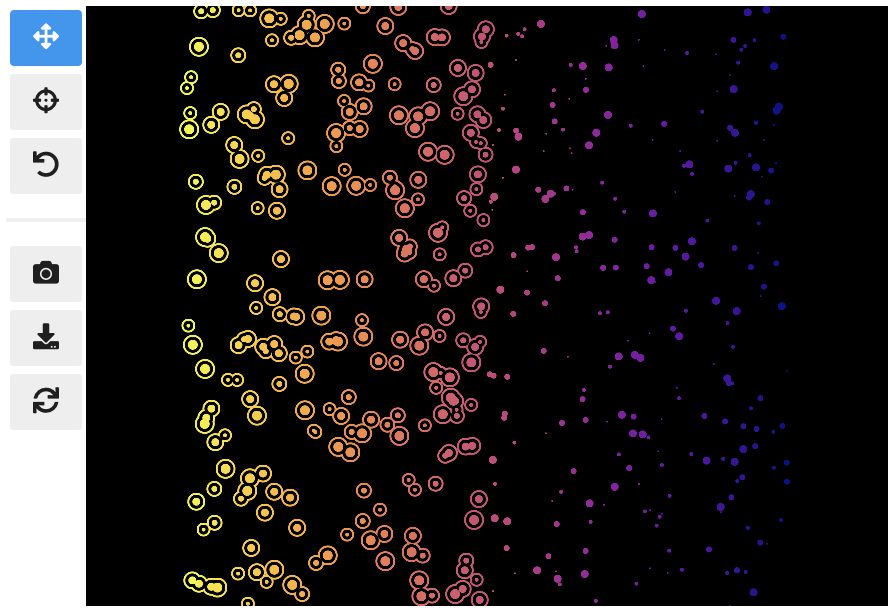
当你动态更新属性时,即在调用 scatter.show() 之后,图表将自动更新。例如,尝试调用 scatter.xy('speed', 'mass'),你会看到点沿对角线镜像。
此外,所有参数都是可选的。如果你指定参数,这些方法将作为设置器并更改属性。如果你不带任何参数调用方法,它将作为获取器并返回属性(或多个属性)。例如,scatter.selection() 将返回当前选中的点。
最后,散点图是交互式的,支持双向通信。因此,如果你用套索工具选择一些点,然后调用 scatter.selection(),你将获得当前的选择。
链接散点图
要探索多个散点图并链接它们的视图、选择和悬停交互,请使用 jscatter.link()。
jscatter.link([
jscatter.Scatter(data=embeddings, x='pcaX', y='pcaY', **config),
jscatter.Scatter(data=embeddings, x='tsneX', y='tsneY', **config),
jscatter.Scatter(data=embeddings, x='umapX', y='umapY', **config),
jscatter.Scatter(data=embeddings, x='caeX', y='caeY', **config)
], rows=2)
https://user-images.githubusercontent.com/932103/162584133-85789d40-04f5-428d-b12c-7718f324fb39.mp4
更多详情请参见 notebooks/linking.ipynb。
可视化数百万数据点
使用 jupyter-scatter,你可以轻松地可视化和交互式地探索包含数百万点的数据集。
在下面的例子中,我们正在可视化使用 Rössler 吸引子 生成的 500 万个点。
points = np.asarray(roesslerAttractor(5000000))
jscatter.plot(points[:,0], points[:,1], height=640)
https://user-images.githubusercontent.com/932103/162586987-0b5313b0-befd-4bd1-8ef5-13332d8b15d1.mp4
更多详情请参见 notebooks/examples.ipynb。
Google Colab
虽然 jscatter 主要是为 Jupyter Lab 和 Notebook 开发的,但它在 Google Colab 中也能正常运行。示例请参见 jupyter-scatter-colab-test.ipynb。
开发
设置开发环境
要求:
- Hatch >= 1.7.0
安装:
git clone https://github.com/flekschas/jupyter-scatter/ jscatter && cd jscatter
hatch shell
pip install -e ".[dev]"
修改 Python 代码后: 重启内核。
或者,你可以通过启用 autoreload 扩展来启用自动重新加载。为此,在笔记本开头运行以下代码:
%load_ext autoreload
%autoreload 2
修改 JavaScript 代码后: 执行 cd js && npm run build。
或者,你可以运行 npm run watch 并动态重新打包代码。
引用
如果你在研究中使用 Jupyter Scatter,请引用以下预印本:
@article{lekschas2024jupyter,
title = {Jupyter Scatter: Interactive Exploration of Large-Scale Datasets},
url = {https://arxiv.org/abs/2406.14397},
doi = {10.48550/arXiv.2406.14397},
publisher = {arXiv},
journal = {arXiv},
author = {Lekschas, Fritz and Manz, Trevor},
year = {2024},
month = {6},
}











