
 访问官网
访问官网 Github
Github 文档
文档 论文
论文大海捞针 - 对大语言模型进行压力测试
一个简单的"大海捞针"分析,用于测试长上下文大语言模型的上下文检索能力。
支持的模型提供商:OpenAI、Anthropic、Cohere
在概述视频中了解幕后细节。
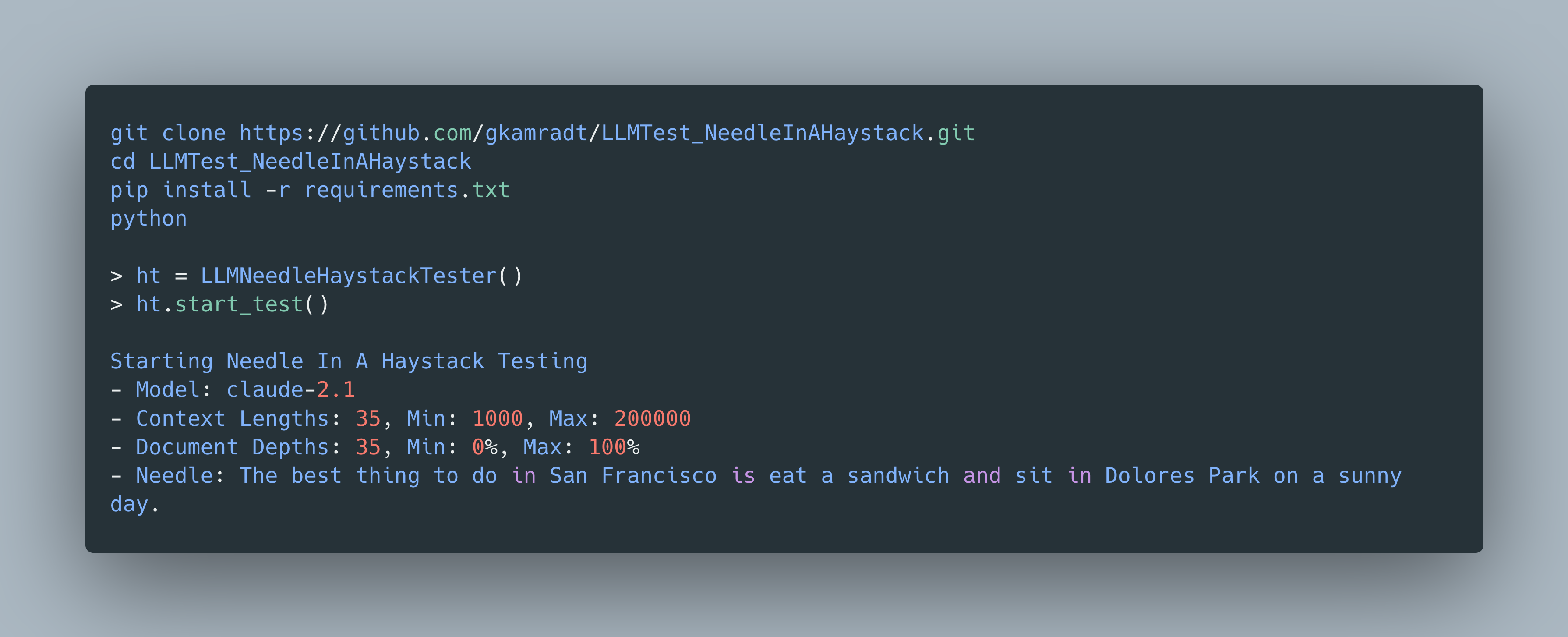
测试方法
- 在长上下文窗口(即"干草堆")的中间放置一个随机事实或陈述(即"针")
- 要求模型检索这个陈述
- 通过改变文档深度(针的位置)和上下文长度来迭代测量性能
这是支持这个OpenAI和Anthropic分析的代码。
原始测试的结果在/original_results中。由于脚本自那些测试运行以来已经大幅升级,数据格式可能与您的脚本结果不匹配。
开始使用
设置虚拟环境
我们建议设置一个虚拟环境来隔离Python依赖,确保项目特定的包不会与系统范围的安装冲突。
python3 -m venv venv
source venv/bin/activate
环境变量
NIAH_MODEL_API_KEY- 用于与模型交互的API密钥。根据提供商的不同,这将与正确的SDK一起适当使用。NIAH_EVALUATOR_API_KEY- 如果使用openai评估策略,则使用此API密钥。
安装包
从PyPi安装包:
pip install needlehaystack
运行测试
通过从命令行调用入口点needlehaystack.run_test开始使用该包。
然后,您可以使用以下命令行参数在OpenAI、Anthropic或Cohere模型上运行分析:
provider- 模型的提供商,可用选项为openai、anthropic和cohere。默认为openaievaluator- 评估器,可以是model或LangSmith。关于LangSmith的更多信息见下文。如果使用model,目前只支持openai。默认为openai。model_name- 提供商可访问的语言模型的模型名称。默认为gpt-3.5-turbo-0125evaluator_model_name- 评估器可访问的语言模型的模型名称。默认为gpt-3.5-turbo-0125
此外,LLMNeedleHaystackTester参数也可以作为命令行参数传递,除了model_to_test和evaluator。
以下是一些示例用例。
以下命令为openai模型gpt-3.5-turbo-0125运行测试,上下文长度为2000,文档深度为50%。
needlehaystack.run_test --provider openai --model_name "gpt-3.5-turbo-0125" --document_depth_percents "[50]" --context_lengths "[2000]"
以下命令为anthropic模型claude-2.1运行测试,上下文长度为2000,文档深度为50%。
needlehaystack.run_test --provider anthropic --model_name "claude-2.1" --document_depth_percents "[50]" --context_lengths "[2000]"
以下命令为cohere模型command-r运行测试,上下文长度为2000,文档深度为50%。
needlehaystack.run_test --provider cohere --model_name "command-r" --document_depth_percents "[50]" --context_lengths "[2000]"
对于贡献者
- Fork并克隆仓库。
- 按上述说明创建并激活虚拟环境。
- 按上述说明设置环境变量。
- 通过从仓库根目录运行以下命令以可编辑模式安装包:
pip install -e .
包needlehaystack可在您的测试用例中导入。进行开发、更改并在本地测试。
LLMNeedleHaystackTester参数:
model_to_test- 运行大海捞针测试的模型。默认为None。evaluator- 评估模型响应的评估器。默认为None。needle- 将放置在上下文("干草堆")中的陈述或事实haystack_dir- 包含要加载作为背景上下文的文本文件的目录。仅支持文本文件retrieval_question- 用于在背景上下文中检索针的问题results_version- 如果您想为相同的长度/深度组合多次运行测试,请更改版本号num_concurrent_requests- 默认:1。如果您想并行运行更多请求,请设置更高的值。请注意速率限制。save_results- 是否将结果保存到文件。无论如何,它们都会暂时保存在对象中。True/False。如果save_results = True,则此脚本将填充一个result/目录,其中包含评估信息。由于潜在的并发请求,每个新测试都将保存为几个文件。save_contexts- 是否将上下文保存到文件。警告这些文件会变得非常长。True/Falsefinal_context_length_buffer- 从每个输入中删除的上下文数量,以考虑系统消息和输出标记。这可以更智能,但暂时使用静态值。默认200个标记。context_lengths_min- 要迭代的上下文长度列表的起点context_lengths_max- 要迭代的上下文长度列表的终点context_lengths_num_intervals- 在最小/最大值之间迭代的间隔数context_lengths- 自定义的上下文长度集。如果设置,这将覆盖为context_lengths_min、max和intervals设置的值document_depth_percent_min- 文档深度的起点。应为大于0的整数document_depth_percent_max- 文档深度的终点。应为小于100的整数document_depth_percent_intervals- 在最小/最大点之间进行迭代的次数document_depth_percents- 自定义的文档深度长度集。如果设置,这将覆盖为document_depth_percent_min、max和intervals设置的值document_depth_percent_interval_type- 确定要迭代的深度分布。'linear'或'sigmoid'seconds_to_sleep_between_completions- 默认:None,如果您想减慢请求速度,请设置秒数print_ongoing_status- 默认:True,是否打印测试完成时的状态
LLMMultiNeedleHaystackTester参数:
multi_needle- True或False,是否运行多针测试needles- 要插入上下文的针的列表
其他参数:
model_name- 您想使用的模型的名称。应与需要传递给API的确切值匹配。例如:对于OpenAI推理和评估器模型,它将是gpt-3.5-turbo-0125。
结果可视化
LLMNeedleInHaystackVisualization.ipynb文件包含了制作数据透视表可视化的代码。数据透视表随后被转移到Google幻灯片中进行自定义注释和格式设置。可以查看Google幻灯片版本。关于这个可视化是如何创建的概述可以在这里查看。
OpenAI的GPT-4-128K(2023年11月8日运行)

Anthropic的Claude 2.1(2023年11月21日运行)

多针评估器
要在我们的上下文中启用多针插入,使用--multi_needle True。
这会在指定的depth_percent处插入第一个针,然后在此深度之后的剩余上下文中均匀分布后续的针。
为了均匀间隔,它计算depth_percent_interval如下:
depth_percent_interval = (100 - depth_percent) / len(self.needles)
因此,第一个针放置在depth_percent的深度百分比处,第二个针在depth_percent + depth_percent_interval处,第三个针在depth_percent + 2 * depth_percent_interval处,以此类推。
以下示例展示了10个针和40%深度百分比情况下的深度百分比:
depth_percent_interval = (100 - 40) / 10 = 6
针1:40
针2:40 + 6 = 46
针3:40 + 2 * 6 = 52
针4:40 + 3 * 6 = 58
针5:40 + 4 * 6 = 64
针6:40 + 5 * 6 = 70
针7:40 + 6 * 6 = 76
针8:40 + 7 * 6 = 82
针9:40 + 8 * 6 = 88
针10:40 + 9 * 6 = 94
LangSmith评估器
你可以使用LangSmith来编排评估并存储结果。
(1) 注册LangSmith
(2) 按照设置中的说明设置LangSmith的环境变量。
(3) 在"Datasets + Testing"标签页中,使用"+ Dataset"创建一个新数据集,先将其命名为multi-needle-eval-sf。
(4) 用测试问题填充数据集:
问题:旧金山最值得做的5件事是什么?
答案:"旧金山最值得做的5件事是:1)去多洛雷斯公园。2)在Tony's Pizza Napoletana吃饭。3)参观恶魔岛。4)爬上双子峰。5)骑自行车穿过金门大桥"
(5) 使用
--evaluator langsmith和--eval_set multi-needle-eval-sf运行,以针对我们最近创建的评估集进行测试。
让我们看看这些在一个新数据集multi-needle-eval-pizza上如何一起工作。
这是multi-needle-eval-pizza评估集,包含一个问题和参考答案。你还可以查看结果运行:
https://smith.langchain.com/public/74d2af1c-333d-4a73-87bc-a837f8f0f65c/d
以下是使用多针评估并传递相关针的运行命令:
needlehaystack.run_test --evaluator langsmith --context_lengths_num_intervals 3 --document_depth_percent_intervals 3 --provider openai --model_name "gpt-4-0125-preview" --multi_needle True --eval_set multi-needle-eval-pizza --needles '["无花果是三种最美味的比萨配料之一。", "意大利熏火腿是三种最美味的比萨配料之一。", "山羊奶酪是三种最美味的比萨配料之一。"]'
许可证
本项目采用MIT许可证 - 详见LICENSE文件。使用本软件需要注明原作者和项目,如许可证中所详述。











