
 访问官网
访问官网 Github
Github 论文
论文隐式行为克隆
本代码库包含我们论文中*隐式行为克隆(IBC)*算法的官方实现:
隐式行为克隆 (网站链接) (arXiv链接)
Pete Florence, Corey Lynch, Andy Zeng, Oscar Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, Jonathan Tompson
2021年机器人学习会议(CoRL)
 | 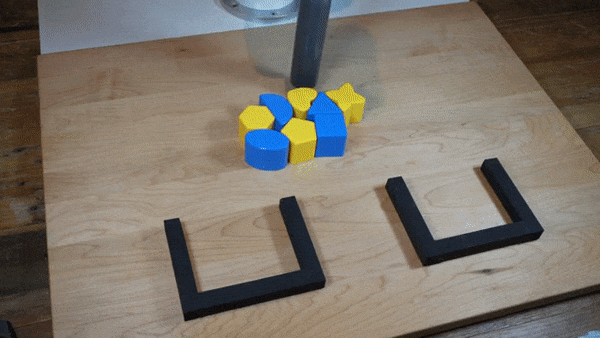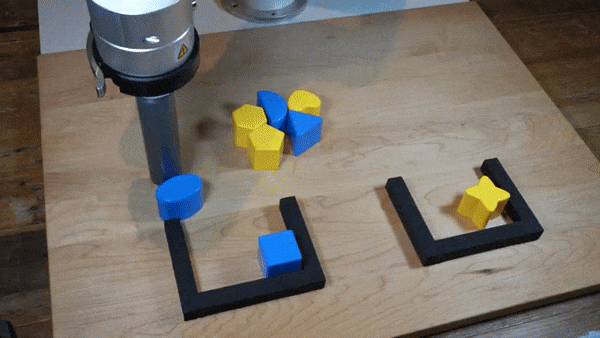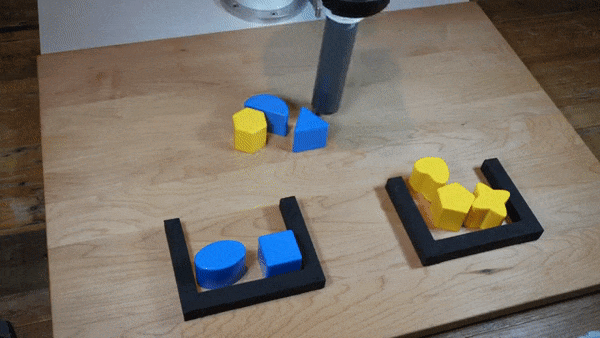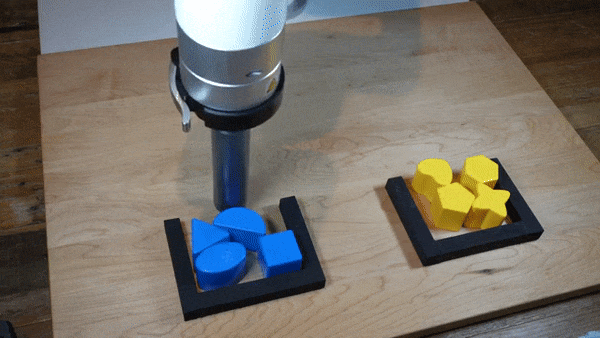 |
|---|
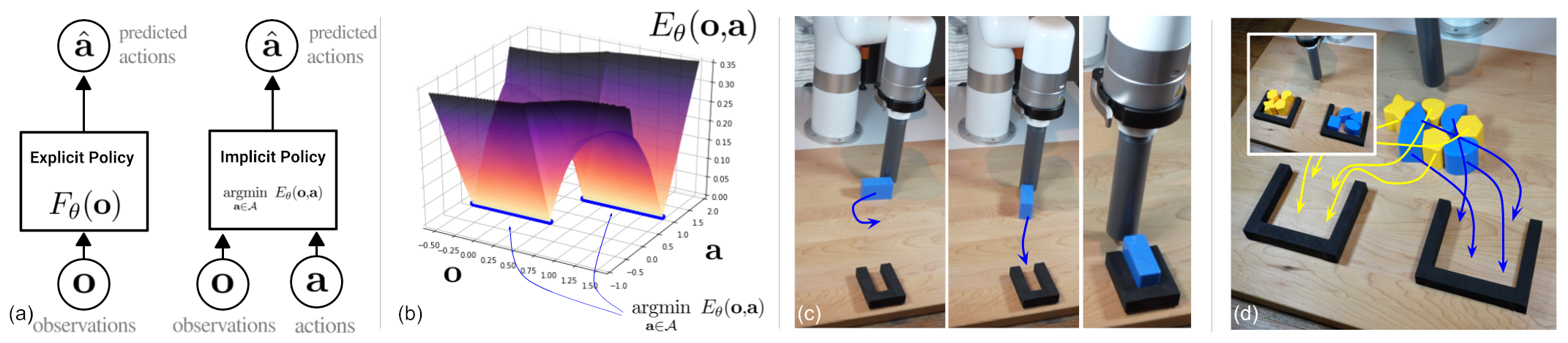
摘要
我们发现,在广泛的机器人策略学习场景中,使用隐式模型进行监督策略学习通常比常用的显式模型表现更好。我们对这一发现进行了大量实验,并提供了直观的见解和理论论证,区分了隐式模型与其显式对应物的特性,特别是在近似复杂的、可能不连续和多值(集值)函数方面。在机器人策略学习任务中,我们表明基于能量的模型(EBM)的隐式行为克隆策略通常优于常见的显式(均方误差或混合密度)行为克隆策略,包括在具有高维动作空间和视觉图像输入的任务上。我们发现,这些策略在具有挑战性的D4RL基准套件中的人类专家任务上提供了具有竞争力的结果或优于最先进的离线强化学习方法,尽管没有使用任何奖励信息。在现实世界中,具有隐式策略的机器人可以从人类演示中学习复杂且非常微妙的行为,包括具有高组合复杂性的任务和需要1毫米精度的任务。
先决条件
本项目的代码使用Python 3.7+和以下pip包:
python3 -m pip install --upgrade pip
pip install \
absl-py==0.12.0 \
gin-config==0.4.0 \
matplotlib==3.4.3 \
mediapy==1.0.3 \
opencv-python==4.5.3.56 \
pybullet==3.1.6 \
scipy==1.7.1 \
tensorflow==2.6.0 \
keras==2.6.0 \
tf-agents==0.11.0rc0 \
tqdm==4.62.2
(可选):对于Mujoco支持,请参阅docs/mujoco_setup.md。除非您特别想运行Adroit和Kitchen环境,否则建议跳过。
快速入门:10分钟内从0到训练好的IBC策略
第1步: 安装上面先决条件中列出的Python包。
第2步: 运行单元测试(应该不到一分钟),并在顶级ibc目录上方的目录中执行此操作:
./ibc/run_tests.sh
第3步: 检查Tensorflow是否可以访问GPU:
python3 -c "import tensorflow as tf; print(tf.test.is_gpu_available())"
如果上面打印False,请参阅以下要求,特别是CUDA 11.2和cuDNN 8.1.0: https://www.tensorflow.org/install/gpu#software_requirements。
第4步: 让我们以推块任务为例,首先下载预定义数据(或参见任务了解如何生成):
cd ibc/data
wget https://storage.googleapis.com/brain-reach-public/ibc_data/block_push_states_location.zip
unzip block_push_states_location.zip && rm block_push_states_location.zip
cd ../..
第5步: 将PYTHONPATH设置为包含顶级ibc上方的目录,如果您一直按照上面的命令操作,则为:
export PYTHONPATH=$PYTHONPATH:${PWD}
第6步: 在该推块任务示例上,我们接下来将使用隐式BC进行训练+评估:
./ibc/ibc/configs/pushing_states/run_mlp_ebm.sh
一些注意事项:
- 在一个示例单GPU机器(GTX 2080 Ti)上,上述训练速度约为18步/秒,应该在5,000或10,000步内达到高成功率(大约5-10分钟的训练时间)。
mlp_ebm.gin只是一个配置,旨在提供相当快的训练速度,每个间隔只有20次评估,不适用于所有任务。有关更多配置,请参见任务。- 由于上面的
--video标志,您可以在以下位置观看学习到的策略的视频:/tmp/ibc_logs/mlp_ebm/ibc_dfo/...导航到videos/ttl=7d子文件夹,默认情况下,每次进行评估间隔时,应该保存一个示例.mp4视频。
(可选)第7步: 对于基于pybullet的任务,我们还通过可视化服务器设置了实时交互式可视化,因此在一个终端中:
cd <path_to>/ibc/..
export PYTHONPATH=$PYTHONPATH:${PWD}
python3 -m pybullet_utils.runServer
在另一个终端中使用--shared_memory标志运行几次预定义策略:
cd <path_to>/ibc/..
export PYTHONPATH=$PYTHONPATH:${PWD}
python3 ibc/data/policy_eval.py -- \
--alsologtostderr \
--shared_memory \
--num_episodes=3 \
--policy=oracle_push \
--task=PUSH
快速入门到此结束! 请参阅下面的任务,还可以查看docs/codebase_overview.md和docs/workflow.md以获取更多信息。
任务
任务:粒子
在这个任务中,目标是让智能体(黑点)先到达绿点,然后再到达蓝点。
| 示例 IBC 策略 | 示例 MSE 策略 |
|---|---|
 | 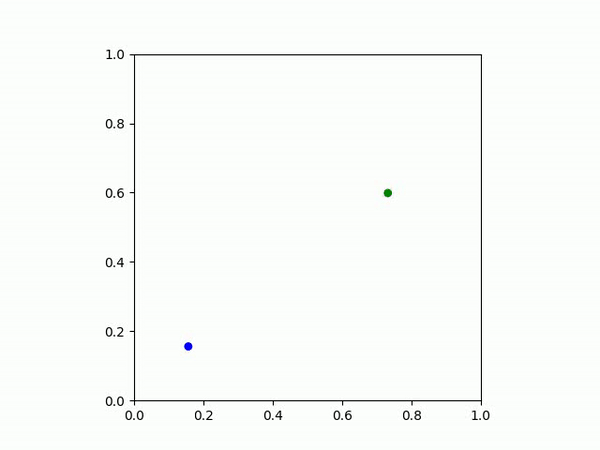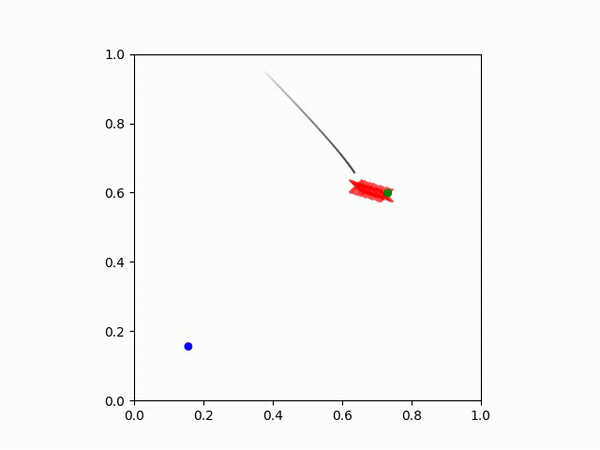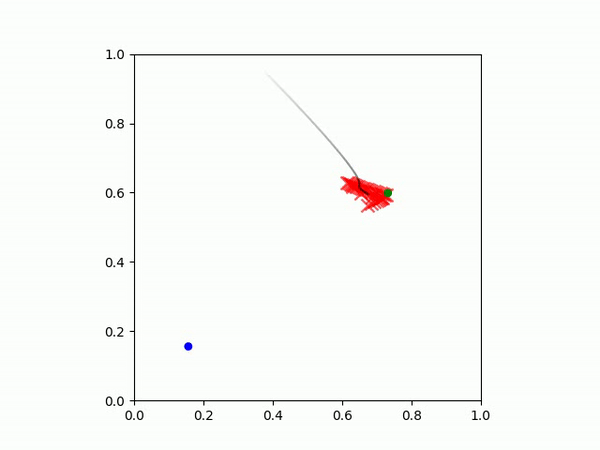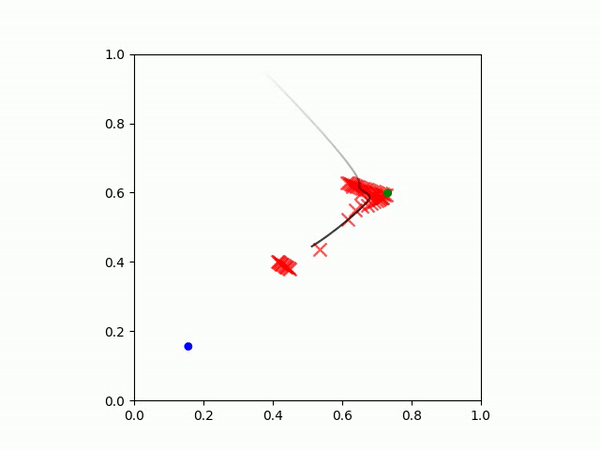 |
获取数据
我们可以从头开始生成数据,例如对于2D环境(需要15秒):
./ibc/ibc/configs/particle/collect_data.sh
或者直接下载所有不同维度的数据:
cd ibc/data/
wget https://storage.googleapis.com/brain-reach-public/ibc_data/particle.zip
unzip particle.zip && rm particle.zip
cd ../..
训练和评估
让我们从一些小型网络开始,仅在2D版本上进行测试,因为它最容易可视化,并比较MSE和IBC。以下是一个小型网络(256x2)的IBC-with-Langevin配置,其中'2'是环境维度的参数。
./ibc/ibc/configs/particle/run_mlp_ebm_langevin.sh 2
这是一个相同大小的网络(256x2),但使用MSE配置:
./ibc/ibc/configs/particle/run_mlp_mse.sh 2
对于上述配置,我们建议比较rollout视频,你可以在'/tmp/ibc_logs/...corresponding_directory../videos/'中找到。本节顶部展示了两种不同配置在10,000训练步骤后的对比。
以下是分别用于16维环境的IBC(使用langevin)和MSE的最佳配置:
./ibc/ibc/configs/particle/run_mlp_ebm_langevin_best.sh 16
./ibc/ibc/configs/particle/run_mlp_mse_best.sh 16
注意:对于Langevin来说,*_best*配置训练起来有点慢,但即使是./ibc/ibc/configs/particle/run_mlp_ebm_langevin.sh 16(较小的网络)似乎也能很好地解决16维环境,而且训练速度快得多。
任务:推块(从状态观察)
获取数据
我们可以从头开始生成数据(~2分钟生成2,000个episode:10个副本,每个200个):
./ibc/ibc/configs/pushing_states/collect_data.sh
或者我们可以从网上下载数据:
cd ibc/data/
wget https://storage.googleapis.com/brain-reach-public/ibc_data/block_push_states_location.zip
unzip 'block_push_states_location.zip' && rm block_push_states_location.zip
cd ../..
训练和评估
这是一个训练速度相当快的IBC与DFO配置:
./ibc/ibc/configs/pushing_states/run_mlp_ebm.sh
或者这是IBC与Langevin的配置:
./ibc/ibc/configs/pushing_states/run_mlp_ebm_langevin.sh
或者这是一个可比较的、训练速度相当快的MSE配置:
./ibc/ibc/configs/pushing_states/run_mlp_mse.sh
或者分别运行IBC、MSE和MDN的最佳配置(其中一些可能比上面的训练速度慢):
./ibc/ibc/configs/pushing_states/run_mlp_ebm_best.sh
./ibc/ibc/configs/pushing_states/run_mlp_mse_best.sh
./ibc/ibc/configs/pushing_states/run_mlp_mdn_best.sh
任务:推块(从图像观察)
获取数据
从网上下载数据:
cd ibc/data/
wget https://storage.googleapis.com/brain-reach-public/ibc_data/block_push_visual_location.zip
unzip 'block_push_visual_location.zip' && rm block_push_visual_location.zip
cd ../..
训练和评估
这是一个IBC与Langevin的配置,它实际上应该比我们在论文中报告的IBC-with-DFO收敛得更快:
./ibc/ibc/configs/pushing_pixels/run_pixel_ebm_langevin.sh
以下分别是IBC(使用DFO)、MSE和MDN的最佳配置:
./ibc/ibc/configs/pushing_pixels/run_pixel_ebm_best.sh
./ibc/ibc/configs/pushing_pixels/run_pixel_mse_best.sh
./ibc/ibc/configs/pushing_pixels/run_pixel_mdn_best.sh
任务:D4RL Adroit和Kitchen
获取数据
论文提交时使用的D4RL人类示范训练数据可以通过以下命令下载。这些数据已从原始D4RL数据格式处理为.tfrecord格式:
cd ibc/data && mkdir -p d4rl_trajectories && cd d4rl_trajectories
wget https://storage.googleapis.com/brain-reach-public/ibc_data/door-human-v0.zip \
https://storage.googleapis.com/brain-reach-public/ibc_data/hammer-human-v0.zip \
https://storage.googleapis.com/brain-reach-public/ibc_data/kitchen-complete-v0.zip \
https://storage.googleapis.com/brain-reach-public/ibc_data/kitchen-mixed-v0.zip \
https://storage.googleapis.com/brain-reach-public/ibc_data/kitchen-partial-v0.zip \
https://storage.googleapis.com/brain-reach-public/ibc_data/pen-human-v0.zip \
https://storage.googleapis.com/brain-reach-public/ibc_data/relocate-human-v0.zip
unzip '*.zip' && rm *.zip
cd ../../..
运行训练评估:
以下分别是IBC(带Langevin)和MSE的最佳配置: 在2080 Ti GPU测试中,此IBC配置仅以1.7步/秒的速度训练,但在TPUv3上速度快约10倍。
./ibc/ibc/configs/d4rl/run_mlp_ebm_langevin_best.sh pen-human-v0
./ibc/ibc/configs/d4rl/run_mlp_mse_best.sh pen-human-v0
上述命令将在pen-human-v0环境中运行,但你可以将此参数替换为任何提供的Adroit/Kitchen环境。
这里还有一个MDN配置供你尝试。网络规模很小,但如果你大幅增加它,似乎在训练过程中会出现NaN值。总的来说,MDN可能会很棘手。不过应该有解决方案。
./ibc/ibc/configs/d4rl/run_mlp_mdn.sh pen-human-v0
复现结果摘要
对于我们能够开源的任务,论文中的结果应该可以通过使用下面链接的数据和命令行参数来复现。
| 任务 | 论文中的图表 | 数据 | 训练+评估命令 |
|---|---|---|---|
| 坐标回归 | 图4 | 见colab | 见colab |
| D4RL Adroit + Kitchen | 表2 | 链接 | 链接 |
| N维粒子 | 图6 | 链接 | 链接 |
| 模拟推动,单一目标,状态 | 表3 | 链接 | 链接 |
| 模拟推动,单一目标,像素 | 表3 | 链接 | 链接 |
引用
如果你在研究中发现我们的论文/代码有用,请考虑引用:
@article{florence2021implicit,
title={Implicit Behavioral Cloning},
author={Florence, Pete and Lynch, Corey and Zeng, Andy and Ramirez, Oscar and Wahid, Ayzaan and Downs, Laura and Wong, Adrian and Lee, Johnny and Mordatch, Igor and Tompson, Jonathan},
journal={Conference on Robot Learning (CoRL)},
month = {November},
year={2021}
}











