
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文CameraCtrl
本仓库是 CameraCtrl 的官方实现。
此 main 分支包含在 AnimateDiffV3 上实现的 CameraCtrl 的代码和模型。关于 CameraCtrl 与稳定视频扩散的代码和模型,请参阅 svd 分支了解详情。
CameraCtrl: 为视频扩散模型启用摄像机控制
何昊、徐英豪、郭宇炜、Gordon Wetzstein、戴波、李弘升、杨策元
[论文] [项目页面] [权重] [HF演示]
待办事项
- 发布推理代码。
- 发布 AnimateDiffV3 上的预训练模型。
- 发布训练代码。
- 发布 Gradio 演示。
- 在
svd分支发布 SVD 上的预训练模型。
配置
环境
- 64位 Python 3.10 和 PyTorch 1.13.0 或更高版本。
- CUDA 11.7
- 用户可以使用以下命令安装软件包
conda env create -f environment.yaml
conda activate cameractrl
数据集
- 从 RealEstate10K 下载摄像机轨迹和视频。
- 运行
tools/gather_realestate.py获取每个视频的所有片段。 - 运行
tools/get_realestate_clips.py从原始视频中获取视频片段。 - 使用 LAVIS 或其他方法为每个视频片段生成说明文本。我们在 Google Drive 和 Google Drive 提供了我们提取的说明文本。
- 运行
tools/generate_realestate_json.py生成用于训练和测试的 json 文件,你可以通过从训练 json 文件中随机抽样一些项目来构建验证 json 文件。 - 完成上述步骤后,你可以得到如下结构的数据集文件夹
- RealEstate10k
- annotations
- test.json
- train.json
- validation.json
- pose_files
- 0000cc6d8b108390.txt
- 00028da87cc5a4c4.txt
- 0002b126b0a8a685.txt
- 0003a9bce989e532.txt
- 000465ebe46a98d2.txt
- ...
- video_clips
- 00ccbtp2aSQ
- 00rMZpGSeOI
- 01bTY_glskw
- 01PJ3skCZPo
- 01uaDoluhzo
- ...
推理
准备模型
- 从 HuggingFace 下载 Stable Diffusion V1.5 (SD1.5)。
- 从 AnimateDiff 下载 AnimateDiffV3 (ADV3) 适配器和运动模块的检查点。
- 从 HuggingFace 下载预训练的摄像机控制模型。
- 运行
tools/merge_lora2unet.py将 ADV3 适配器权重合并到 SD1.5 unet 中,并将结果保存到 SD1.5 文件夹下的新子文件夹中(如unet_webvidlora_v3)。 - (可选)从 HuggingFace 下载在 RealEstate10K 数据集上预训练的图像 LoRA 模型,以在室内和室外房产上采样视频。
- (可选)从 CivitAI 下载个性化基础模型,如 Realistic Vision。
准备摄像机轨迹和提示
- 采用
tools/select_realestate_clips.py准备轨迹 txt 文件,一些示例轨迹和相应的参考视频分别在assets/pose_files和assets/reference_videos中。生成的轨迹可以用tools/visualize_trajectory.py可视化。 - 准备提示(负面提示,特定种子),一个示例是
assets/cameractrl_prompts.json。
推理
- 运行
inference.py采样视频
python -m torch.distributed.launch --nproc_per_node=8 --master_port=25000 inference.py \
--out_root ${OUTPUT_PATH} \
--ori_model_path ${SD1.5_PATH} \
--unet_subfolder ${SUBFOUDER_NAME} \
--motion_module_ckpt ${ADV3_MM_CKPT} \
--pose_adaptor_ckpt ${CAMERACTRL_CKPT} \
--model_config configs/train_cameractrl/adv3_256_384_cameractrl_relora.yaml \
--visualization_captions assets/cameractrl_prompts.json \
--use_specific_seeds \
--trajectory_file assets/pose_files/0f47577ab3441480.txt \
--n_procs 8
其中
OUTPUT_PATH指保存结果的路径。SD1.5_PATH指下载的 SD1.5 模型的根路径。SUBFOUDER_NAME指SD1.5_PATH中 unet 的子文件夹名称,默认为unet。这里我们采用tools/merge_lora2unet.py指定的名称。ADV3_MM_CKPT指下载的 AnimateDiffV3 运动模块检查点的路径。CAMERACTRL_CKPT指
上述推理示例用于在原始 T2V 模型域中生成视频。inference.py 脚本支持使用图像 LoRA(args.image_lora_rank 和 args.image_lora_ckpt)在其他域中生成视频,如 RealEstate10K LoRA 或一些个性化基础模型(args.personalized_base_model),如 Realistic Vision。详情请参考代码。
结果
- 相同的文本提示,不同的相机轨迹
| 相机轨迹 | 视频 | 相机轨迹 | 视频 | 相机轨迹 | 视频 |
|---|---|---|---|---|---|
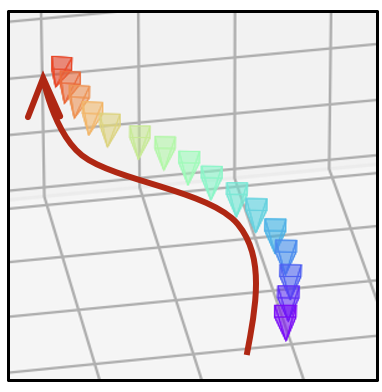 |  | 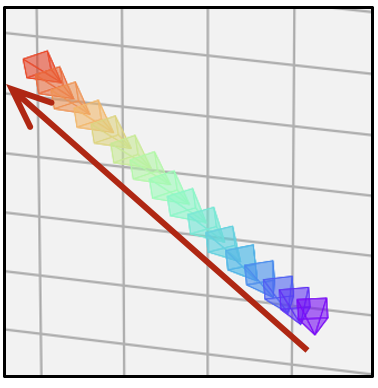 |  | 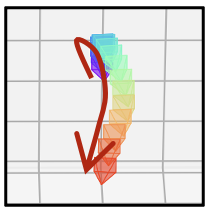 |  |
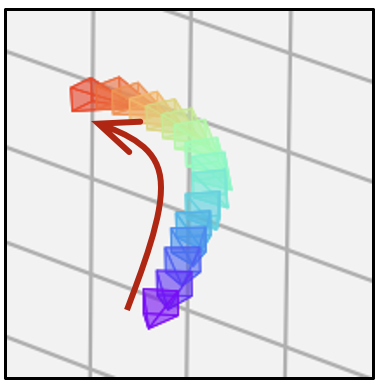 |  | 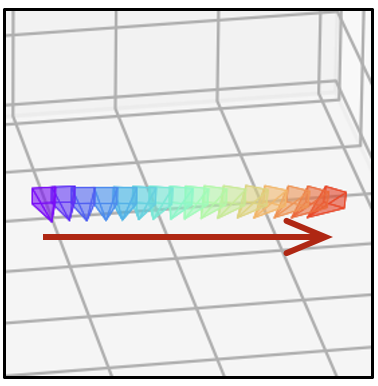 |  | 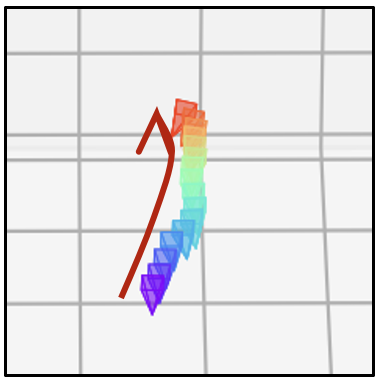 |  |
| 生成器 | 相机轨迹 | 视频 | 相机轨迹 | 视频 | 相机轨迹 | 视频 |
|---|---|---|---|---|---|---|
| SD1.5 | 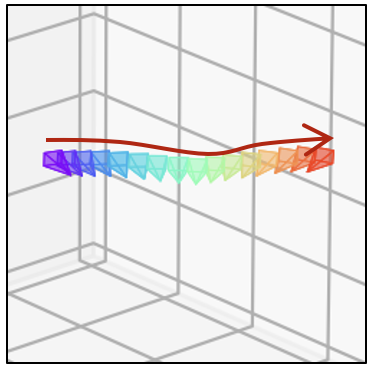 |  | 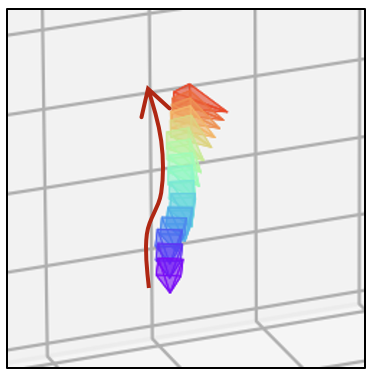 |  | 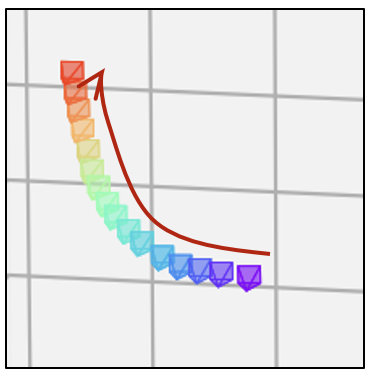 |  |
| SD1.5 + 房地产 LoRA | 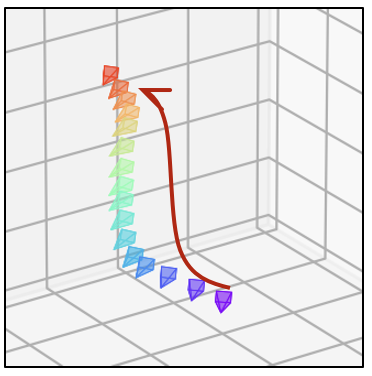 |  | 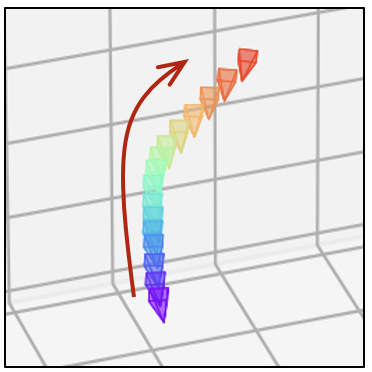 |  | 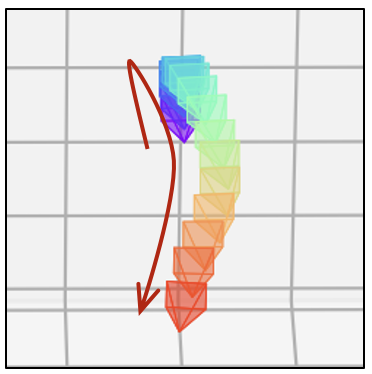 |  |
| 真实视觉 | 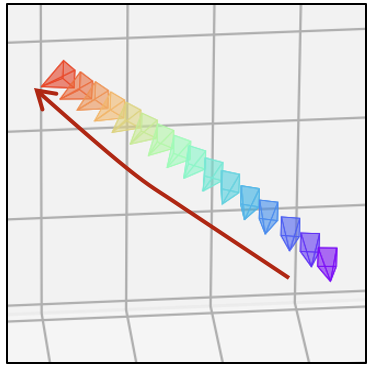 |  | 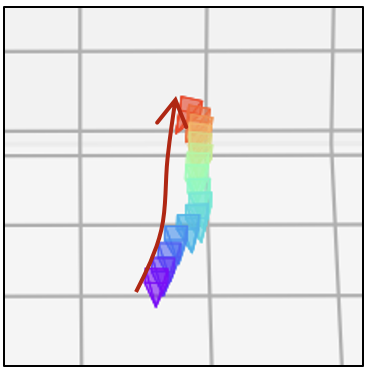 |  | 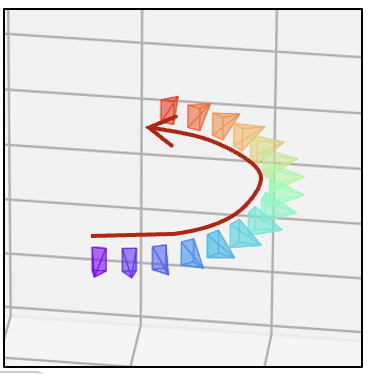 |  |
| 卡通风格 | 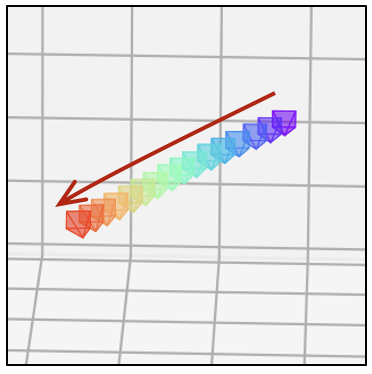 |  | 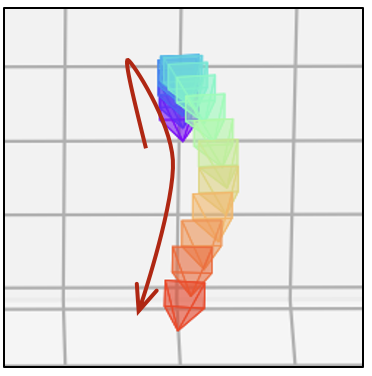 |  | 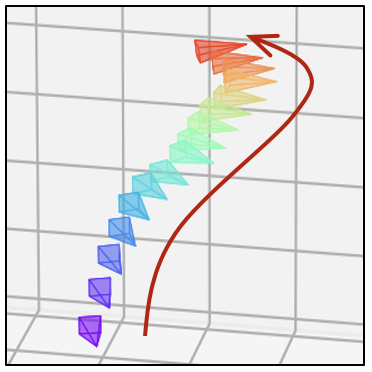 |  |
训练
步骤1(RealEstate10K 图像 LoRA)
更新配置文件 configs/train_image_lora/realestate_lora.yaml 中的以下数据和预训练模型路径
pretrained_model_path: "[替换为 SD1.5 根路径]"
train_data:
root_path: "[替换为 RealEstate10K 根路径]"
其他训练参数(学习率、轮数、验证设置等)也包含在配置文件中。
然后,使用 slurm 启动图像 LoRA 训练
./slurm_run.sh ${PARTITION} image_lora 8 configs/train_image_lora/realestate_lora.yaml train_image_lora.py
或使用 PyTorch
./dist_run.sh configs/train_image_lora/realestate_lora.yaml 8 train_image_lora.py
我们在 HuggingFace 上提供了我们预训练的 RealEstate10K LoRA 模型检查点。
步骤2(相机控制模型)
更新配置文件 configs/train_cameractrl/adv3_256_384_cameractrl_relora.yaml 中的以下数据和预训练模型路径
pretrained_model_path: "[替换为 SD1.5 根路径]"
train_data:
root_path: "[替换为 RealEstate10K 根路径]"
validation_data:
root_path: "[替换为 RealEstate10K 根路径]"
lora_ckpt: "[替换为 RealEstate10k 图像 LoRA 检查点]"
motion_module_ckpt: "[替换为 ADV3 运动模块]"
其他训练参数(学习率、轮数、验证设置等)也包含在配置文件中。
然后,使用 slurm 启动相机控制模型训练
./slurm_run.sh ${PARTITION} cameractrl 8 configs/train_cameractrl/adv3_256_384_cameractrl_relora.yaml train_camera_control.py
或使用 PyTorch
./dist_run.sh configs/train_cameractrl/adv3_256_384_cameractrl_relora.yaml 8 train_camera_control.py
免责声明
本项目仅供学术使用。我们对用户生成的内容不承担责任。用户对自己的行为完全负责。项目贡献者在法律上不隶属于用户,也不对用户的行为负责。请负责任地使用生成模型,遵守道德和法律标准。
致谢
我们感谢 AnimateDiff 提供的出色代码和模型。
BibTeX
@article{he2024cameractrl,
title={CameraCtrl: Enabling Camera Control for Text-to-Video Generation},
author={Hao He and Yinghao Xu and Yuwei Guo and Gordon Wetzstein and Bo Dai and Hongsheng Li and Ceyuan Yang},
journal={arXiv preprint arXiv:2404.02101},
year={2024}
}











