
 Github
Github 论文
论文CharacterBERT
这是COLING 2020发表的论文"CharacterBERT: 通过字符实现ELMo和BERT的词级开放词汇表示的调和"的代码仓库。
2021-02-25: 现在可以在这里找到预训练BERT和CharacterBERT的代码!
目录
论文概述
摘要
CharacterBERT是BERT的一个变体,它在词级生成上下文表示。
这是通过关注每个输入词元的字符并动态构建词元表示来实现的。事实上,与依赖预定义词片矩阵的标准BERT相比,这种方法使用类似于ELMo的CharacterCNN模块,可以为任意输入词元生成表示。

上图显示了BERT中如何构建与上下文无关的表示,以及CharacterBERT中如何构建这些表示。在这里,我们假设"Apple"是一个未知词元,这导致BERT将词元分割为两个词片"Ap"和"##ple"并嵌入每个单元。另一方面,CharacterBERT按原样处理词元"Apple",然后关注其字符以生成单个词元嵌入。
动机
CharacterBERT有两个主要动机:
-
通常通过简单地在一组专业语料库上重新训练来将原始
BERT适应新的专业领域(例如医学、法律、科学领域等)是很常见的。这导致原始(通用领域)词片词汇被重复使用,尽管最终模型实际上针对的是不同的潜在高度专业化领域,这可以说是次优的(参见论文的_第2节_)。在这种情况下,一个直接的解决方案是使用专业词片词汇从头开始训练一个新的BERT。然而,训练一个BERT已经足够昂贵了,更不用说需要为每个感兴趣的领域训练一个了。
-
BERT使用词片系统在词元的特异性和字符的灵活性之间取得良好平衡。然而,在实践中使用子词并不是最方便的(我们是否应该平均表示以获得原始词元嵌入用于词相似性任务?我们是否应该在序列标注任务中只使用每个词元的第一个词片?...)大多数人只是希望使用词元。
受ELMo的启发,我们使用CharacterCNN模块,成功获得了BERT的一个变体,该变体既产生词级又产生上下文表示,可以根据需要在任何领域进行多次重新调整,而无需担心任何词片的适用性。作为锦上添花,关注每个输入词元的字符还使我们得到一个对任何拼写错误或拼写错误更加鲁棒的模型(参见论文的_第5.5节_)。
如何使用CharacterBERT?
安装
我们建议使用专门用于CharacterBERT的虚拟环境。
如果你还没有安装conda,可以从此链接安装Miniconda。然后,检查你的conda是否是最新的:
conda update -n base -c defaults conda
创建一个新的conda环境:
conda create python=3.10 --name=character-bert
如果尚未激活,请使用以下命令激活新的conda环境:
conda activate character-bert
然后安装以下软件包:
conda install pytorch cudatoolkit=11.8 -c pytorch
pip install transformers==4.34.0 scikit-learn==1.3.1 gdown==4.7.1
注1: 如果你不打算在GPU上运行实验,请改用此命令安装pyTorch:
conda install pytorch cpuonly -c pytorch
注2: 如果你只想能够加载预训练的CharacterBERT权重,则不必安装
scikit-learn,它仅在评估期间用于计算精确度、召回率、F1指标。
预训练模型
你可以使用download.py脚本下载以下任何模型:
| 关键词 | 模型描述 |
|---|---|
| general_character_bert | 通用领域CharacterBERT,在英语维基百科和OpenWebText上从头预训练。 |
| medical_character_bert | 医学领域CharacterBERT,从general_character_bert初始化,然后在MIMIC-III临床记录和PMC OA生物医学论文摘要上进一步预训练。 |
| general_bert | 通用领域BERT,在英语维基百科和OpenWebText上从头预训练。1 |
| medical_bert | 医学领域BERT,从general_bert初始化,然后在MIMIC-III临床记录和PMC OA生物医学论文摘要上进一步预训练。2 |
| bert-base-uncased | 原始通用领域BERT (base, uncased) |
1, 2 我们提供BERT模型和CharacterBERT模型,因为我们预训练了这两种架构,以便公平比较这些架构。我们的BERT模型使用与
bert-base-uncased相同的架构和起始词片词汇。
例如,让我们下载CharacterBERT的医学版本:
python download.py --model='medical_character_bert'
我们也可以用一个命令下载所有模型:
python download.py --model='all'
实际使用CharacterBERT
CharacterBERT的架构与BERT几乎相同,因此你可以轻松适应Transformers库中的任何代码。
示例1: 从CharacterBERT获取词嵌入
"""基本示例: 从CharacterBERT获取词嵌入"""
from transformers import BertTokenizer
from modeling.character_bert import CharacterBertModel
from utils.character_cnn import CharacterIndexer
# 示例文本
x = "Hello World!"
# 对文本进行分词
tokenizer = BertTokenizer.from_pretrained(
'./pretrained-models/bert-base-uncased/')
x = tokenizer.basic_tokenizer.tokenize(x)
# 添加[CLS]和[SEP]
x = ['[CLS]', *x, '[SEP]']
# 将词元序列转换为字符索引
indexer = CharacterIndexer()
batch = [x] # 这是一个包含单个词元序列x的批次
batch_ids = indexer.as_padded_tensor(batch)
# 加载一些预训练的CharacterBERT
model = CharacterBertModel.from_pretrained(
'./pretrained-models/medical_character_bert/')
# 将批次输入CharacterBERT并获取嵌入
embeddings_for_batch, _ = model(batch_ids)
embeddings_for_x = embeddings_for_batch[0]
print('这些是CharacterBERT生成的嵌入(最后一个transformer层)')
for token, embedding in zip(x, embeddings_for_x):
print(token, embedding)
示例2: 使用CharacterBERT进行二元分类
""" 基本示例: 使用CharacterBERT进行二元分类 """
from transformers import BertForSequenceClassification, BertConfig
from modeling.character_bert import CharacterBertModel
#### 加载用于分类的BERT ####
config = BertConfig.from_pretrained('bert-base-uncased', num_labels=2) # 二元分类
model = BertForSequenceClassification(config=config)
model.bert.embeddings.word_embeddings # 词片嵌入
>>> Embedding(30522, 768, padding_idx=0)
#### 用CHARACTER_BERT替换BERT ####
character_bert_model = CharacterBertModel.from_pretrained(
'./pretrained-models/medical_character_bert/')
model.bert = character_bert_model
model.bert.embeddings.word_embeddings # 词片被CharacterCNN替换
>>> CharacterCNN(
(char_conv_0): Conv1d(16, 32, kernel_size=(1,), stride=(1,))
(char_conv_1): Conv1d(16, 32, kernel_size=(2,), stride=(1,))
(char_conv_2): Conv1d(16, 64, kernel_size=(3,), stride=(1,))
(char_conv_3): Conv1d(16, 128, kernel_size=(4,), stride=(1,))
(char_conv_4): Conv1d(16, 256, kernel_size=(5,), stride=(1,))
(char_conv_5): Conv1d(16, 512, kernel_size=(6,), stride=(1,))
(char_conv_6): Conv1d(16, 1024, kernel_size=(7,), stride=(1,))
(_highways): Highway(
(_layers): ModuleList(
(0): Linear(in_features=2048, out_features=4096, bias=True)
(1): Linear(in_features=2048, out_features=4096, bias=True)
)
)
(_projection): Linear(in_features=2048, out_features=768, bias=True)
)
#### 准备原始文本 ####
from transformers import BertTokenizer
from utils.character_cnn import CharacterIndexer
text = "CharacterBERT关注每个词元的字符"
bert_tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
tokenized_text = bert_tokenizer.basic_tokenizer.tokenize(text) # 这不是词片分词
tokenized_text
>>> ['characterbert', 'attends', 'to', 'each', 'token', "'", 's', 'characters']
indexer = CharacterIndexer() # 将每个词元转换为字符索引列表
input_tensor = indexer.as_padded_tensor([tokenized_text]) # 我们构建一个只包含一个序列的批次
input_tensor.shape
>>> torch.Size([1, 8, 50]) # (批次大小, 序列长度, 字符嵌入维度)
#### 使用CHARACTER_BERT进行推理 ####
output = model(input_tensor, return_dict=False)[0]
>>> tensor([[-0.3378, -0.2772]], grad_fn=<AddmmBackward>) # 类别logits
有关更完整(但仍具有说明性)的示例,您可以参考run_experiments.sh脚本,该脚本使用BERT/CharacterBERT运行一些分类/序列标注实验。
bash run_experiments.sh
您可以调整run_experiments.sh脚本来尝试任何可用的模型。通过调整data.py脚本,您还应该能够添加真实的分类和序列标注任务。
在GPU上运行实验
为了使用GPU,您需要确保conda环境中的PyTorch版本与您机器的配置相匹配。为此,您可能需要运行一些测试。
假设您想使用机器上的GPU 0号。那么设置:
export CUDA_VISIBLE_DEVICES=0
然后运行这些命令来检查pytorch是否能检测到您的GPU:
import torch
print(torch.cuda.is_available()) # 应返回`True`
如果最后一个命令返回False,那么很可能是安装的PyTorch版本与您机器的配置不匹配。要修复这个问题,在终端中运行nvidia-smi并检查您的驱动程序版本:
<中心>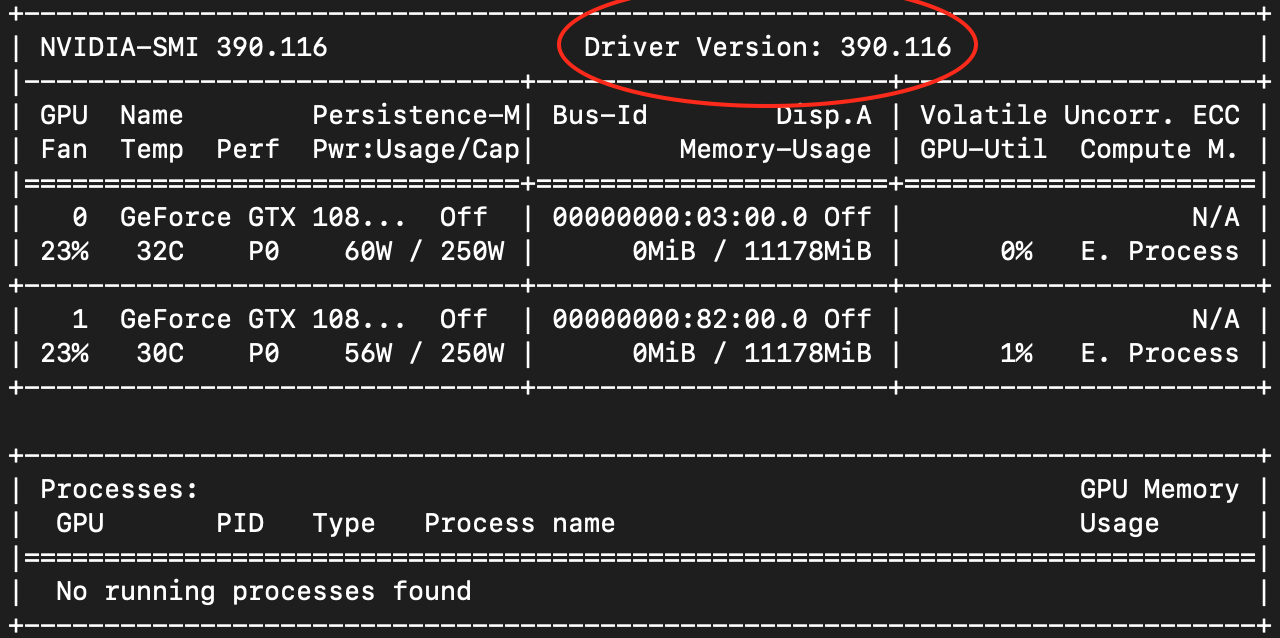 </中心>
</中心>
然后将此版本与NVIDIA CUDA工具包发行说明中给出的数字进行比较:
<中心> </中心>
</中心>
在这个例子中,显示的版本是390.116,对应CUDA 9.0。这意味着安装PyTorch的适当命令是:
conda install pytorch cudatoolkit=9.0 -c pytorch
现在,一切应该正常工作了!
参考文献
如果您在工作中使用CharacterBERT,请引用我们的论文:
@inproceedings{el-boukkouri-etal-2020-characterbert,
title = "{C}haracter{BERT}: Reconciling {ELM}o and {BERT} for Word-Level Open-Vocabulary Representations From Characters",
author = "El Boukkouri, Hicham and
Ferret, Olivier and
Lavergne, Thomas and
Noji, Hiroshi and
Zweigenbaum, Pierre and
Tsujii, Jun{'}ichi",
booktitle = "Proceedings of the 28th International Conference on Computational Linguistics",
month = dec,
year = "2020",
address = "Barcelona, Spain (Online)",
publisher = "International Committee on Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.coling-main.609",
doi = "10.18653/v1/2020.coling-main.609",
pages = "6903--6915",
abstract = "由于BERT带来的引人注目的改进,许多最新的表示模型采用了Transformer架构作为其主要构建块,因此继承了词片分词系统,尽管它本质上并不与Transformer的概念相关联。虽然这个系统被认为在字符的灵活性和完整词的效率之间达到了良好的平衡,但使用来自通用领域的预定义词片词汇并不总是适合的,特别是在为专门领域(如医学领域)构建模型时。此外,采用词片分词将重点从词级转移到了子词级,使模型在概念上更加复杂,arguably在实践中也不那么方便。出于这些原因,我们提出了CharacterBERT,这是BERT的一个新变体,它完全放弃了词片系统,而是使用Character-CNN模块通过查询字符来表示整个词。我们展示了这个新模型在各种医学领域任务上改善了BERT的性能,同时产生了稳健的、词级的和开放词汇的表示。",
}












{kind=link}