
 访问官网
访问官网 Github
Github🚀 进化中的中文对话模型资源库 🚀
鲁迅说过:有多少人工,才有多少智能
🔥 项目前身:从一个梦想开始——将alpaca的英文数据集转化为中文,开启中文对话模型的无限可能。我们的旅程起始于"alpaca中文翻译数据集",旨在让每个人都能轻松训练出能说中文的对话模型。
🌟 全新目标:随着huggingface平台上的数据集如雨后春笋般涌现,我们决定让项目更上一层楼。现在,我们致力于精选并整合huggingface上的顶尖数据集,为中文模型训练提供一站式的资源库。
🎯 项目优势:无论你是数据科学家、开发者,还是对AI充满好奇的探索者,只要你遵循我们提供的步骤,就能快速上手,训练出高质量的中文基础模型。这个模型将成为你进一步定制和优化,以适应特定行业需求的坚实基础。
🚧 项目进行时:我们的团队正在努力工作,不断更新和优化项目,以确保你能够获得最佳的训练资源。加入我们,一起推动中文对话模型的边界,让AI更好地服务于我们的社区。
🤝 加入我们:准备好开启你的中文AI之旅了吗?现在就star我们的项目,加入我们的社区,一起见证中文对话模型的未来!
使用方法:
首先你需要安装LLaMA-Factory,具体安装运行方法请参考原项目:
https://github.com/hiyouga/LLaMA-Factory
第一步:下载项目代码和数据集
代码直接clone本项目即可。
数据集请在百度网盘下载
链接: https://pan.baidu.com/s/1zjHmK-y5XBNDAgIdxbN1Ww?pwd=rsfu 提取码: rsfu
第二步:修改preprocess.py中的模型信息变量并运行(重要,否则模型不会知道自己叫什么名字!)
NAME = "模型名字" # 影响模型回答自己叫什么
AUTHOR = "作者名字" # 影响模型回答自己是谁训练的
第三步: 把项目的data文件夹替换LLaMA-Factory的项目文件夹下的data文件夹,把train.py或运行train.sh也放到LLaMA-Factory的项目文件夹下
第四步:运行train.py或运行train.sh进行模型训练
当前train.py中用的是lora,train.sh是全参数sft的训练脚本,总之根据llama-factory的文档进行训练即可。
在这一步你可以自由增加数据集、调整模型参数等等,让模型更适合你的需求,如何修改参考llama-factory项目就好。
整体架构
项目按照PDCA循环进行迭代,每个迭代周期包括以下几个阶段:
- Plan:挑选数据集,和模型,制定模型训练计划
- Do:模型训练阶段,
- Check:模型测试阶段,对模型进行测试,检查模型效果
- Act:根据测试结果,对模型进行调整,优化模型
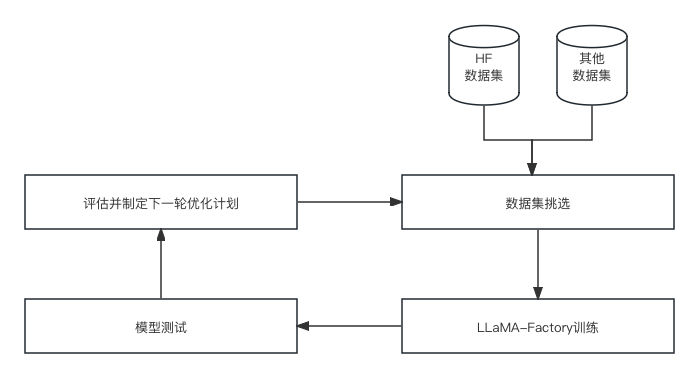
项目整体基于LLaMA-Factory框架进行。
数据结构
本项目的数据集设置按照LLaMA-factory的数据集结构进行设置,具体如下:
- history/ # 项目历史记录
- dataset/ # 我们精心挑选过的数据集
preprocess.py # 数据预处理代码
train.py # 模型训练代码(TBD)
引用
如果您觉得本项目对您的研究有所帮助或使用了本项目的代码或数据,请参考以下引用(临时):
@misc{chat-dataset-baseline,
author = {Liu, Beiming and Huang, Kunhao and Jiao, Lihua and He, Yuchen and Zhang, Ruiqin and Liang, Yuan and Wang, Yingshan},
title = {chat-dataset-baseline},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/hikariming/alpaca_chinese_dataset}},
}











