
 访问官网
访问官网 Github
Github 文档
文档🌿 Konoha:日语分词器的简单封装







Konoha 是一个 Python 库,提供了各种日语分词器的易用集成接口,让你能够轻松切换分词器并提升预处理效率。
支持的分词器
此外,konoha 还提供了基于规则的分词器(空格、字符)和基于规则的句子分割器。
使用 Docker 快速开始
只需在你的计算机上运行以下命令:
docker run --rm -p 8000:8000 -t himkt/konoha # 从 DockerHub 运行
或者你可以在本地构建镜像:
git clone https://github.com/himkt/konoha # 下载 konoha
cd konoha && docker-compose up --build # 构建并启动容器
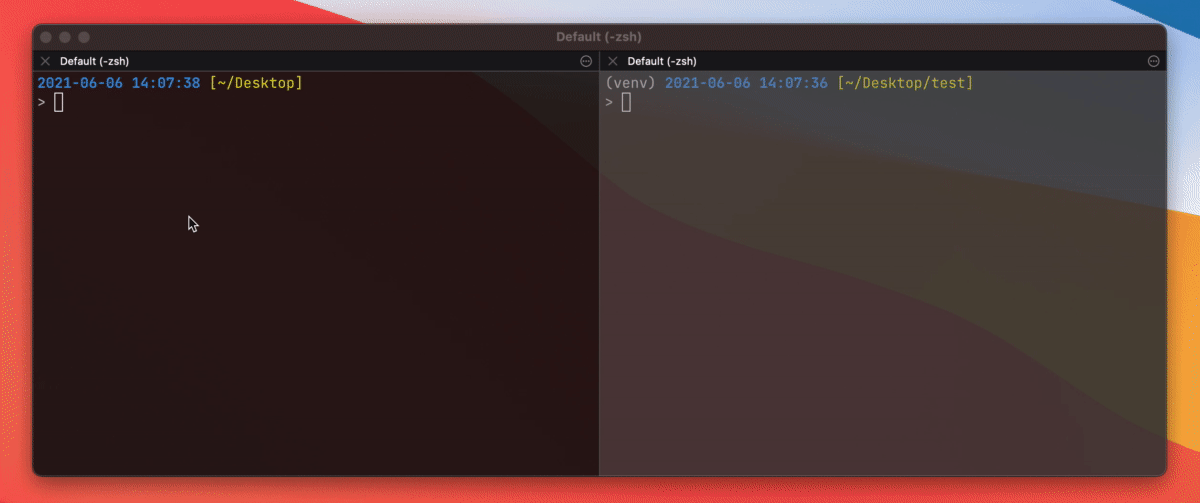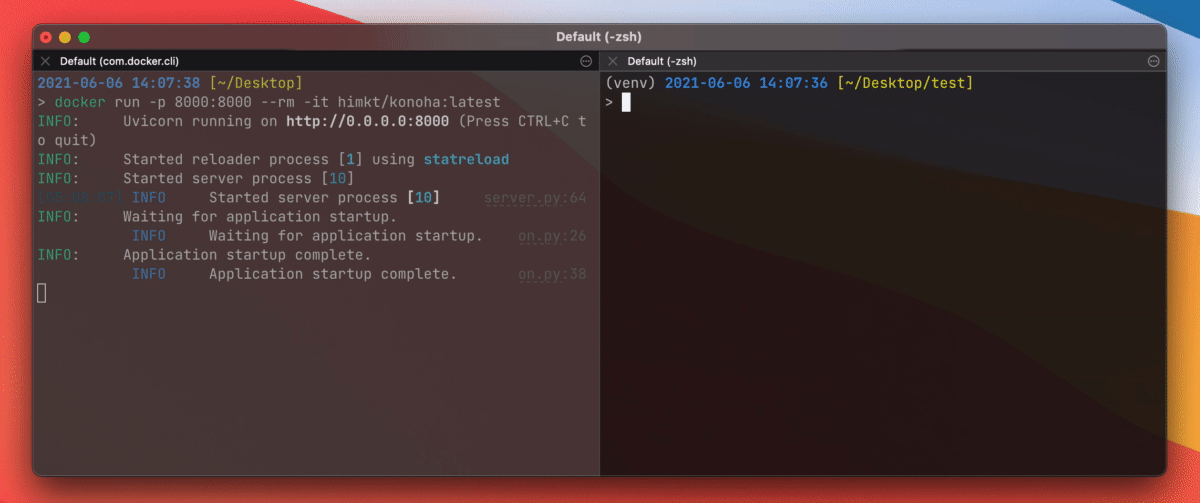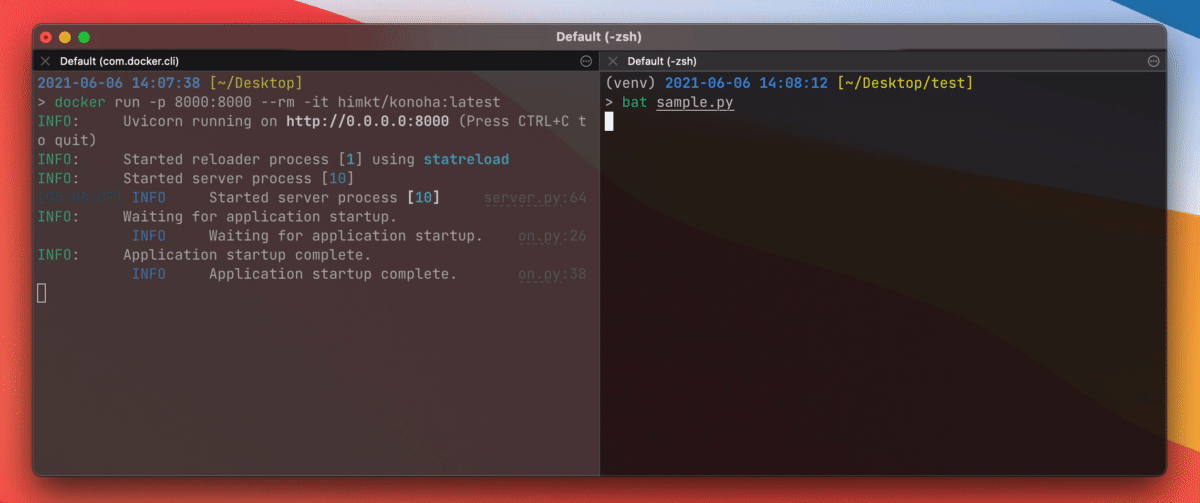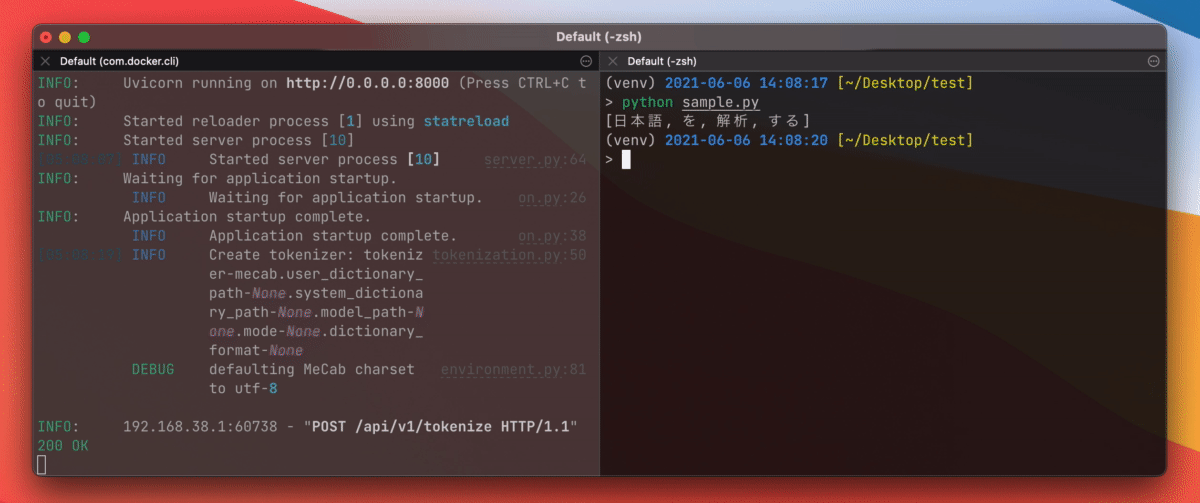
分词操作可通过向 localhost:8000/api/v1/tokenize 发送 JSON 对象来完成。
你还可以通过向 localhost:8000/api/v1/batch_tokenize 传递 texts: ["第一个输入", "第二个输入"] 来进行批量分词。
(API 文档可在 localhost:8000/redoc 查看,你可以使用网页浏览器查看)
在终端中使用 curl 发送请求。
请注意,在 v4.6.4 版本中端点路径已更改。
请查看我们的发布说明 (https://github.com/himkt/konoha/releases/tag/v4.6.4)。
$ curl localhost:8000/api/v1/tokenize -X POST -H "Content-Type: application/json" \
-d '{"tokenizer": "mecab", "text": "これはペンです"}'
{
"tokens": [
[
{
"surface": "これ",
"part_of_speech": "名詞"
},
{
"surface": "は",
"part_of_speech": "助詞"
},
{
"surface": "ペン",
"part_of_speech": "名詞"
},
{
"surface": "です",
"part_of_speech": "助動詞"
}
]
]
}
安装
推荐使用 pip install 'konoha[all]' 安装 konoha。
- 安装特定分词器的 konoha:
pip install 'konoha[(分词器名称)]'。 - 安装特定分词器和远程文件支持的 konoha:
pip install 'konoha[(分词器名称),remote]'
如果您想安装带有分词器的 konoha,请安装特定分词器的 konoha
(例如 konoha[mecab]、konoha[sudachi] 等)或单独安装分词器。
示例
词级分词
from konoha import WordTokenizer
sentence = '自然言語処理を勉強しています'
tokenizer = WordTokenizer('MeCab')
print(tokenizer.tokenize(sentence))
# => [自然, 言語, 処理, を, 勉強, し, て, い, ます]
tokenizer = WordTokenizer('Sentencepiece', model_path="data/model.spm")
print(tokenizer.tokenize(sentence))
# => [▁, 自然, 言語, 処理, を, 勉強, し, ています]
更多详细信息,请参阅 example/ 目录。
远程文件
Konoha 支持云存储上的词典和模型(目前支持 Amazon S3)。
这需要使用 remote 选项安装 konoha,请参阅安装。
# 从 S3 下载用户词典
word_tokenizer = WordTokenizer("mecab", user_dictionary_path="s3://abc/xxx.dic")
print(word_tokenizer.tokenize(sentence))
# 从 S3 下载系统词典
word_tokenizer = WordTokenizer("mecab", system_dictionary_path="s3://abc/yyy")
print(word_tokenizer.tokenize(sentence))
# 从 S3 下载模型文件
word_tokenizer = WordTokenizer("sentencepiece", model_path="s3://abc/zzz.model")
print(word_tokenizer.tokenize(sentence))
句级分词
from konoha import SentenceTokenizer
sentence = "私は猫だ。名前なんてものはない。だが,「かわいい。それで十分だろう」。"
tokenizer = SentenceTokenizer()
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。', '名前なんてものはない。', 'だが,「かわいい。それで十分だろう」。']
您可以更改句子分割符和括号表达式的符号。
- 句子分割符
sentence = "私は猫だ。名前なんてものはない.だが,「かわいい。それで十分だろう」。"
tokenizer = SentenceTokenizer(period=".")
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。名前なんてものはない.', 'だが,「かわいい。それで十分だろう」。']
- 括号表达式
sentence = "私は猫だ。名前なんてものはない。だが,『かわいい。それで十分だろう』。"
tokenizer = SentenceTokenizer(
patterns=SentenceTokenizer.PATTERNS + [re.compile(r"『.*?』")],
)
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。', '名前なんてものはない。', 'だが,『かわいい。それで十分だろう』。']
测试
python -m pytest
文章
致谢
测试中使用的 Sentencepiece 模型由 @yoheikikuta 提供。非常感谢!











