
 Github
Github Huggingface
Huggingface 论文
论文Distil-Whisper
Distil-Whisper 是 Whisper 的蒸馏版本,速度快 6 倍,体积小 49%,在域外评估集上的词错误率(WER)相差不到 1%:
| 模型 | 参数量 / 百万 | 相对延迟 ↑ | 短音频 WER ↓ | 长音频 WER ↓ |
|---|---|---|---|---|
| large-v3 | 1550 | 1.0 | 8.4 | 11.0 |
| distil-large-v3 | 756 | 6.3 | 9.7 | 10.8 |
| distil-large-v2 | 756 | 5.8 | 10.1 | 11.6 |
| distil-medium.en | 394 | 6.8 | 11.1 | 12.4 |
| distil-small.en | 166 | 5.6 | 12.1 | 12.8 |
对于大多数应用,我们推荐使用最新的 distil-large-v3 检查点,因为它是性能最佳的蒸馏检查点,并且与所有 Whisper 库兼容。唯一的例外是内存非常有限的资源受限应用,如设备上或移动应用,在这种情况下 distil-small.en 是一个很好的选择,因为它只有 166M 参数,而且其性能与 Whisper large-v3 的 WER 相差不到 4%。
**注意:**Distil-Whisper 目前仅适用于英语语音识别。我们正在与社区合作,对其他语言的 Whisper 进行蒸馏。如果您有兴趣对您的语言进行 Whisper 蒸馏,请查看提供的训练代码。我们将在准备就绪后很快更新存储库,添加多语言检查点!
1. 使用方法
Distil-Whisper 在 Hugging Face 🤗 Transformers 4.35 版本及以后版本中得到支持。要运行该模型,首先安装最新版本的 Transformers 库。在这个例子中,我们还将安装 🤗 Datasets 以从 Hugging Face Hub 加载一个示例音频数据集:
pip install --upgrade pip
pip install --upgrade transformers accelerate datasets[audio]
短音频转录
短音频转录是指转录长度不超过 30 秒的音频样本的过程,这是 Whisper 模型的最大接收域。这意味着整个音频片段可以一次性处理,无需分块。
首先,我们通过方便的 AutoModelForSpeechSeq2Seq 和 AutoProcessor 类加载 Distil-Whisper。
我们以 float16 精度加载模型,并通过传递 low_cpu_mem_usage=True 确保加载时间尽可能短。此外,我们通过传递 use_safetensors=True 确保模型以 safetensors 格式加载:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
然后可以将模型和处理器传递给 pipeline。请注意,如果您想对生成过程有更多控制,可以直接使用模型 + 处理器 API,如下所示。
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
torch_dtype=torch_dtype,
device=device,
)
接下来,我们从 LibriSpeech 语料库加载一个示例短音频:
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
最后,我们可以调用 pipeline 来转录音频:
result = pipe(sample)
print(result["text"])
要转录本地音频文件,只需在调用 pipeline 时传递音频文件的路径:
result = pipe("audio.mp3")
print(result["text"])
有关如何自定义自动语音识别 pipeline 的更多信息,请参阅 ASR pipeline 文档。 我们还提供了一个端到端的 Google Colab,用于对比 Whisper 和 Distil-Whisper 的性能。
要更好地控制生成参数,请直接使用模型 + 处理器 API:
可以将特定的生成参数传递给 model.generate,包括用于束搜索的 num_beams、用于段级时间戳的 return_timestamps 和用于提示的 prompt_ids。有关更多详细信息,请参阅文档字符串。
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from datasets import Audio, load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
dataset = dataset.cast_column("audio", Audio(processor.feature_extractor.sampling_rate))
sample = dataset[0]["audio"]
input_features = processor(
sample["array"], sampling_rate=sample["sampling_rate"], return_tensors="pt"
).input_features
input_features = input_features.to(device, dtype=torch_dtype)
gen_kwargs = {
"max_new_tokens": 128,
"num_beams": 1,
"return_timestamps": False,
}
pred_ids = model.generate(input_features, **gen_kwargs)
pred_text = processor.batch_decode(pred_ids, skip_special_tokens=True, decode_with_timestamps=gen_kwargs["return_timestamps"])
print(pred_text)
顺序长形式
最新的distil-large-v3检查点专门设计用于与OpenAI的顺序长形式转录算法兼容。该算法使用滑动窗口对长音频文件(>30秒)进行缓冲推理,与分块长形式算法相比,可以返回更准确的转录。
在以下任一情况下应该使用顺序长形式算法:
- 转录准确性是最重要的因素,而延迟不太重要
- 你正在转录批量长音频文件,在这种情况下,顺序算法的延迟与分块算法相当,但准确度高出0.5% WER
如果你正在转录单个长音频文件,并且延迟是最重要的因素,你应该使用下面描述的分块算法分块长形式。有关不同算法的详细解释,请参阅Distil-Whisper论文的第5节。
我们首先像之前一样加载模型和处理器:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
然后可以将模型和处理器传递给pipeline。
请注意,如果你想对生成过程有更多控制,可以直接使用model.generate(...)API,如下所示。
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
torch_dtype=torch_dtype,
device=device,
)
接下来,我们加载一个长形式的音频样本。这里,我们使用了来自LibriSpeech语料库的连接样本示例:
from datasets import load_dataset
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
最后,我们可以调用pipeline来转录音频:
result = pipe(sample)
print(result["text"])
要转录本地音频文件,只需在调用pipeline时传递音频文件的路径:
result = pipe("audio.mp3")
print(result["text"])
分块长形式
distil-large-v3仍然兼容Transformers分块长形式算法。当需要对单个大型音频文件进行转录并要求尽可能快的推理时,应该使用此算法。在这种情况下,分块算法比OpenAI的顺序长形式实现快9倍(参见Distil-Whisper论文的表7)。
我们可以像之前一样加载模型和处理器:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
要启用分块,请将chunk_length_s参数传递给pipeline。对于distil-large-v3,25秒的块长度是最佳的。要激活批处理,请传递参数batch_size:
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=25,
batch_size=16,
torch_dtype=torch_dtype,
device=device,
)
参数max_new_tokens控制每个分块生成的最大标记数。在典型的语音设置中,每秒最多说3个词。因此,对于30秒的输入,最多有90个词(约128个标记)。我们将每个分块生成的最大标记数设置为128,以截断可能在片段末尾出现的任何幻觉。这些标记会在分块边界使用长形式分块转录算法被移除,所以在生成过程中直接截断它们更有效,可以避免解码器中的冗余生成步骤。
现在,让我们加载一个长形式音频样本。这里,我们使用来自LibriSpeech语料库的连接样本示例:
from datasets import load_dataset
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
最后,我们可以调用管道来转录音频:
result = pipe(sample)
print(result["text"])
有关如何自定义自动语音识别管道的更多信息,请参阅ASR管道文档。
推测解码
Distil-Whisper可以作为Whisper的辅助模型用于推测解码。推测解码在数学上确保获得与Whisper完全相同的输出,同时速度提高2倍。这使其成为现有Whisper管道的完美替代品,因为可以保证相同的输出。
对于推测解码,我们需要加载教师模型:openai/whisper-large-v3。以及辅助模型(又称学生模型)distil-whisper/distil-large-v3。
让我们首先加载教师模型和处理器。我们以与前面示例中加载Distil-Whisper模型相同的方式来做这件事:
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
现在让我们加载辅助模型。由于Distil-Whisper与教师模型共享完全相同的编码器,我们只需要将2层解码器加载为"仅解码器"模型:
from transformers import AutoModelForCausalLM
assistant_model_id = "distil-whisper/distil-large-v2"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
assistant_model.to(device)
辅助模型与教师共享相同的处理器,所以不需要加载学生处理器。
现在我们可以将辅助模型传递给管道以用于推测解码。我们将其作为generate_kwarg传递,键为"assistant_model",以启用推测解码:
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
generate_kwargs={"assistant_model": assistant_model},
torch_dtype=torch_dtype,
device=device,
)
和之前一样,我们可以将任何样本传递给管道进行转录:
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
**注意:**推测解码平均应比仅使用Whisper large-v2快2倍,而VRAM内存使用量仅增加8%,同时在数学上确保相同的结果。这使其成为现有语音识别管道中Whisper large-v2的完美替代品。
有关推测解码的更多详细信息,请参阅以下资源:
- Sanchit Gandhi的博文用于2倍速Whisper推理的推测解码
- Joao Gante的博文辅助生成:低延迟文本生成的新方向
- Leviathan等人的论文通过推测解码实现Transformers的快速推理
额外的速度和内存改进
您可以对Distil-Whisper应用额外的速度和内存改进,我们将在下面介绍这些内容。
Flash Attention
如果您的GPU支持,我们建议使用Flash Attention 2。 为此,您首先需要安装Flash Attention:
pip install flash-attn --no-build-isolation
然后您可以传递use_flash_attention_2=True给from_pretrained以启用Flash Attention 2:
- model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True, use_flash_attention_2=True)
Torch Scale-Product-Attention (SDPA)
如果您的GPU不支持Flash Attention,我们建议使用BetterTransformers。 为此,您首先需要安装optimum:
pip install --upgrade optimum
然后在使用模型之前将其转换为"BetterTransformer"模型:
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = model.to_bettertransformer()
导出到其他库
Distil-Whisper 在以下库中支持原始的"顺序"长形式转录算法。点击表格中的链接可查看每个库的相关代码片段:
| 库 | distil-small.en | distil-medium.en | distil-large-v2 |
|---|---|---|---|
| OpenAI Whisper | 链接 | 链接 | 链接 |
| Whisper cpp | 链接 | 链接 | 链接 |
| Transformers js | 链接 | 链接 | 链接 |
| Candle (Rust) | 链接 | 链接 | 链接 |
将"分块"长形式转录算法集成到各个库中的更新将在此处发布。
有关 🤗 Transformers 的代码示例,请参阅短形式和长形式转录部分。
2. 为什么使用 Distil-Whisper?⁉️
Distil-Whisper 旨在成为 Whisper 英语语音识别的即插即用替代品。以下是五个选择 Distil-Whisper 的理由:
- **更快的推理速度:**推理速度提高 6 倍,同时在分布外音频上的表现与 Whisper 的词错率相差不到 1%:

- **对噪声的鲁棒性:**在低信噪比下表现出强大的词错率性能:
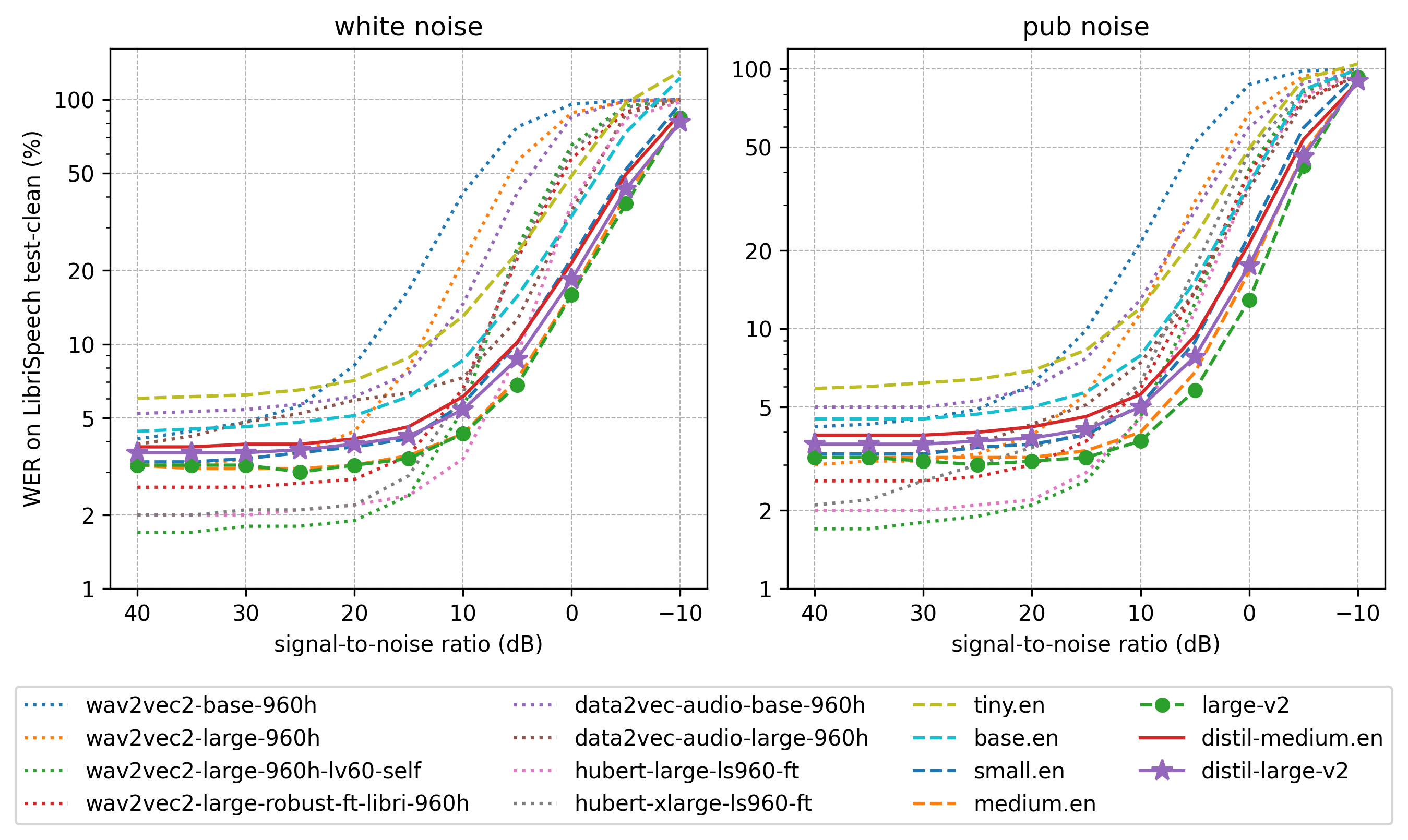
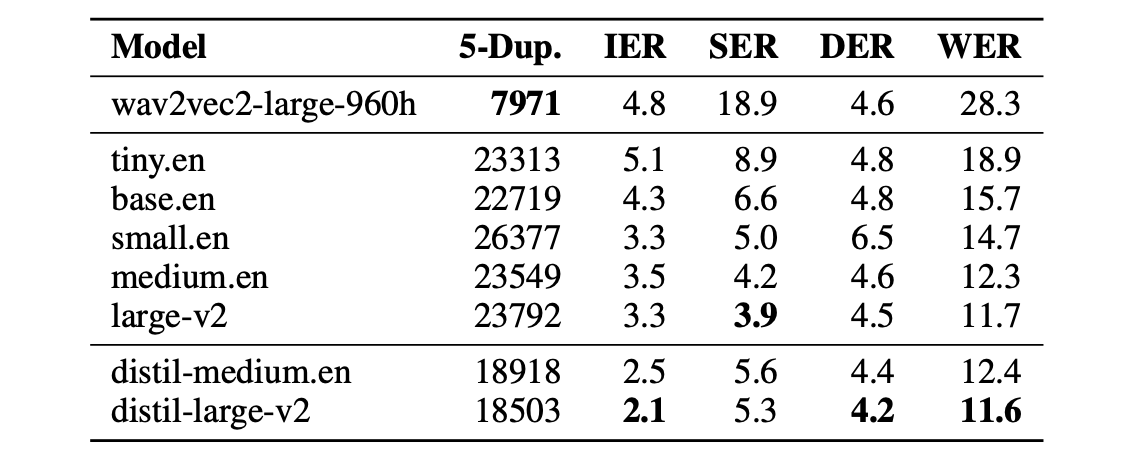
- **对幻觉的鲁棒性:**重复的 5 元词组重复次数减少 1.3 倍(5-Dup.),插入错误率(IER)比 Whisper 低 2.1%:
- **为推测解码设计:**Distil-Whisper 可作为 Whisper 的辅助模型使用,提供 2 倍的推理速度,同时在数学上保证与 Whisper 模型输出相同的结果。
- **宽松的许可证:**Distil-Whisper 采用 MIT 许可证,可用于商业应用。
3. 方法 ✍️
为了蒸馏 Whisper,我们复制了整个编码器模块并在训练期间冻结它。我们只复制了两个解码器层,这两层分别初始化为 Whisper 的第一层和最后一层解码器。Whisper 的其他所有解码器层都被舍弃:

Distil-Whisper 采用知识蒸馏目标进行训练。具体来说,它被训练以最小化蒸馏模型和 Whisper 模型之间的 KL 散度,以及伪标记音频数据上的交叉熵损失。
我们在总计 22,000 小时的伪标记音频数据上训练 Distil-Whisper,涵盖 10 个领域和超过 18,000 名说话者:
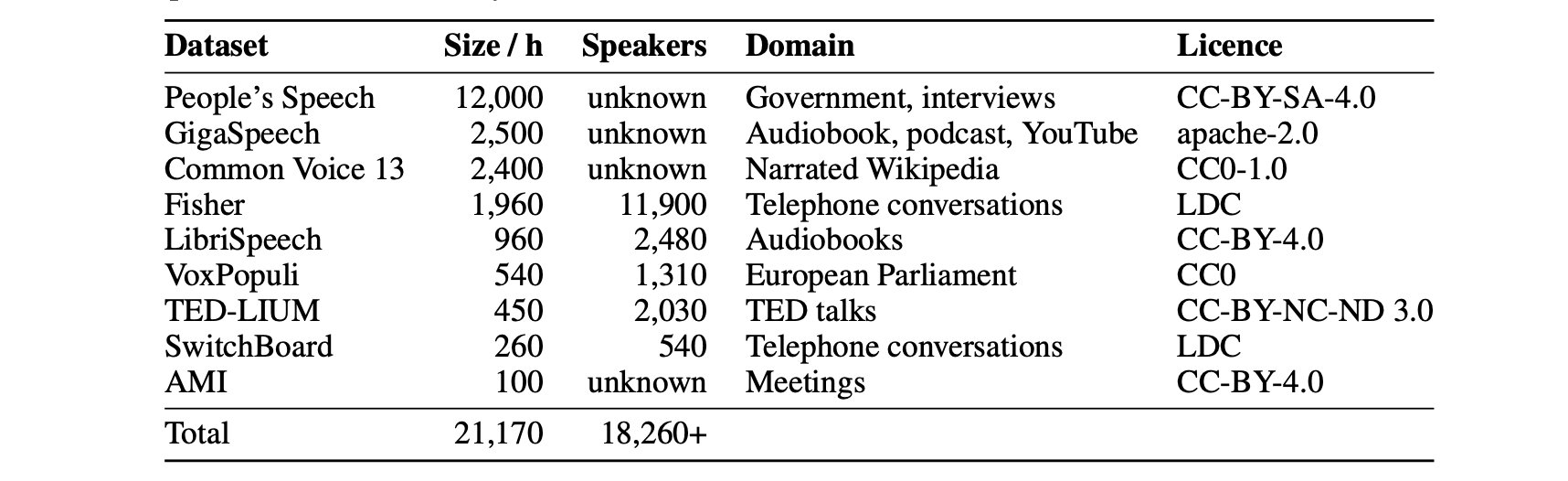
这种多样化的音频数据集对确保 Distil-Whisper 在不同数据集和领域的鲁棒性至关重要。
此外,我们使用词错率过滤器来剔除 Whisper 错误转录或产生幻觉的伪标签。这极大地提高了下游蒸馏模型的词错率性能。
有关蒸馏设置和评估结果的完整详情,请参阅 Distil-Whisper 论文。
4. 训练代码
用于复现 Distil-Whisper 的训练代码可在 training 目录中找到。这些代码已经过改编,足够通用,可用于多语言语音识别的 Whisper 蒸馏,方便社区中的任何人根据自己选择的语言来蒸馏 Whisper。
5. 致谢
- OpenAI 提供的 Whisper 模型和原始代码库
- Hugging Face 🤗 Transformers 提供的模型集成
- Google 的 TPU Research Cloud (TRC) 项目提供的 Cloud TPU v4
6. 引用
如果您使用了这个模型,请考虑引用 Distil-Whisper 论文:
@misc{gandhi2023distilwhisper,
title={Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling},
author={Sanchit Gandhi and Patrick von Platen and Alexander M. Rush},
year={2023},
eprint={2311.00430},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
还有Whisper论文:
@misc{radford2022robust,
title={通过大规模弱监督实现稳健的语音识别},
author={Alec Radford 和 Jong Wook Kim 和 Tao Xu 和 Greg Brockman 和 Christine McLeavey 和 Ilya Sutskever},
year={2022},
eprint={2212.04356},
archivePrefix={arXiv},
primaryClass={eess.AS}
}











