
 访问官网
访问官网 Github
Github 文档
文档 论文
论文VGGSfM和Mast3r的辐射场及其比较
本项目旨在使用两种不同的野外深度相机姿态和3D点云重建方法探索高斯散射:VGGSfM和Mast3r。 目标是比较它们的性能并了解每种方法的优势和局限性。
项目结构
安装
你需要安装Viser和plyfile
pip install viser==0.1.29
pip install plyfile
功能
- 将MASt3R的功能转换为COLMAP兼容格式(在MASt3R已安装的环境中)
- 将mast3r结果保存为COLMAP兼容的cameras/images/points3d
python colmap_from_mast3r.py --images_dir <图像路径> --save_dir <保存COLMAP结果路径> --model_path <mast3r模型检查点路径>
- 在线COLMAP结果查看器
- 要可视化彩色VGGSfM点云,请参考此链接
python colmap_vis.py --images_dir <图像路径> --colmap_path <COLMAP结果路径>
结果
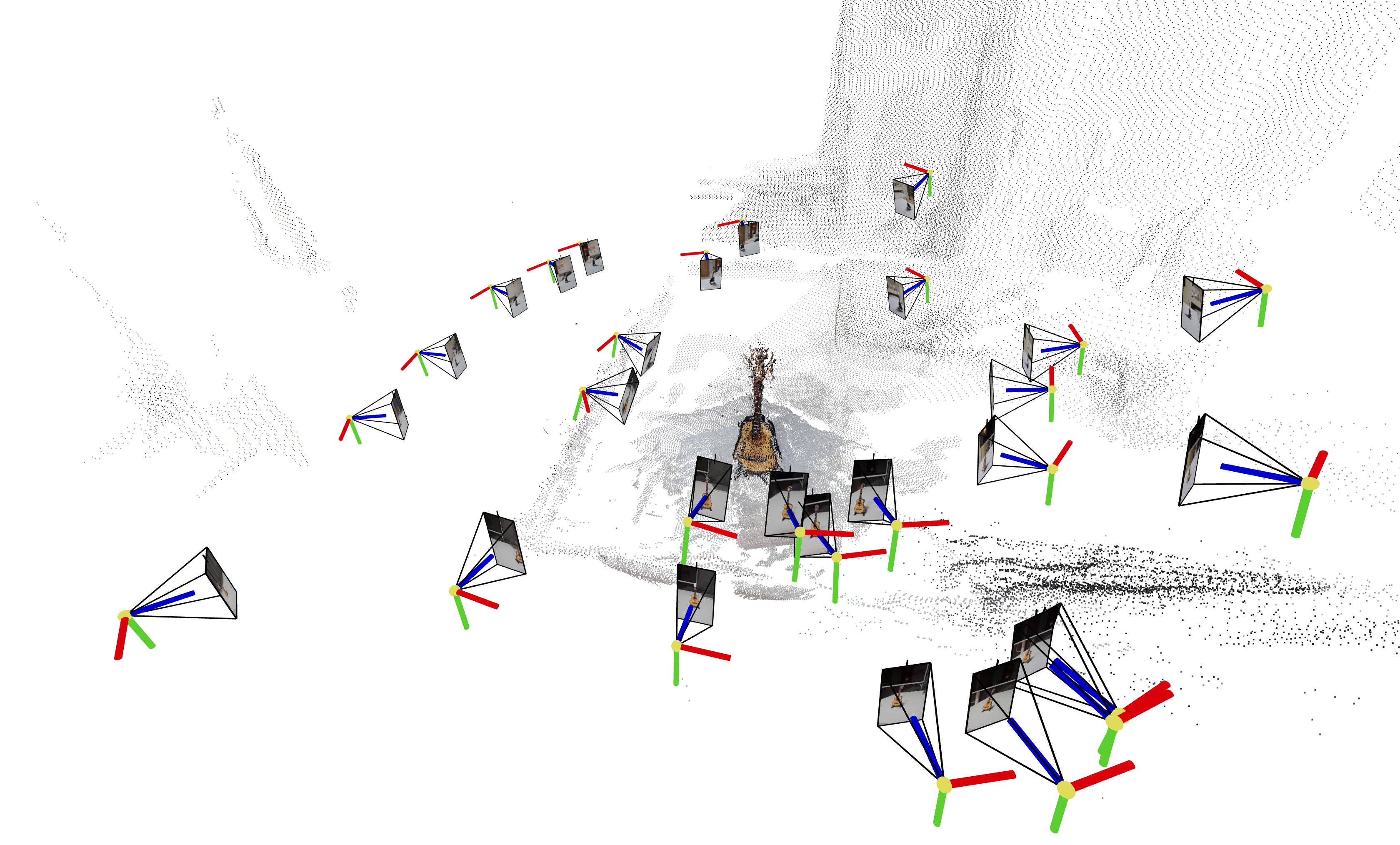
我在MASt3R的NLE_tower数据集以及我的自定义数据集(企鹅和吉他)上进行了测试。每个数据集分别包含5、10和27张图像。
1) COLMAP点云
| MASt3R | VGGSfM |
|---|---|
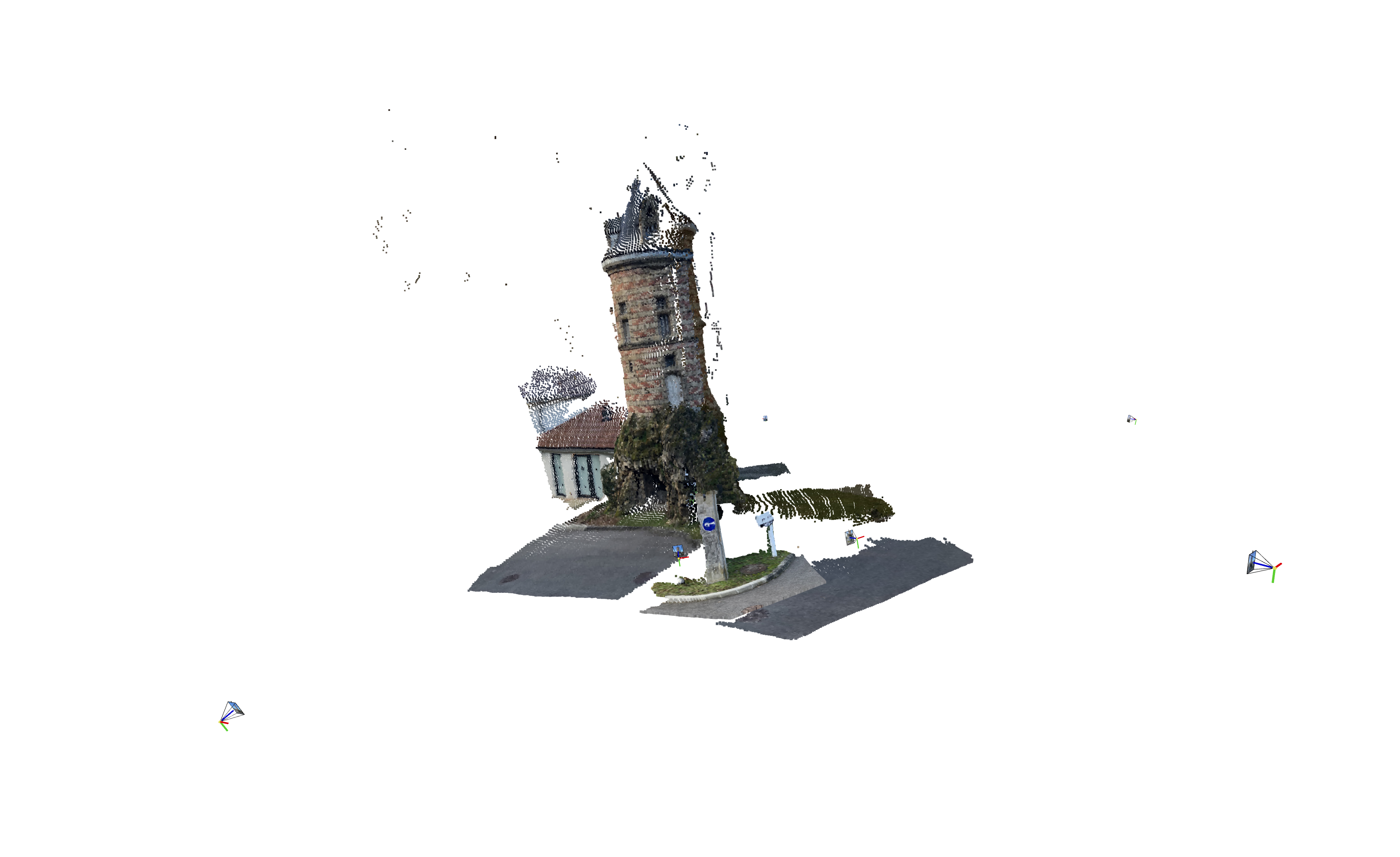 |  |
 |  |
 |  |
2) 辐射场重建
| MASt3R | VGGSfM |
|---|---|
 | 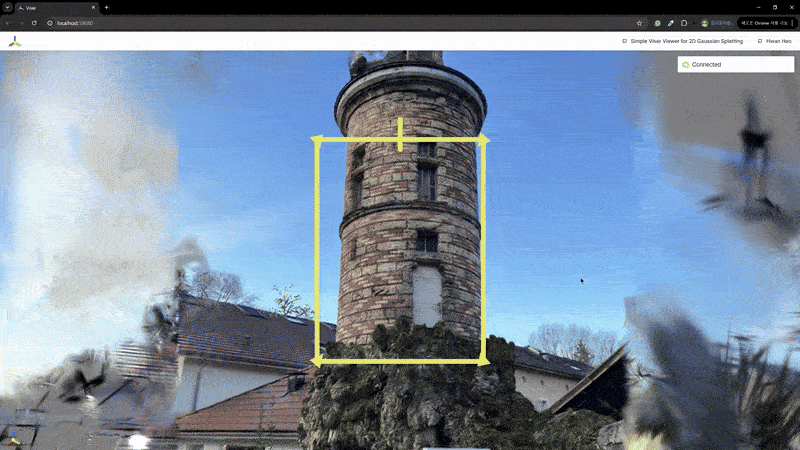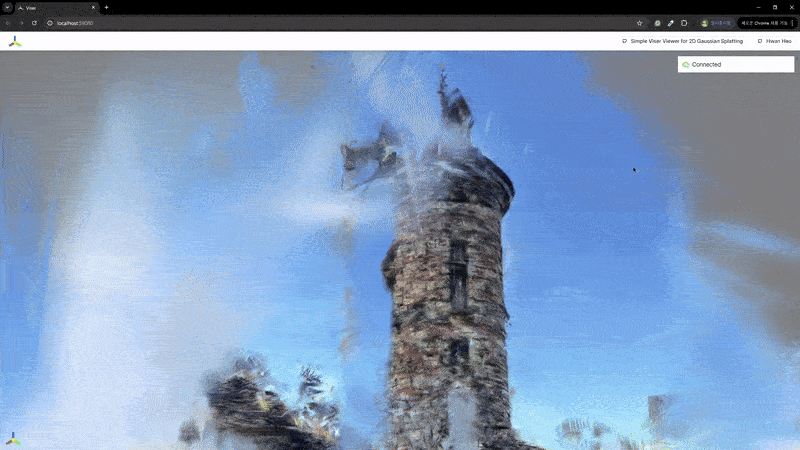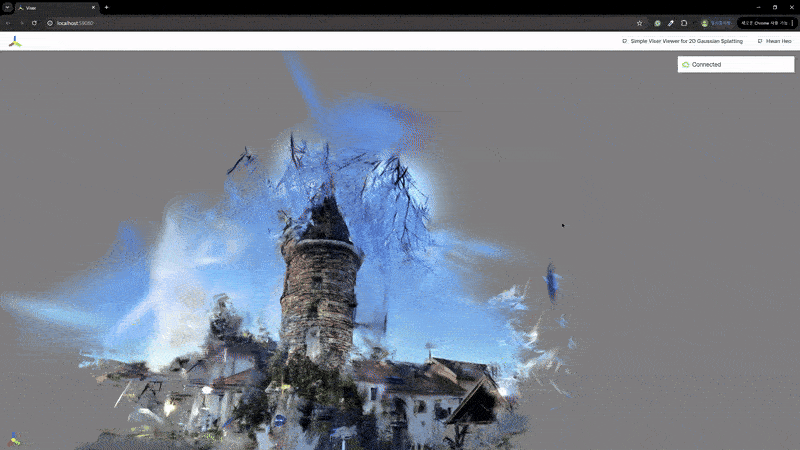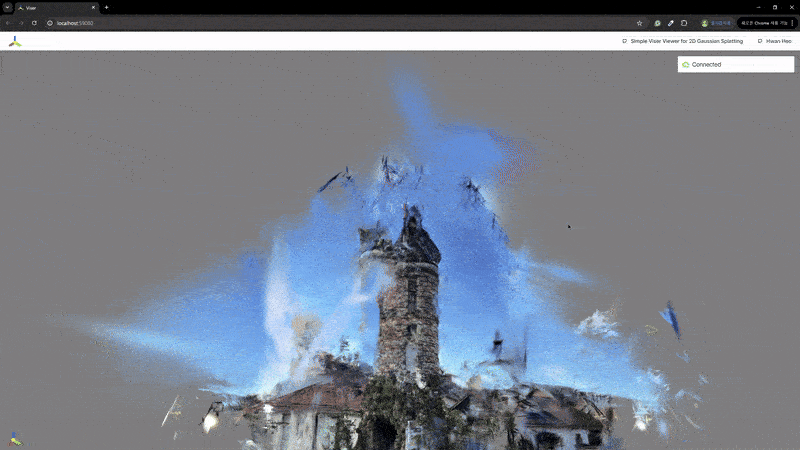 |
 |  |
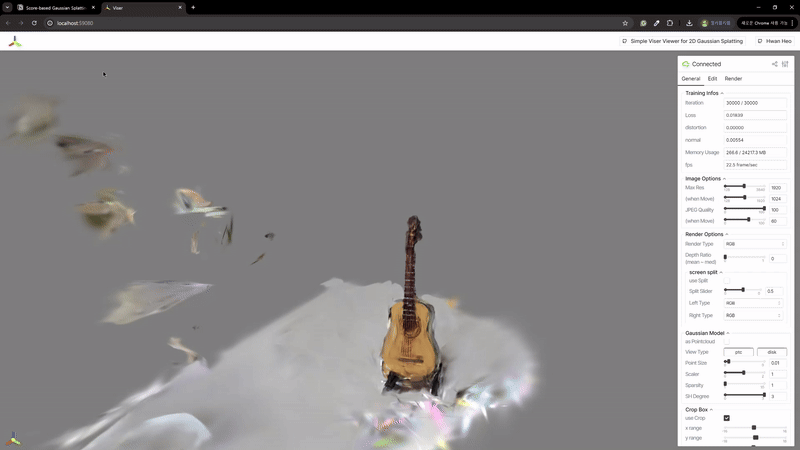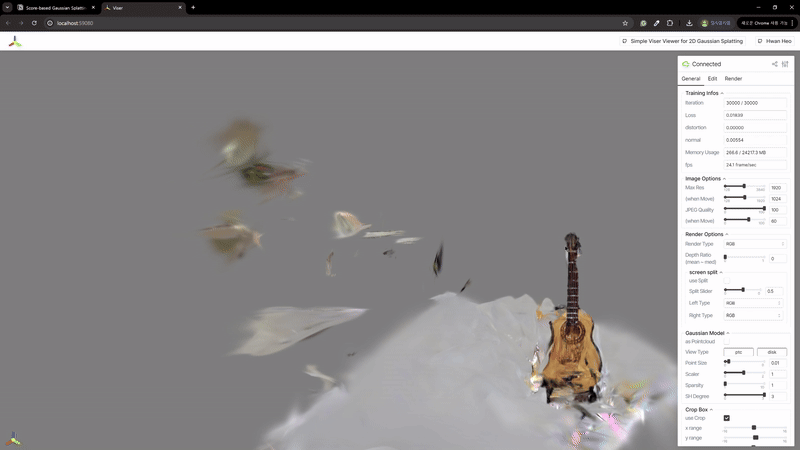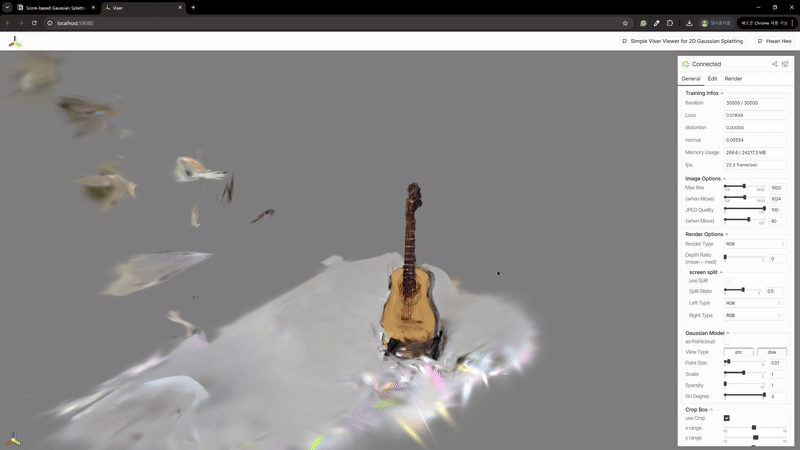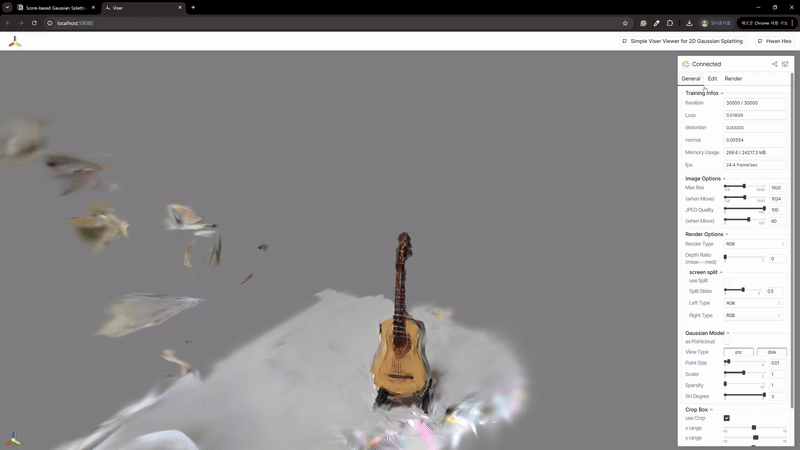 | 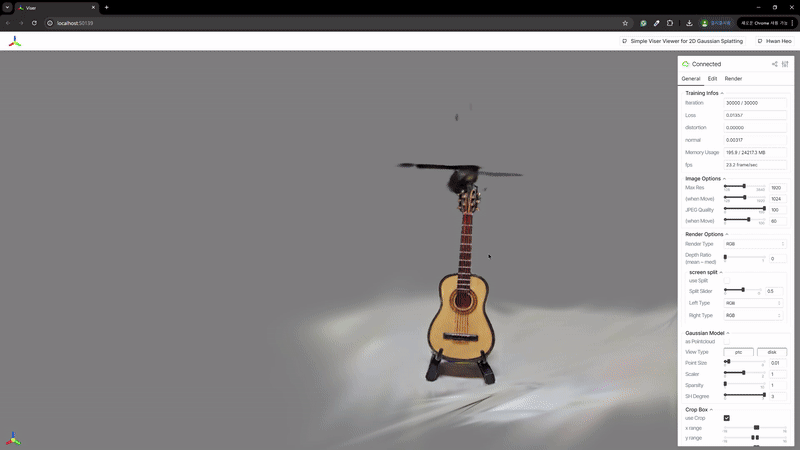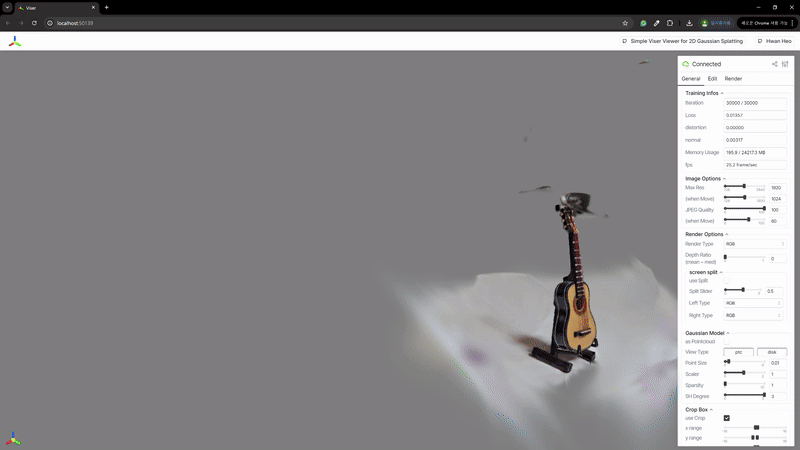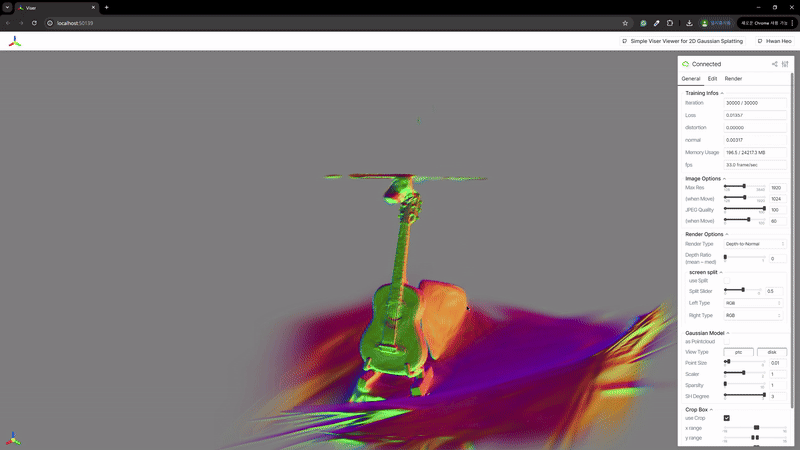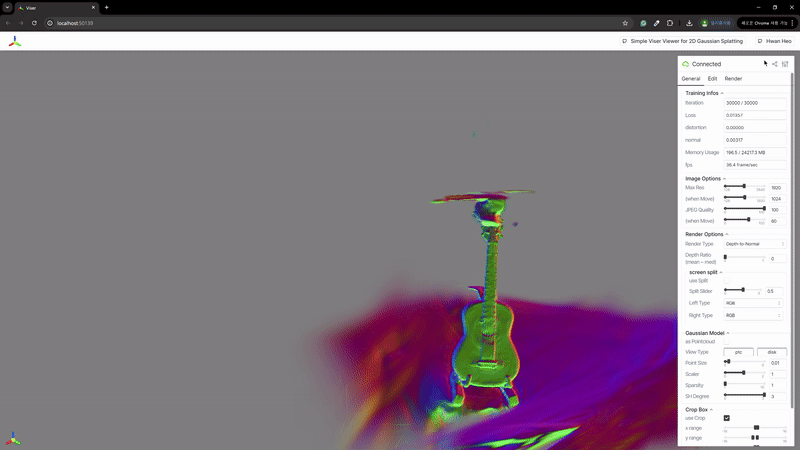 |
总结
MASt3R不适合反向渲染,但与VGGSfM相比,提供了更密集和多样化的点云重建。VGGSfM利用束调整实现的精确相机姿态重建使其更适合反向渲染。具体来说,VGGSfM的相机姿态与COLMAP相比角度距离误差小于0.01,而MASt3R的姿态误差超过0.1。
- 这两种方法都比COLMAP更稳健。在我的实验中,COLMAP无法重建上述所有数据集。
- 两种方法在有限的显存容量下都有缺点,但VGGSfM处理得更好。
- VGGSfM可以在单个RTX 4090上重建超过90张图像,而MASt3R在处理超过30张图像时就会遇到困难。
| COLMAP | VGGSfM |
|---|---|
 | 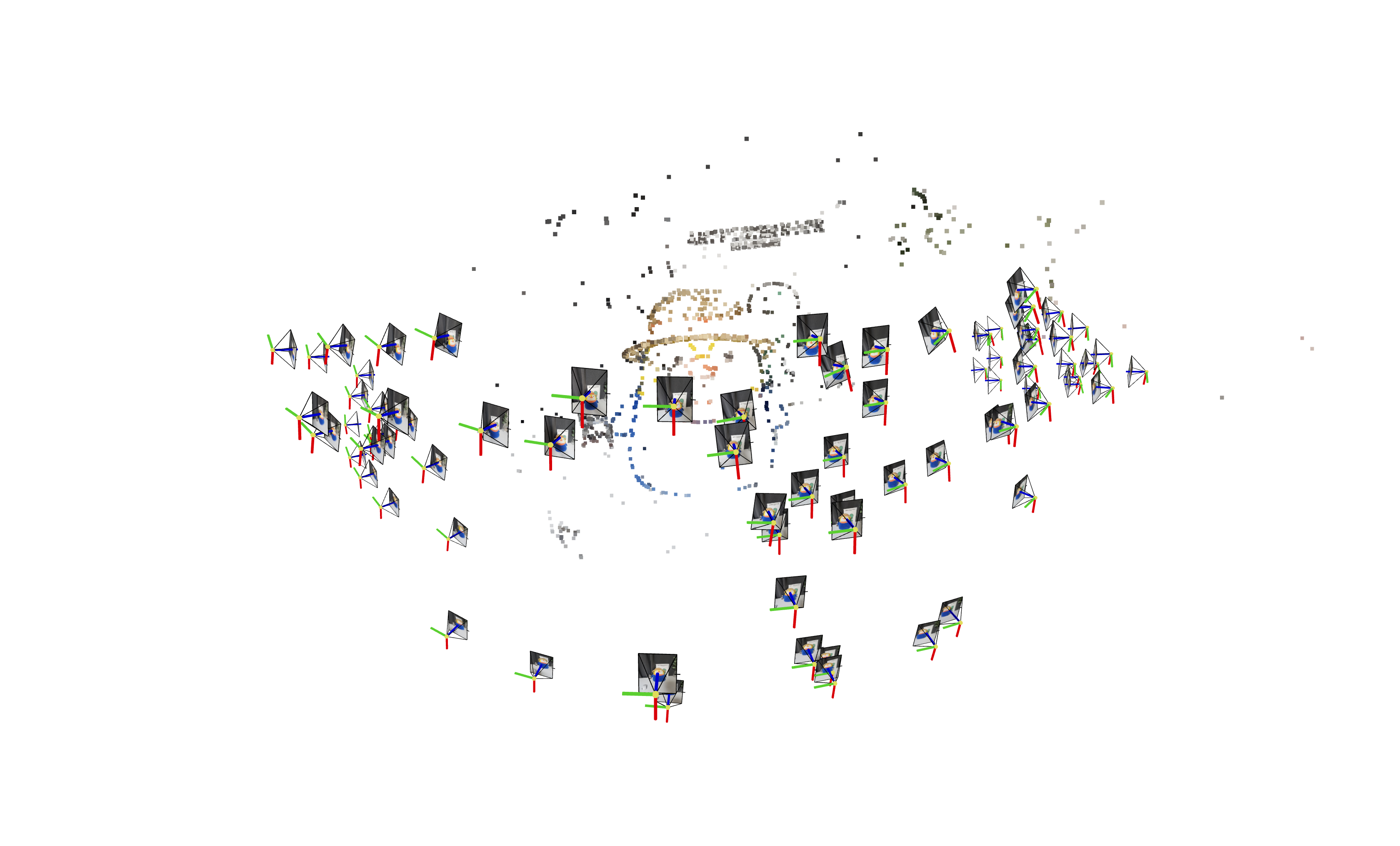 |
进一步的相机姿态优化
正如InstantSplat和问题#2中讨论的那样, MASt3R(和VGGSfM)的姿态可以作为辐射场训练过程中相机姿态优化的良好初始点(类BARF方法)。 以下是MASt3R + 进一步相机姿态优化(使用Splatfacto)的toy实验:
https://github.com/user-attachments/assets/d5b7ba98-7d51-4b20-a81e-6f5e4c00a79d
关于VGGSfM和Mast3r
VGGSfM:基于视觉几何的深度结构运动恢复
VGGSfM引入了一个全可微分的SfM管道,旨在将深度学习模型集成到SfM过程的每个阶段。该方法包括:
- 端到端可微分性:整个管道完全可微分,允许端到端训练和优化。
- 卓越的相机重建:提供高度准确的相机参数重建,有利于下游任务如神经渲染。
- 全局优化:同时优化所有相机姿态,避免增量方法的缺陷。
- 可微分束调整(BA):同时优化相机参数和3D点以最小化重投影误差。
MASt3R:使用MASt3R在3D中进行图像匹配
MASt3R通过集成密集局部特征预测和快速互惠匹配来增强立体匹配,基于Dust3r基线。它专注于利用立体视觉来改进3D点和相机参数估计。
- 密集匹配:擅长密集特征匹配,提供详细的3D重建。
- 注意力机制:利用图像对之间的交叉注意力进行强大的特征提取和匹配。
- 相机参数重建:不是主要关注点,导致相机姿态估计的准确性不如VGGSfM和COLMAP。











