
 Github
Github Huggingface
Huggingface 论文
论文AutoRound
用于大语言模型的高级量化算法
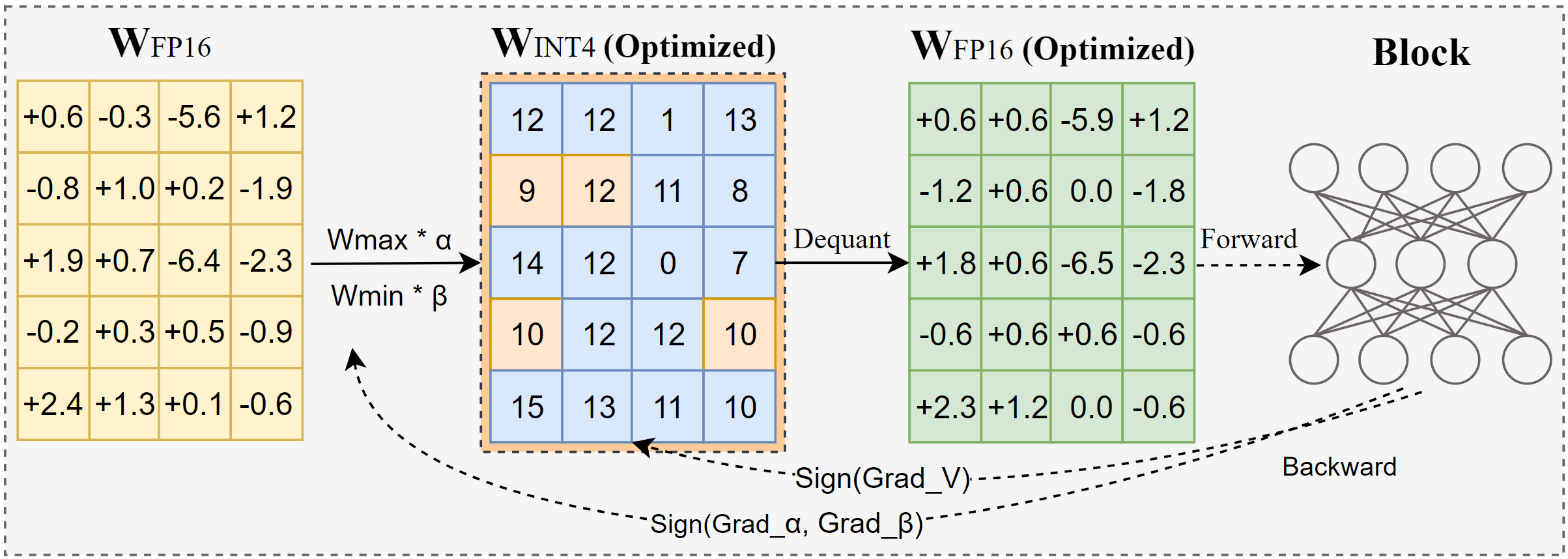
AutoRound是一种用于低位大语言模型推理的高级量化算法。它适用于广泛的模型。我们的方法采用符号梯度下降来微调权重的舍入值和最大最小值,只需200步就能与最新方法竞争,而且不会引入额外的推理开销,并保持较低的调优成本。下图展示了AutoRound的概述。更多详情请查看我们在arxiv上的论文,访问low_bit_open_llm_leaderboard可查看各种模型的更多准确性数据。
最新动态
- [2024/08] AutoRound格式支持Intel Gaudi2设备。示例请参考Intel/Qwen2-7B-int4-inc。
- [2024/08] AutoRound增加了几个实验性功能,如激活量化、mx_fp数据类型和范数/偏置参数的快速调优。
- [2024/07] 重要变更:nsamples的默认值从512改为128,以减少内存使用,在某些情况下可能会导致轻微的精度下降。
- [2024/06] AutoRound格式支持推理时混合位宽和组大小,解决了非对称内核导致的显著性能下降问题。
- [2024/05] AutoRound支持lm-head量化,在W4G128下为LLaMA3-8B节省0.7G内存。
先决条件
- Python 3.9或更高版本
安装
从源代码构建
pip install -vvv --no-build-isolation -e .
或
pip install -r requirements.txt
python setup.py install
从pypi安装
pip install auto-round
模型量化
Gaudi2/ CPU/ GPU
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "facebook/opt-125m"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
from auto_round import AutoRound
bits, group_size, sym = 4, 128, False
autoround = AutoRound(model, tokenizer, bits=bits, group_size=group_size, sym=sym)
autoround.quantize()
output_dir = "./tmp_autoround"
autoround.save_quantized(output_dir) ##save_quantized(output_dir,format="auto_gptq")
详细超参数
-
model: 要量化的PyTorch模型。 -
tokenizer: 用于处理输入数据的可选分词器。如果没有,必须提供数据集。 -
bits (int): 量化的位数(默认为4)。 -
group_size (int): 量化组的大小(默认为128)。 -
sym (bool): 是否使用对称量化(默认为False)。 -
enable_quanted_input (bool): 是否使用前一个量化块的输出作为当前块的输入进行调优(默认为True)。 -
enable_minmax_tuning (bool): 是否启用权重最小-最大值调优(默认为True)。 -
iters (int): 调优迭代次数(默认为200)。 -
lr (float): 舍入值的学习率(默认为None,将自动设置为1.0/iters)。 -
minmax_lr (float): 最小-最大值调优的学习率(默认为None,将自动设置为lr)。 -
nsamples (int): 用于调优的样本数(默认为128)。 -
seqlen (int): 用于调优的序列数据长度(默认为2048)。 -
batch_size (int): 训练的批量大小(默认为8)。 -
scale_dtype (str): 要使用的量化比例的数据类型(默认为"float16"),不同的内核有不同的选择。 -
amp (bool): 是否使用自动混合精度(默认为True)。 -
nblocks (int): 打包几个块作为一个进行调优(默认为1)。 -
gradient_accumulate_steps (int): 梯度累积步数(默认为1)。 -
low_gpu_mem_usage (bool): 是否以~20%更多调优时间为代价节省GPU内存(默认为False)。 -
dataset Union[str, list, tuple, torch.utils.data.DataLoader]: 用于调优的数据集名称(默认为"NeelNanda/pile-10k")。支持本地json文件和数据集组合,例如"./tmp.json,NeelNanda/pile-10k:train, mbpp:train+validation+test"。 -
layer_config (dict): 权重量化的配置(默认为空字典),主要用于混合位宽或混合精度。 -
device: 用于调优的设备。默认设置为'auto',允许自动检测。
提示
1 考虑增加'iters'(例如1000)以获得更好的结果,但会增加调优时间。
2 考虑增加'nsamples'(例如512)以获得更好的结果,但会使用更多内存(~20G)。
3 将'minmax_lr'设置为2.0/iters有时会产生更好的结果。
模型推理
请先运行量化代码
AutoRound格式
cuda: git clone https://github.com/intel/auto-round.git && cd auto-round && pip install -vvv --no-build-isolation -e .
cpu:
- 选项1: pip install auto-round && pip install intel-extension-for-transformers
- 选项2: git clone https://github.com/intel/auto-round.git && cd auto-round && pip install -vvv --no-build-isolation -e .
hpu: 推荐使用带有Gaudi软件栈的docker镜像。更多详情可以在Gaudi指南中找到。
Gaudi2/ CPU/ GPU
from transformers import AutoModelForCausalLM, AutoTokenizer
from auto_round import AutoRoundConfig
device = "auto" ##cpu, hpu, cuda
quantization_config = AutoRoundConfig(
backend=device
)
quantized_model_path = "./tmp_autoround"
model = AutoModelForCausalLM.from_pretrained(quantized_model_path,
device_map=device, quantization_config=quantization_config)
tokenizer = AutoTokenizer.from_pretrained(quantized_model_path)
text = "There is a girl who likes adventure,"
inputs = tokenizer(text, return_tensors="pt").to(model.device)
print(tokenizer.decode(model.generate(**inputs, max_new_tokens=50)[0]))
AutoGPTQ/AutoAWQ格式
1 请通过修改以下代码来保存量化模型:autoround.save_quantized(output_dir, format="auto_gptq") 或 autoround.save_quantized(output_dir, format="auto_awq")。
2 参考他们的仓库来推理模型。
支持列表
| 模型 | 支持 |
|---|---|
| Qwen/Qwen2-7B | HF-int4模型 |
| Qwen/Qwen2-57B-A14B-Instruct | HF-int4模型 |
| Intel/neural-chat-7b-v3-3 | HF-int4模型, 准确性, 配方, 示例 |
| Intel/neural-chat-7b-v3-1 | HF-int4模型, 准确性, 配方, 示例 |
| mistralai/Mistral-7B-v0.1 | HF-int4模型-lmhead, HF-int4模型, 准确性, 配方, 示例 |
| microsoft/phi-2 | HF-int4-sym模型, 准确性, 配方, 示例 |
| google/gemma-2b | HF-int4模型, 准确性, 配方, 示例 |
| tiiuae/falcon-7b | HF-int4模型-G64, 准确性, 配方, 示例 |
| mistralai/Mistral-7B-Instruct-v0.2 | HF-int4模型 (审核中), 准确性, 配方, 示例 |
| mistralai/Mixtral-8x7B-Instruct-v0.1 | HF-int4模型 (审核中), 准确性, 配方, 示例 |
| mistralai/Mixtral-8x7B-v0.1 | HF-int4模型 (审核中), 准确性, 配方, 示例 |
| meta-llama/Meta-Llama-3-8B-Instruct | 准确性, 配方, 示例 |
| google/gemma-7b | 准确性, 配方, 示例 |
| meta-llama/Llama-2-7b-chat-hf | 准确性, 配方, 示例 |
| Qwen/Qwen1.5-7B-Chat | 准确性, 对称配方, 非对称配方, 示例 |
| baichuan-inc/Baichuan2-7B-Chat | 准确性, 配方, 示例 |
| 01-ai/Yi-6B-Chat | 准确度, 配方, 示例 |
| facebook/opt-2.7b | 准确度, 配方, 示例 |
| bigscience/bloom-3b | 准确度, 配方, 示例 |
| EleutherAI/gpt-j-6b | 准确度, 配方, 示例 |
| Salesforce/codegen25-7b-multi | 示例 |
| huggyllama/llama-7b | 示例 |
| mosaicml/mpt-7b | 示例 |
| THUDM/chatglm3-6b | 示例 |
| MBZUAI/LaMini-GPT-124M | 示例 |
| EleutherAI/gpt-neo-125m | 示例 |
| databricks/dolly-v2-3b | 示例 |
| stabilityai/stablelm-base-alpha-3b | 示例 |
参考文献
如果您发现 AutoRound 对您的研究有用,请引用我们的论文:
@article{cheng2023optimize,
title={通过符号梯度下降优化权重舍入以实现大型语言模型的量化},
author={程文华 and 张伟伟 and 沈海浩 and 蔡一扬 and 何鑫 and 吕考考 and 刘毅},
journal={arXiv预印本 arXiv:2309.05516},
year={2023}
}











