
 访问官网
访问官网 Github
Github 文档
文档 论文
论文tidytext: 使用整洁工具进行文本挖掘 
作者: Julia Silge, David Robinson
许可证: MIT

![]()


使用整洁数据原则可以使许多文本挖掘任务变得更简单、更有效,并与已广泛使用的工具保持一致。用于整洁数据框进行文本挖掘所需的大部分基础设施已经存在于像dplyr、broom、tidyr和ggplot2这样的包中。在这个包中,我们提供了函数和支持数据集,允许文本与整洁格式之间的转换,并在整洁工具和现有文本挖掘包之间无缝切换。查看我们的书以了解更多关于使用整洁数据原则进行文本挖掘的信息。
安装
你可以从CRAN安装这个包:
install.packages("tidytext")
或者你可以使用remotes从GitHub安装开发版本:
library(remotes)
install_github("juliasilge/tidytext")
整洁文本挖掘示例:unnest_tokens函数
简·奥斯汀的小说可以如此整洁!让我们使用janeaustenr包中简·奥斯汀的6部完成并出版的小说的文本,并将它们转换为整洁格式。janeaustenr以每行一条记录的格式提供这些文本:
library(janeaustenr)
library(dplyr)
original_books <- austen_books() %>%
group_by(book) %>%
mutate(line = row_number()) %>%
ungroup()
original_books
#> # A tibble: 73,422 × 3
#> text book line
#> <chr> <fct> <int>
#> 1 "SENSE AND SENSIBILITY" Sense & Sensibility 1
#> 2 "" Sense & Sensibility 2
#> 3 "by Jane Austen" Sense & Sensibility 3
#> 4 "" Sense & Sensibility 4
#> 5 "(1811)" Sense & Sensibility 5
#> 6 "" Sense & Sensibility 6
#> 7 "" Sense & Sensibility 7
#> 8 "" Sense & Sensibility 8
#> 9 "" Sense & Sensibility 9
#> 10 "CHAPTER 1" Sense & Sensibility 10
#> # ℹ 73,412 more rows
要将其作为整洁数据集处理,我们需要将其重构为每行一个标记的格式。unnest_tokens()函数是将包含文本列的数据框转换为每行一个标记格式的方法:
library(tidytext)
tidy_books <- original_books %>%
unnest_tokens(word, text)
tidy_books
#> # 一个 tibble: 725,055 × 3
#> book line word
#>
#> 1 理智与情感 1 理智
#> 2 理智与情感 1 与
#> 3 理智与情感 1 情感
#> 4 理智与情感 3 作者
#> 5 理智与情感 3 简
#> 6 理智与情感 3 奥斯汀
#> 7 理智与情感 5 1811
#> 8 理智与情感 10 第
#> 9 理智与情感 10 1
#> 10 理智与情感 13 这
#> # ℹ 还有725,045行
这个函数使用tokenizers包将每行分割成单词。默认的分词是按词进行的,但其他选项包括字符、n-gram、句子、行、段落,或者根据正则表达式模式进行分割。
现在数据采用了每行一个单词的格式,我们可以用tidyverse工具如dplyr来操作它。我们可以通过anti_join()来移除停用词(可以通过get_stopwords()函数获取)。
tidy_books <- tidy_books %>%
anti_join(get_stopwords())
我们还可以使用count()来找出所有书籍中最常见的词。
tidy_books %>%
count(word, sort = TRUE)
#> # 一个 tibble: 14,375 × 2
#> word n
#> <chr> <int>
#> 1 先生 3015
#> 2 夫人 2446
#> 3 必须 2071
#> 4 说 2041
#> 5 很多 1935
#> 6 小姐 1855
#> 7 一个 1831
#> 8 很好 1523
#> 9 每个 1456
#> 10 认为 1440
#> # ℹ 还有14,365行
情感分析可以通过内连接来实现。通过get_sentiments()函数可以获得三种情感词典。让我们看看每部小说中情感是如何变化的。我们用Bing词典为每个单词找到一个情感得分,然后计算每部小说定义部分中正面和负面词的数量。
library(tidyr)
get_sentiments("bing")
#> # 一个 tibble: 6,786 × 2
#> word sentiment
#> <chr> <chr>
#> 1 两面派 负面
#> 2 异常 负面
#> 3 废除 负面
#> 4 可恶的 负面
#> 5 可恶地 负面
#> 6 憎恶 负面
#> 7 可憎之物 负面
#> 8 流产 负面
#> 9 已流产 负面
#> 10 流产 负面
#> # ℹ 还有6,776行
janeaustensentiment <- tidy_books %>%
inner_join(get_sentiments("bing"), by = "word", relationship = "many-to-many") %>%
count(book, index = line %/% 80, sentiment) %>%
pivot_wider(names_from = sentiment, values_from = n, values_fill = 0) %>%
mutate(sentiment = positive - negative)
janeaustensentiment
#> # 一个 tibble: 920 × 5
#> book index negative positive sentiment
#> <fct> <dbl> <int> <int> <int>
#> 1 理智与情感 0 16 32 16
#> 2 理智与情感 1 19 53 34
#> 3 理智与情感 2 12 31 19
#> 4 理智与情感 3 15 31 16
#> 5 理智与情感 4 16 34 18
#> 6 理智与情感 5 16 51 35
#> 7 理智与情感 6 24 40 16
#> 8 理智与情感 7 23 51 28
#> 9 理智与情感 8 30 40 10
#> 10 理智与情感 9 15 19 4
#> # ℹ 还有910行
现在我们可以绘制每部小说情节轨迹中的这些情感得分。
library(ggplot2)
ggplot(janeaustensentiment, aes(index, sentiment, fill = book)) +
geom_col(show.legend = FALSE) +
facet_wrap(vars(book), ncol = 2, scales = "free_x")
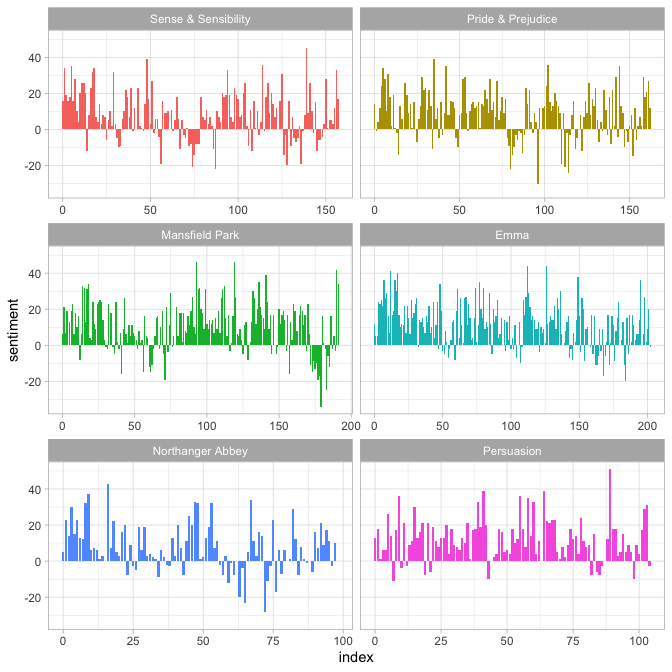
更多使用整洁数据框进行文本挖掘的例子,请参见tidytext的说明文档。
整理文档词条矩阵
一些现有的文本挖掘数据集采用DocumentTermMatrix类(来自tm包)的形式。例如,考虑topicmodels数据集中2246篇美联社文章的语料库。
library(tm)
data("AssociatedPress", package = "topicmodels")
AssociatedPress
#> <<DocumentTermMatrix (documents: 2246, terms: 10473)>>
#> 非稀疏/稀疏条目: 302031/23220327
#> 稀疏度 : 99%
#> 最大词长: 18
#> 权重 : 词频 (tf)
如果我们想用整洁工具分析这个数据,我们首先需要使用tidy()函数将其转换为每行一个词条的数据框。(关于tidy动词的更多信息,请参见broom包)。
tidy(AssociatedPress)
#> # A tibble: 302,031 × 3
#> document term count
#> <int> <chr> <dbl>
#> 1 1 adding 1
#> 2 1 adult 2
#> 3 1 ago 1
#> 4 1 alcohol 1
#> 5 1 allegedly 1
#> 6 1 allen 1
#> 7 1 apparently 2
#> 8 1 appeared 1
#> 9 1 arrested 1
#> 10 1 assault 1
#> # ℹ 还有302,021行
我们可以找出最消极的文档:
ap_sentiments <- tidy(AssociatedPress) %>%
inner_join(get_sentiments("bing"), by = c(term = "word")) %>%
count(document, sentiment, wt = count) %>%
pivot_wider(names_from = sentiment, values_from = n, values_fill = 0) %>%
mutate(sentiment = positive - negative) %>%
arrange(sentiment)
或者我们可以将奥斯汀和AP数据集连接起来,比较每个词的频率:
comparison <- tidy(AssociatedPress) %>%
count(word = term) %>%
rename(AP = n) %>%
inner_join(count(tidy_books, word)) %>%
rename(Austen = n) %>%
mutate(AP = AP / sum(AP),
Austen = Austen / sum(Austen))
comparison
#> # A tibble: 4,730 × 3
#> word AP Austen
#> <chr> <dbl> <dbl>
#> 1 abandoned 0.000170 0.00000493
#> 2 abide 0.0000291 0.0000197
#> 3 abilities 0.0000291 0.000143
#> 4 ability 0.000238 0.0000148
#> 5 able 0.000664 0.00151
#> 6 abroad 0.000194 0.000178
#> 7 abrupt 0.0000291 0.0000247
#> 8 absence 0.0000776 0.000547
#> 9 absent 0.0000436 0.000247
#> 10 absolute 0.0000533 0.000128
#> # ℹ 还有4,720行
library(scales)
ggplot(comparison, aes(AP, Austen)) +
geom_point(alpha = 0.5) +
geom_text(aes(label = word), check_overlap = TRUE,
vjust = 1, hjust = 1) +
scale_x_log10(labels = percent_format()) +
scale_y_log10(labels = percent_format()) +
geom_abline(color = "red")
<img src="https://yellow-cdn.veclightyear.com/0a4dffa0/6bcacba0-5d3d-46a1-879f-be3722ec89c1.png" alt="简·奥斯汀与美联社新闻文章中词频的散点图。一些词如"cried"只在简·奥斯汀作品中常见,一些词如"national"只在美联社文章中常见,而一些词如"time"在两者中都很常见。" width="100%" />
关于使用整洁数据原则处理其他文本挖掘包中的对象的更多示例,请参见关于文档词条矩阵转换的说明文档。
社区指南
本项目发布时附带贡献者行为准则。参与本项目即表示您同意遵守其条款。欢迎提供反馈、错误报告(和修复!)以及功能请求;请在此处提交问题或寻求支持。












{kind=link}