
 访问官网
访问官网 Github
Github 论文
论文openlogprobs
🪄 openlogprobs 是一个用于从语言模型 API 中提取对数概率的 Python API 🪄
pip install openlogprobs


许多基于 API 的语言模型服务隐藏了其模型的对数概率输出。一个原因是安全性 - 语言模型输出可能会泄露有关其输入的信息,并可用于高效的模型蒸馏。另一个原因是实际考虑:通过 API 提供 30,000(或其他词汇量大小)个浮点数对于典型的 API 请求来说会占用太多数据。因此,这些信息对您是隐藏的。
然而,大多数 API 也允许使用"logit bias"参数来正面或负面地影响语言模型输出中某些标记的可能性。事实证明,我们可以利用这个 logit bias 对单个标记进行反向工程,从而得到它们的对数概率。我们开发了一种算法来高效地完成这一任务,这实际上允许我们通过像 OpenAI API 这样的 API 提取完整的概率向量。有关该算法的更多信息,请阅读下面的算法部分,或阅读 openlogprobs/extract.py 中的代码。
使用方法
topk 搜索
如果 API 暴露了 top-k 对数概率,我们可以通过"topk"算法高效地提取下一个标记的概率:
from openlogprobs import extract_logprobs
extract_logprobs("gpt-3.5-turbo-instruct", "i like pie", method="topk")
精确解
如果 API 暴露了 top-k 对数概率,我们可以通过"exact"算法每次提取 k 个标记的下一个标记概率:
from openlogprobs import extract_logprobs
extract_logprobs("gpt-3.5-turbo-instruct", "i like pie", method="exact", parallel=True)
这种方法比 top-k 算法需要更少的 API 调用(每 k 个标记只需 1 次调用)。
二分搜索
如果 API 不暴露 top-k 对数概率,我们仍然可以提取分布,但需要更多的语言模型调用:
from openlogprobs import extract_logprobs
extract_logprobs("gpt-3.5-turbo-instruct", "i like pie", method="bisection")
未来工作(欢迎帮助!)
- 支持多个对数概率(并发二分搜索)
- 估算各种 API 的成本
- 支持检查点
算法
二分法和 top-k
我们的算法本质上是一个二分搜索(技术上是连续变量上的"单变量二分法"),我们应用不同程度的 logit bias 使某些标记有足够高的概率出现在生成中。这允许我们估计任何标记相对于最可能标记的概率。为了获得完整的概率向量,我们可以对词汇表中的每个标记运行这个二分搜索。请注意,几乎所有模型都支持 logit bias,为了使其工作,所有支持 logit bias 的模型都必须是开放词汇的。
以下是我们算法如何处理单个标记的粗略可视化:
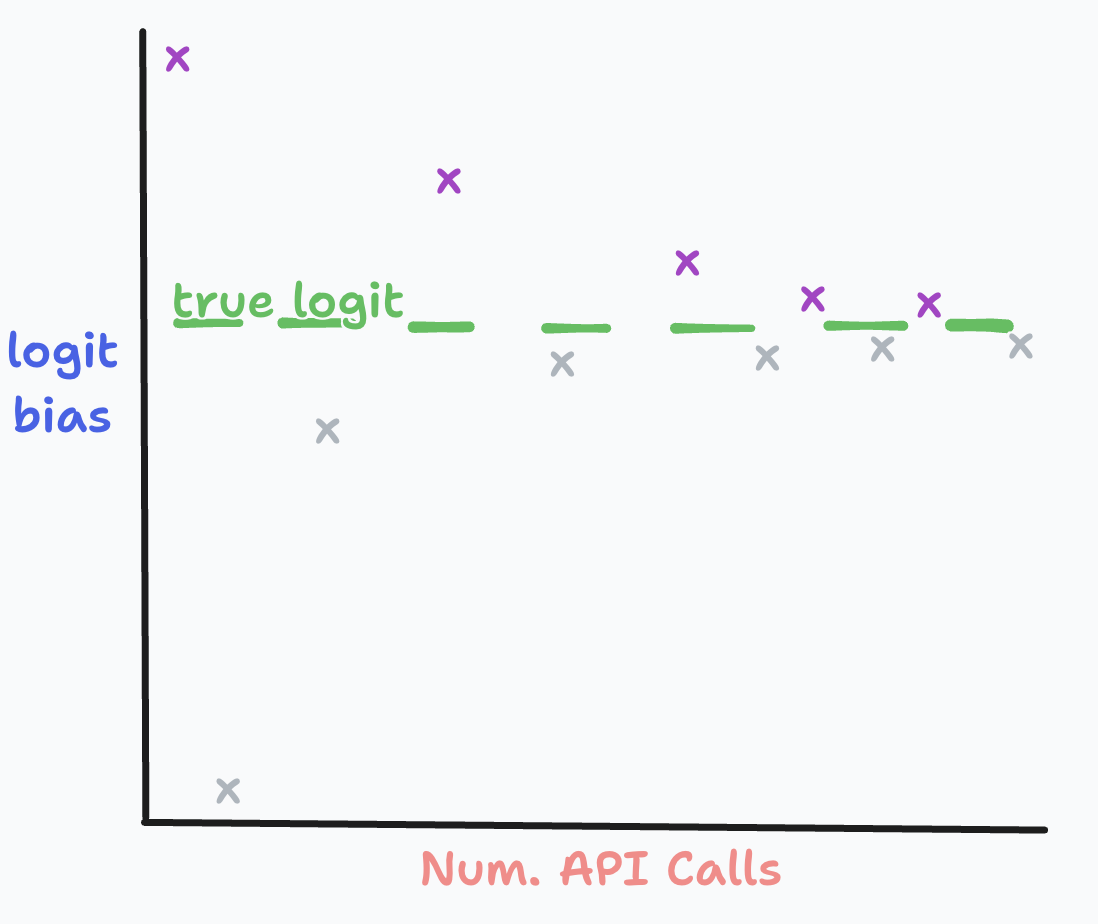
每次 API 调用(紫色)都会使我们逐渐接近真实的标记概率(绿色)。
精确解
我们的精确解算法直接求解对数概率。 要理解数学原理,请参阅这个概述。
语言模型反演论文
这个算法主要由 Justin Chiu 开发,用于促进《语言模型反演》论文的研究。如果您在学术研究中使用我们的算法,请引用我们的论文:
精确解算法由 Matthew Finlayson 贡献。
@misc{morris2023language,
title={Language Model Inversion},
author={John X. Morris and Wenting Zhao and Justin T. Chiu and Vitaly Shmatikov and Alexander M. Rush},
year={2023},
eprint={2311.13647},
archivePrefix={arXiv},
primaryClass={cs.CL}
}











