
 Github
Github Huggingface
Huggingface 论文
论文EasyContext

内存优化和训练方案,用于将语言模型的上下文长度扩展到100万个token,仅需最小的硬件要求。
更新
- [06/25] EasyContext是我们开发LongVA(一个长上下文视觉语言模型)的一部分。如果你感兴趣,可以查看一下!
- [05/11] 添加了Ulysses。
- [05/06] 在NIAH评估脚本中添加了干扰项(多针)。你可以使用--num_distractor设置干扰项的数量。
- [05/06] 重要!如果你想使用eval_needle.py评估llama3模型,你需要在QUESTION_STR后面额外添加一个空格(" ")。我认为这与分词器有关。
这是什么?
许多公司一直在宣传他们的模型处理长上下文的能力。对于公司以外的人来说,100万个token的上下文似乎仍然有些神奇,或者需要巨大的计算资源。这个仓库旨在揭开长上下文扩展的神秘面纱,展示它实际上相当简单直接。
这个仓库并不提出新的想法。相反,我们展示了如何结合现有技术来训练具有以下上下文长度的语言模型:
- 使用8个A100(Llama2-7B)实现70万。
- 使用16个A100(Llama2-13B)实现100万。
没有使用任何近似方法。这些模型可以进行完全微调、全注意力和全序列长度的训练。我们的训练脚本(train.py)代码不到200行。
使用的技术包括:
- 序列并行。
- Deepspeed zero3 offload。
- Flash attention及其融合交叉熵核。
- 激活检查点。
我们支持不同的序列并行方法:
- 环形注意力(Shenggui等人;Liu等人,特别是Zilin的实现)
- 分布式flash注意力(之前称为LightSeq。Li等人)
- Deepspeed Ulysses(Jacobs等人和Jiarui的实现)
然后,我们在8个A100上训练Llama-2-7B,通过逐步增加其rope基频到1B。值得注意的是,我们的模型仅用512K序列长度进行训练,但可以泛化到近100万的上下文。
使用方法
from easy_context import prepare_seq_parallel_inputs, apply_seq_parallel_monkey_patch, prepare_dataloader
from transformers import LlamaForCausalLM
# 将注意力实现从flash attn切换为dist_ring_attn或zigzag_ring_attn
apply_seq_parallel_monkey_patch("dist_flash_attn", "llama")
# 确保启用flash_attention_2
model = LlamaForCausalLM.from_pretrained(model_name, _attn_implementation="flash_attention_2")
accelerator = ...
train_dataloader = ...
prepare_dataloader("dist_flash_attn", train_dataloader, accelerator)
# 在你的训练循环中...
for step, batch in enumerate(train_dataloader):
# 分片序列
prepared = prepare_seq_parallel_inputs("dist_flash_attn", batch["input_ids"], batch["position_ids"], batch["target_ids"], accelerator.process_index, accelerator.num_processes, accelerator.device)
local_input_ids = prepared["local_input_ids"]
local_position_ids = prepared["local_position_ids"]
local_target_ids = prepared["local_target_ids"]
# 然后照常进行模型前向传播
logits = model(local_input_ids,position_ids=local_position_ids,).logits
结果
大海捞针测试
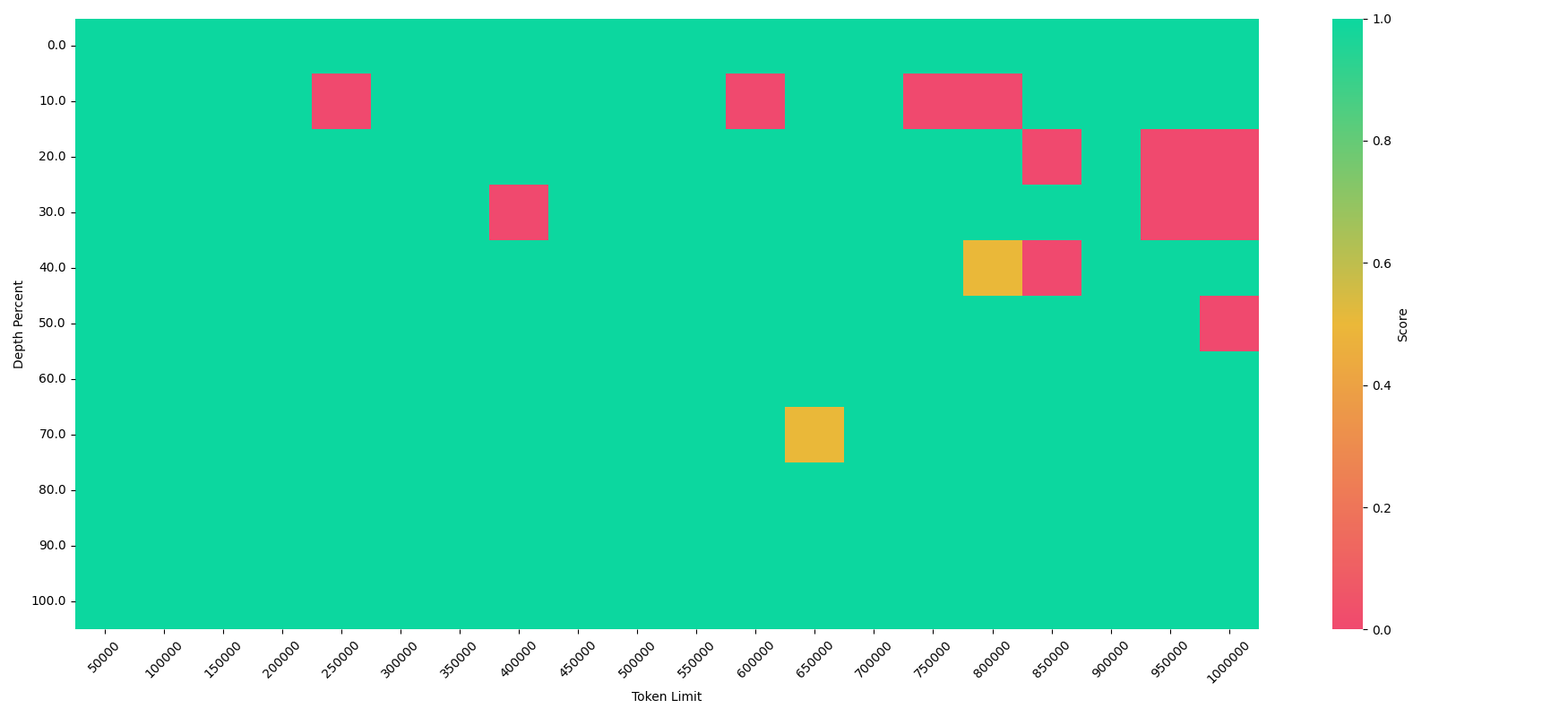
仍然存在一些红色方块。我不确定指令微调或更强的长上下文训练是否会有所帮助。
困惑度
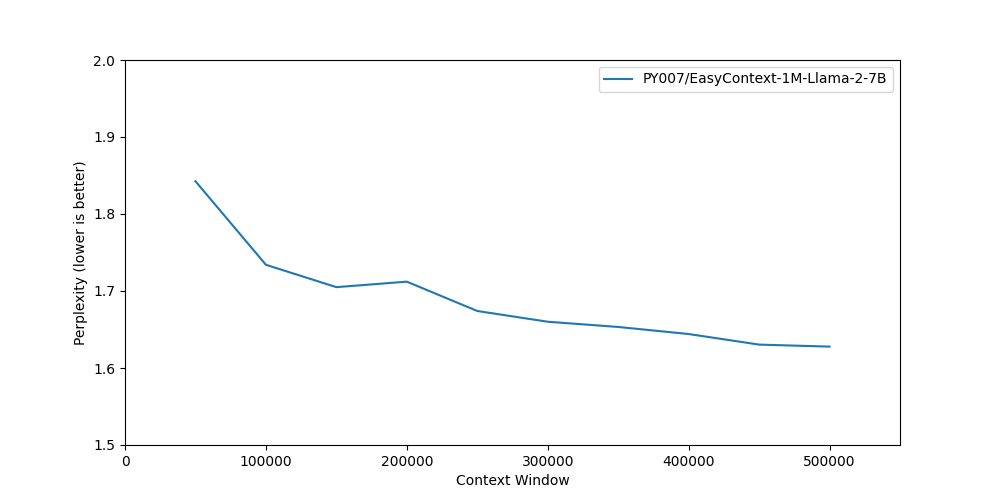
在proofpile测试集中找到的两个长度为50万到60万的最长文档上进行测试。
安装
代码在Python 3.10.0、PyTorch 2.4.0(nightly版)和CUDA 11.8上测试通过。
conda create -n easycontext python=3.10 -y && conda activate easycontext
pip install --pre torch==2.4.0.dev20240324 --index-url https://download.pytorch.org/whl/nightly/cu118
pip install packaging && pip install ninja && pip install flash-attn --no-build-isolation --no-cache-dir
pip install -r requirements.txt
请注意,PyTorch nightly版是必需的,因为我发现PyTorch 2.2.0在8个A100上处理70万上下文长度时会出现OOM问题。
评估
大海捞针
accelerate launch --num_processes 8 --config_file accelerate_configs/deepspeed_inference.yaml --main_process_port 6000 eval_needle.py \
--model PY007/EasyContext-1M-Llama-2-7B \
--max_context_length 1000000 \
--min_context_length 50000 \
--context_interval 50000 \
--depth_interval 0.1 \
--num_samples 2 \
--rnd_number_digits 7 \
--haystack_dir PaulGrahamEssays
上述命令大约需要6小时。要减少时间,可以考虑增加context_interval和depth_interval。
困惑度
在proofpile测试中,只有两个文档长度超过500K。
accelerate launch --config_file accelerate_configs/deepspeed_inference.yaml --num_processes 8 --main_process_port 6000 eval_ppl.py \
--tokenized emozilla/proofpile-test-tokenized \
--dataset-min-tokens 500000 \
--samples 2 \
--output-file data/debug.csv \
--min-tokens 50000 \
--max-tokens 500000 \
--tokens-step 50000 \
--truncate \
--aggressive-memory \
-m PY007/EasyContext-1M-Llama-2-7B
python plot.py data/debug.csv --xmax 550000 --ymax 2 --ymin 1.5
训练
请参见train_scripts/
速度
从数据并行切换到环形注意力会导致吞吐量略有下降,但不显著。然而,当我们增加序列长度时,由于自注意力的二次复杂度,吞吐量会显著下降。我不认为这是由于环形注意力中通信成本的增加,因为GPU利用率几乎始终保持在100%。吞吐量是在8个A100上使用Llama-7B模型测量前5个训练步骤得出的,所以预计会有一些变化。
| 设置 | 8个A100的吞吐量 |
|---|---|
| 64K,数据并行 | 10240 tokens/s |
| 64K,环形注意力 | 7816 tokens/s |
| 128K,环形注意力 | 4266 tokens/s |
| 512K,环形注意力 | 2133 tokens/s |
| 700K,环形注意力 | 1603 tokens/s |
我还记得两年前有很多关于稀疏注意力是否相关的讨论,一个重要的反驳论点是自注意力的二次复杂度并不占主导地位。我认为在长上下文时代,是时候重新审视这个问题了。
待办事项
- 切换到猴子补丁实现。
- 添加分布式快速注意力。
- 设置pip包。
- EasyContext-Llama-2-13B-1M,如果有空余计算资源。
- 指令微调。
- EasyContext-Mistral-7B-1M,如果有空余计算资源。
- 添加PoSE。
我们没有明确的待办事项时间表。欢迎社区贡献和合作。请随时提出问题或拉取请求。
一些随机想法
直到现在,处理视频生成模型中的长序列一直被认为是一个巨大挑战。 我相信8个A100在训练期间可以容纳700K上下文的7B transformer这一事实不仅对语言模型来说很酷;对视频生成也是巨大的进步。 700K的上下文长度意味着我们现在可以微调/生成1500帧,假设每帧包含512个tokens。 这意味着如果有一天Meta或其他人开源,我们至少可以进行微调。 此外,编码器型transformer的一个好处是我们不需要存储KV缓存,这是一个巨大的内存节省。
致谢
本工作建立在以下论文/仓库的基础之上:
引用
如果您觉得这项工作有用,请通过以下方式引用:
@article{zhang2024longva,
title={Long Context Transfer from Language to Vision},
author={Peiyuan Zhang and Kaichen Zhang and Bo Li and Guangtao Zeng and Jingkang Yang and Yuanhan Zhang and Ziyue Wang and Haoran Tan and Chunyuan Li and Ziwei Liu},
journal={arXiv preprint arXiv:2406.16852},
year={2024},
url = {https://arxiv.org/abs/2406.16852}
}
同时也请考虑给个星标 >_<











