
 Github
Github 论文
论文具有注意力汇聚的高效流式语言模型
https://github.com/mit-han-lab/streaming-llm/assets/40906949/2bd1cda4-a0bd-47d1-a023-fbf7779b8358
简介
我们部署大语言模型以处理无限长度输入,同时不牺牲效率和性能。
新闻
- [2024/02] StreamingLLM 被 MIT 新闻作为聚焦报道!
- [2024/01] StreamingLLM 被 HPC-AI Tech 的 SwiftInfer 集成,支持大语言模型推理的无限输入长度。
- [2024/01] StreamingLLM 被 NVIDIA 的 TensorRT-LLM 集成!
- [2023/12] StreamingLLM 被卡内基梅隆大学、华盛顿大学和 OctoAI 集成,实现在 iPhone 上无限且高效的大语言模型生成!
- [2023/12] StreamingLLM 被 HuggingFace Transformers PR 集成。
- [2023/10] StreamingLLM 被集成到 Intel Extension for Transformers。
- [2023/10] Attention Sinks,一个第三方实现,使 StreamingLLM 能够在更多 Huggingface 大语言模型上使用。
摘要
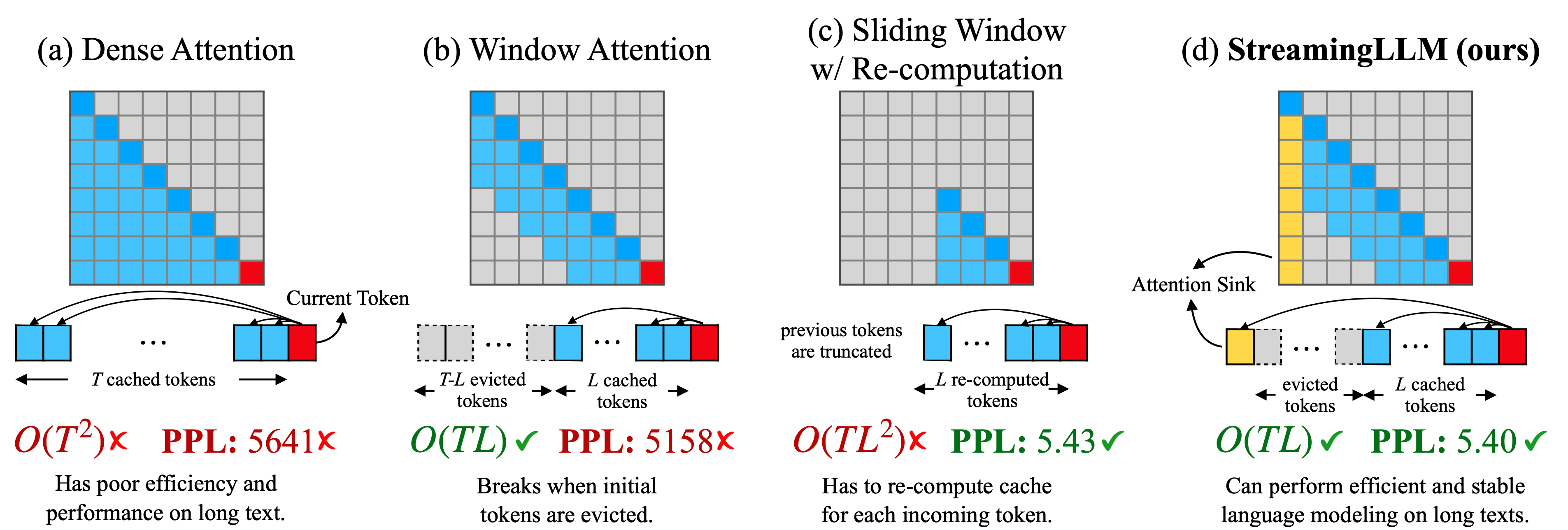
在流式应用中部署大语言模型(LLMs),如多轮对话等需要长时间交互的场景,是当前迫切需要但面临两大挑战的任务。首先,在解码阶段,缓存先前词元的键值(KV)状态会消耗大量内存。其次,流行的大语言模型无法泛化到超出训练序列长度的更长文本。窗口注意力机制,即只缓存最近的 KV,是一种自然的方法——但我们发现当文本长度超过缓存大小时,它会失效。我们观察到一个有趣的现象,即注意力汇聚:保留初始词元的 KV 将在很大程度上恢复窗口注意力的性能。本文中,我们首先证明注意力汇聚的出现是由于即使初始词元在语义上并不重要,它们也会获得强烈的注意力分数,成为一个"汇聚点"。基于以上分析,我们提出了 StreamingLLM,这是一个高效的框架,使得在有限长度注意力窗口下训练的大语言模型能够泛化到无限序列长度,无需任何微调。我们展示了 StreamingLLM 可以使 Llama-2、MPT、Falcon 和 Pythia 进行稳定且高效的语言建模,处理长达 400 万个词元及以上的序列。此外,我们发现在预训练过程中添加一个占位符词元作为专用的注意力汇聚点可以进一步改善流式部署。在流式设置中,StreamingLLM 的性能优于滑动窗口重新计算基线,速度提升最高可达 22.2 倍。
使用方法
环境配置
conda create -yn streaming python=3.8
conda activate streaming
pip install torch torchvision torchaudio
pip install transformers==4.33.0 accelerate datasets evaluate wandb scikit-learn scipy sentencepiece
python setup.py develop
运行流式 Llama 聊天机器人
CUDA_VISIBLE_DEVICES=0 python examples/run_streaming_llama.py --enable_streaming
常见问题
-
对大语言模型来说,"处理无限长度输入"意味着什么?
用大语言模型处理无限长度文本存在挑战。主要是,存储所有先前的键值(KV)状态需要大量内存,且模型可能难以生成超出其训练序列长度的文本。StreamingLLM 通过仅保留最近的词元和注意力汇聚点,丢弃中间词元来解决这个问题。这使模型能够从最近的词元生成连贯的文本,无需重置缓存——这是之前方法所不具备的能力。
-
大语言模型的上下文窗口是否被扩展了?
没有。上下文窗口保持不变。只保留最近的词元和注意力汇聚点,丢弃中间词元。这意味着模型只能处理最新的词元。上下文窗口仍受其初始预训练的限制。例如,如果 Llama-2 预训练时的上下文窗口为 4096 个词元,那么 StreamingLLM 在 Llama-2 上的最大缓存大小仍为 4096。
-
我可以将一个很长的文本,比如一本书,输入到 StreamingLLM 中进行摘要吗?
虽然你可以输入一个长文本,但模型只会识别最新的词元。因此,如果输入一本书,StreamingLLM 可能只会总结最后几段,这可能并不太有意义。如前所述,我们既没有扩展大语言模型的上下文窗口,也没有增强它们的长期记忆。StreamingLLM 的优势在于能够从最近的词元生成流畅的文本,而无需刷新缓存。
-
StreamingLLM 的理想使用场景是什么?
StreamingLLM 针对流式应用进行了优化,如多轮对话。它适用于需要持续运行而不需要大量内存或依赖过去数据的场景。一个例子是基于大语言模型的日常助手。StreamingLLM 可以让模型持续运行,根据最近的对话做出响应,而无需刷新缓存。早期的方法要么需要在对话长度超过训练长度时重置缓存(丢失最近的上下文),要么需要从最近的文本历史重新计算 KV 状态,这可能会很耗时。
-
StreamingLLM 与最近的上下文扩展工作有什么关系?
StreamingLLM 与最近的上下文扩展方法是正交的,可以与它们集成。在 StreamingLLM 的上下文中,"上下文扩展"指的是使用更大的缓存大小来存储更多最近的词元的可能性。有关实际演示,请参考我们论文中的图 9,其中我们使用 LongChat-7B-v1.5-32K 和 Llama-2-7B-32K-Instruct 等模型实现了 StreamingLLM。
待办事项
我们将按以下顺序发布代码和数据,敬请关注!
- 发布 StreamingLLM 的核心代码,包括 Llama-2、MPT、Falcon 和 Pythia。
- 发布困惑度评估代码
- 发布流式 Llama 聊天机器人演示。
- 发布 StreamEval 数据集和评估代码。
引用
如果您发现 StreamingLLM 对您的项目和研究有用或相关,请引用我们的论文:
@article{xiao2023streamingllm,
title={Efficient Streaming Language Models with Attention Sinks},
author={Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike},
journal={arXiv},
year={2023}
}











