
 访问官网
访问官网 Github
Github 文档
文档 论文
论文Kaggle-PANDA-1st名解决方案
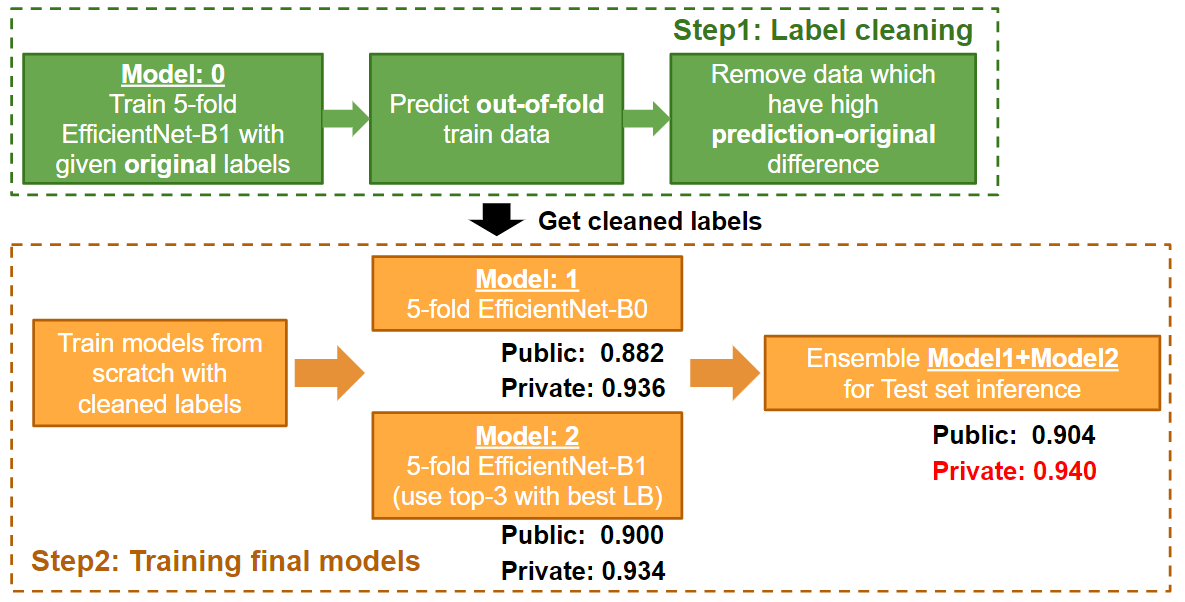
代码和模型由PND团队的@yukkyo和@kentaroy47创建。
我们的模型和代码根据CC-BY-NC 4.0许可开源。具体细节请参见LICENSE文件。
你可以跳过一些步骤(因为一些输出已经在input目录中)。
使用于
Nature Medicine: W.Bulten, 人工智能用于前列腺癌的诊断和Gleason分级:PANDA挑战
npj Precision Oncology: Y.Tolkach, 前列腺癌检测和Gleason分级算法的国际多机构验证研究
Cancers: 前列腺癌组织病理学图像自动癌症分级的标签分布学习
描述我们解决方案的幻灯片!
https://docs.google.com/presentation/d/1Ies4vnyVtW5U3XNDr_fom43ZJDIodu1SV6DSK8di6fs/
1. 环境
你可以选择是否使用docker。
1.1 不使用docker(未经测试..)
- Ubuntu 18.04
- Python 3.7.2
- CUDA 10.2
- 安装NVIDIA/apex == 1.0
# 主要依赖
$ pip install -r docker/requirements.txt
# arutema代码依赖
$ pip install git+https://github.com/ildoonet/pytorch-gradual-warmup-lr.git
$ pip install efficientnet_pytorch
1.2 使用docker(推荐)
# 构建
$ sh docker/build.sh
# 运行
$ sh docker/run.sh
# 执行
$ sh docker/exec.sh
2. 准备
2.1 获取数据
仅下载train_images和train_masks。
$ cd input
$ kaggle download ...
$ unzip ...
(跳过)2.2 根据图像哈希阈值对图像ID进行分组
- 如果你想自己做:https://www.kaggle.com/yukkyo/imagehash-to-detect-duplicate-images-and-grouping
- 我们将直接放置脚本的输出:
input/duplicate_imgids_imghash_thres_090.csv
(跳过)2.3 分割K折
$ cd src
$ python data_process/s00_make_k_fold.py
- 使用固定种子保持一致
- 输出:
input/train-5kfold.csv
2.4 为训练制作瓦片PNG
$ cd src
$ python data_process/s07_simple_tile.py --mode 0
$ python data_process/s07_simple_tile.py --mode 2
$ python data_process/a00_save_tiles.py
$ cd ../input
$ cd numtile-64-tilesize-192-res-1-mode-0
$ unzip train.zip -d train
$ cd ..
$ cd numtile-64-tilesize-192-res-1-mode-2
$ unzip train.zip -d train
$ cd ..
3. 训练基础模型以去除噪声(预期使用1块TitanRTX)
每个折叠需要约18小时。
$ cd src
$ python train.py --config configs/final_1.yaml --kfold 1
$ python train.py --config configs/final_1.yaml --kfold 2
$ python train.py --config configs/final_1.yaml --kfold 3
$ python train.py --config configs/final_1.yaml --kfold 4
$ python train.py --config configs/final_1.yaml --kfold 5
- 输出:
output/model/final_1- 每个权重和训练日志
4. 对本地验证进行预测以去除噪声
每个折叠需要约1小时。
$ cd src
$ python kernel.py --kfold 1
$ python kernel.py --kfold 2
$ python kernel.py --kfold 3
$ python kernel.py --kfold 4
$ python kernel.py --kfold 5
- 输出是保留训练数据的预测结果:
output/model/final_1/local_preds~~~.csv
5. 去除噪声
$ cd src
$ python data_process/s12_remove_noise_by_local_preds.py
- 输出:
output/model/final_1local_preds_final_1_efficientnet-b1.csv- 保留数据的拼接预测结果
- 用于清理标签
local_preds_final_1_efficientnet-b1_removed_noise_thresh_16.csv- 用于训练模型1
- 基础标签清理结果
local_preds_final_1_efficientnet-b1_removed_noise_thresh_rad_13_08_ka_15_10.csv- 用于训练模型2
- 清理标签以移除20%的Radboud标签
- 注意:我们在比赛最终提交时使用了这个csv文件:(当时未固定随机种子)
input/train-5kfold_remove_noisy_by_0622_rad_13_08_ka_15_10.csv
6. 用移除噪声后的数据重新训练5折模型
-
你可以在配置中将
output/train-5kfold_remove_noisy.csv替换为input/train-5kfold_remove_noisy_by_0622_rad_13_08_ka_15_10.csv -
最终推理只使用了第1、4、5折
-
每折大约需要15小时。
训练模型2(fam_taro模型):
$ cd src
# 只训练LB最佳的折
$ python train.py --config configs/final_2.yaml --kfold 1
$ python train.py --config configs/final_2.yaml --kfold 4
$ python train.py --config configs/final_2.yaml --kfold 5
训练模型1(arutema模型):
请在Jupyter notebook上运行train_famdata-kfolds.ipynb或
# 进入主目录
$ python train_famdata-kfolds.py
我尚未测试.py文件,所以请尝试使用.ipynb文件操作。
最终模型保存在models中。
每折大约需要4小时。
训练好的模型
复现第一名得分的模型保存在./final_models中
7. 在Kaggle Notebook上提交
- kernels
- 比赛最终提交:
- 得分: 公榜0.904, 私榜0.940 (第1名)
- 网址: https://www.kaggle.com/yukkyo/latesub-pote-fam-aru-ensemble-0722-ew-1-0-0?scriptVersionId=39271011
- 复现结果 (固定随机种子,可复现)
- 得分: 公榜0.894, 私榜0.939 (第1名)
- 网址: https://www.kaggle.com/kyoshioka47/late-famrepro-fam-reproaru-ensemble-0725?scriptVersionId=39879219
submitted_notebook.ipynb
- 简单5折模型获得私榜0.935(第3名)
- 比赛最终提交:
- 你可以通过更改以下内容来修改路径。
- 使用你复现的权重时必须更改Kaggle数据集路径
### 模型2
# 第[7]行
class Config:
def __init__(self, on_kernel=True, kfold=1, debug=False):
...
...
...
# 你可以更改权重名称。但在本README中不需要
self.weight_name = "final_2_efficientnet-b1_kfold_{}_latest.pt"
self.weight_name = self.weight_name.format(kfold)
...
...
...
def get_weight_path(self):
if self.on_kernel:
# 你应该将此路径更改为你的Kaggle数据集路径
return os.path.join("../input/030-weight", self.weight_name)
else:
dir_name = self.weight_name.split("_")[0]
return os.path.join("../output/model", dir_name, self.weight_name)
### 模型1
# 第[13]行
def load_models(model_files):
models = []
for model_f in model_files:
## 你应该将此路径更改为你的Kaggle数据集路径
model_f = os.path.join("../input/latesubspanda", model_f)
...
model_files = [
'efficientnet-b0famlabelsmodelsub_avgpool_tile36_imsize256_mixup_final_epoch20_fold0.pth',
]
model_files2 = [
'efficientnet-b0famlabelsmodelsub_avgpool_tile36_imsize256_mixup_final_epoch20_fold0.pth',
"efficientnet-b0famlabelsmodelsub_avgpool_tile36_imsize256_mixup_final_epoch20_fold1.pth",
"efficientnet-b0famlabelsmodelsub_avgpool_tile36_imsize256_mixup_final_epoch20_fold2.pth",
"efficientnet-b0famlabelsmodelsub_avgpool_tile36_imsize256_mixup_final_epoch20_fold3.pth",
"efficientnet-b0famlabelsmodelsub_avgpool_tile36_imsize256_mixup_final_epoch20_fold4.pth"
]











