
 访问官网
访问官网 Github
Github 文档
文档OpenGPTs
这是一项旨在创建类似于OpenAI的GPTs和Assistants API体验的开源努力。 它由LangGraph驱动 - 这是一个用于创建智能体运行时的框架。 它还基于LangChain、LangServe和LangSmith构建。 OpenGPTs给予你更多控制权,允许你配置:
- 你使用的LLM(从LangChain提供的60多个中选择)
- 你使用的提示(使用LangSmith来调试它们)
- 你给予它的工具(从LangChain的100多个工具中选择,或轻松编写你自己的工具)
- 你使用的向量数据库(从LangChain的60多个向量数据库集成中选择)
- 你使用的检索算法
- 你使用的聊天历史数据库
最重要的是,它让你完全控制应用程序的认知架构。 目前,实现了三种不同的架构:
- 助手
- RAG
- 聊天机器人
更多详细信息请见下文。 由于这是开源的,如果你不喜欢这些架构或想要修改它们,你可以轻松做到!
重要链接
使用Docker快速开始
本项目支持基于Docker的设置,简化了安装和执行过程。它自动为前端和后端构建镜像,并使用docker-compose设置Postgres。
-
先决条件:
确保你的系统上安装了Docker和docker-compose。 -
克隆仓库:
通过克隆仓库获取项目文件。git clone https://github.com/langchain-ai/opengpts.git cd opengpts -
设置环境变量:
在项目根目录创建一个.env文件,复制.env.example作为模板,并添加以下环境变量:# 至少需要一个语言模型API密钥 OPENAI_API_KEY=sk-... # LANGCHAIN_TRACING_V2=true # LANGCHAIN_API_KEY=... # Postgres设置。Docker compose将使用这些值来设置数据库。 POSTGRES_PORT=5432 POSTGRES_DB=opengpts POSTGRES_USER=postgres POSTGRES_PASSWORD=...将
sk-...替换为你的OpenAI API密钥,将...替换为你的LangChain API密钥。 -
使用Docker Compose运行:
在项目根目录执行:docker compose up此命令从各自的Dockerfile构建前端和后端的Docker镜像,并启动所有必要的服务,包括Postgres。
-
访问应用:
服务运行后,在http://localhost:5173访问前端,将5173替换为指定的端口号。 -
更改后重建:
如果你对前端或后端进行了更改,重新构建Docker镜像以反映这些更改。运行:docker compose up --build此命令使用你的最新更改重新构建镜像并重启服务。
不使用Docker的快速开始
先决条件 以下说明假设你的系统上已安装Python 3.11+。我们强烈建议使用虚拟环境来管理依赖项。
例如,如果你使用pyenv,可以使用以下命令创建新的虚拟环境:
pyenv install 3.11
pyenv virtualenv 3.11 opengpts
pyenv activate opengpts
一旦设置好Python环境,你就可以安装项目依赖:
后端服务使用poetry来管理依赖。
pip install poetry
pip install langchain-community
安装Postgres和Postgres向量扩展
brew install postgresql pgvector
brew services start postgresql
配置持久层
后端使用Postgres保存代理配置和聊天消息历史。 为了使用此功能,你需要设置以下环境变量:
export POSTGRES_HOST=localhost
export POSTGRES_PORT=5432
export POSTGRES_DB=opengpts
export POSTGRES_USER=postgres
export POSTGRES_PASSWORD=...
创建数据库
createdb opengpts
连接到数据库并创建postgres角色
psql -d opengpts
CREATE ROLE postgres WITH LOGIN SUPERUSER CREATEDB CREATEROLE;
安装Golang Migrate
数据库迁移使用golang-migrate管理。
在MacOS上,你可以使用brew install golang-migrate安装。其他操作系统或Golang工具链的说明可以在这里找到。
安装golang-migrate后,你可以运行所有迁移:
make migrate
这将使后端能够使用Postgres作为向量数据库并创建初始表。
安装后端依赖
cd backend
poetry install
替代向量数据库
上述说明使用Postgres作为向量数据库, 尽管你可以轻松切换到使用LangChain中的50多个向量数据库中的任何一个。
设置语言模型
默认情况下,这使用OpenAI,但也有Azure OpenAI和Anthropic的选项。 如果你使用这些,可能需要设置不同的环境变量。
export OPENAI_API_KEY="sk-..."
可以使用其他语言模型,要使用它们,你需要设置更多的环境变量。
请参阅下面关于LLMs的部分,了解如何配置Azure OpenAI、Anthropic和Amazon Bedrock。
设置工具
默认情况下,这里使用了很多工具。 其中一些需要额外的环境变量。 你不需要使用所有这些工具,启动应用程序也不需要这些环境变量 (只有在调用特定工具时才需要)。
有关需要启用的环境变量的完整列表,请参阅下面的工具部分。
设置监控
设置LangSmith。 这是可选的,但它将有助于调试、日志记录和监控。 在上面的链接注册,然后设置相关的环境变量
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_API_KEY=...
启动后端服务器
make start
启动前端
cd frontend
npm install
npm run dev
导航到http://localhost:5173/并开始使用!
将数据从Redis迁移到Postgres
参考这个指南将数据从Redis迁移到Postgres。
功能
我们尽可能努力实现与OpenAI功能上的对等。
- 沙盒 - 提供一个环境来导入、测试和修改现有聊天机器人。
- 使用的聊天机器人都是代码形式,所以很容易编辑
- 自定义动作 - 使用OpenAPI规范为你的聊天机器人定义额外功能
- 通过添加工具来支持
- 知识文件 - 附加额外的文件供你的聊天机器人参考
- 从UI或API上传文件,由检索工具使用
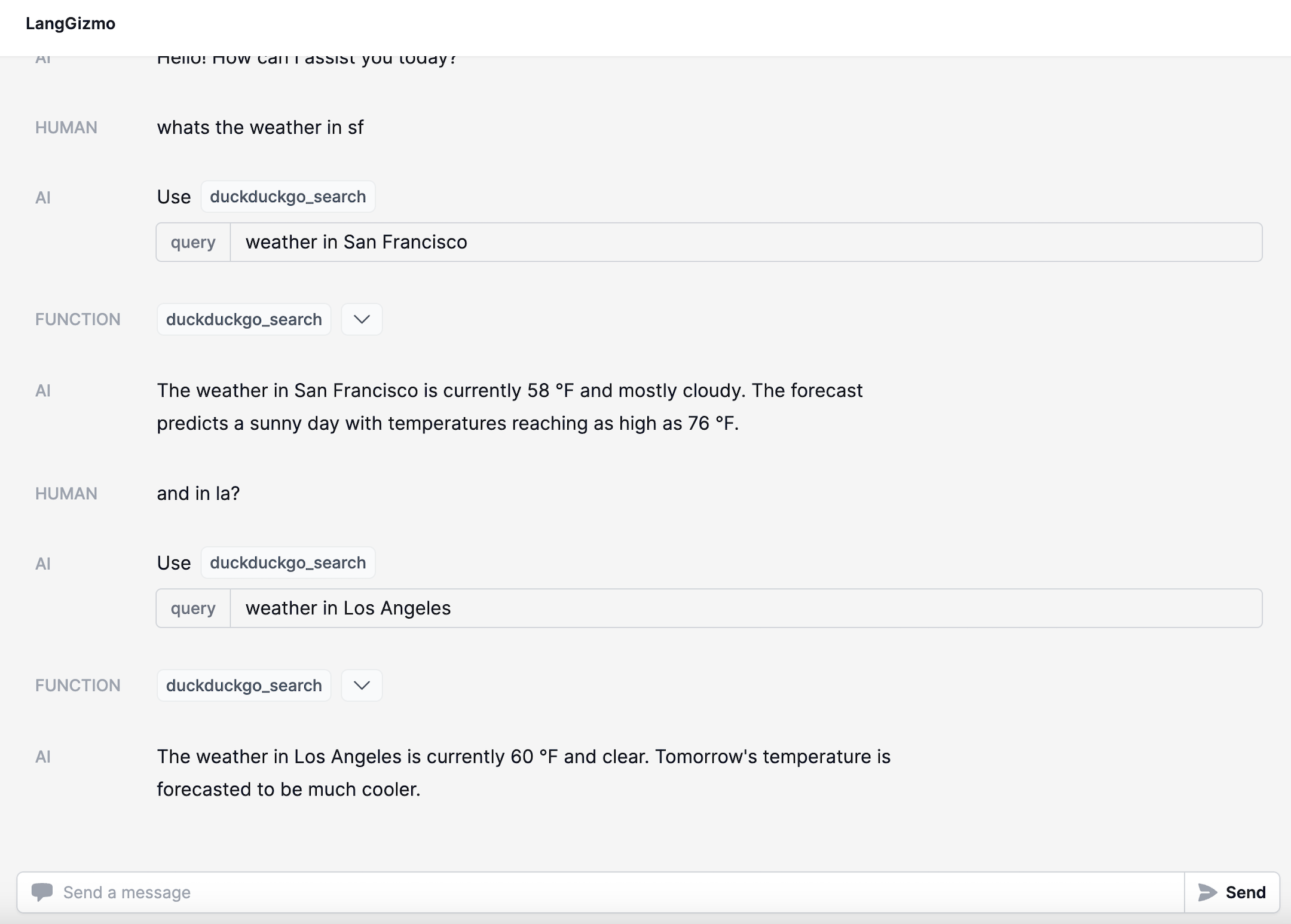
- 工具 - 提供基本的网页浏览、图像创建等工具。
- 默认启用基本的DuckDuckGo和PythonREPL工具
- 图像创建功能即将推出
- 分析 - 查看和分析聊天机器人使用数据
- 使用LangSmith实现此功能
- 草稿 - 保存和分享你正在创建的聊天机器人草稿
- 支持保存配置
- 发布 - 公开分发你完成的聊天机器人
- 可以通过LangServe部署实现
- 分享 - 设置和管理聊天机器人分享
- 可以通过LangServe部署实现
- 市场 - 搜索和部署其他用户创建的聊天机器人
- 即将推出
仓库结构
frontend: 前端代码backend: 后端代码app: LangServe代码(用于暴露API)packages: 核心逻辑agent-executor: 代理运行时gizmo-agent: 代理配置
自定义
与直接使用OpenAI相比,OpenGPTs的一大优势在于它更易于自定义。 具体来说,你可以选择使用哪些语言模型,并更容易添加自定义工具。 如果你愿意,你还可以直接使用底层API并自己构建自定义UI。
认知架构
这指的是GPT工作的逻辑。 目前支持三种不同的架构,但由于它们都是用LangGraph编写的,所以很容易修改它们或添加你自己的架构。
支持的三种不同架构是助手、RAG和聊天机器人。
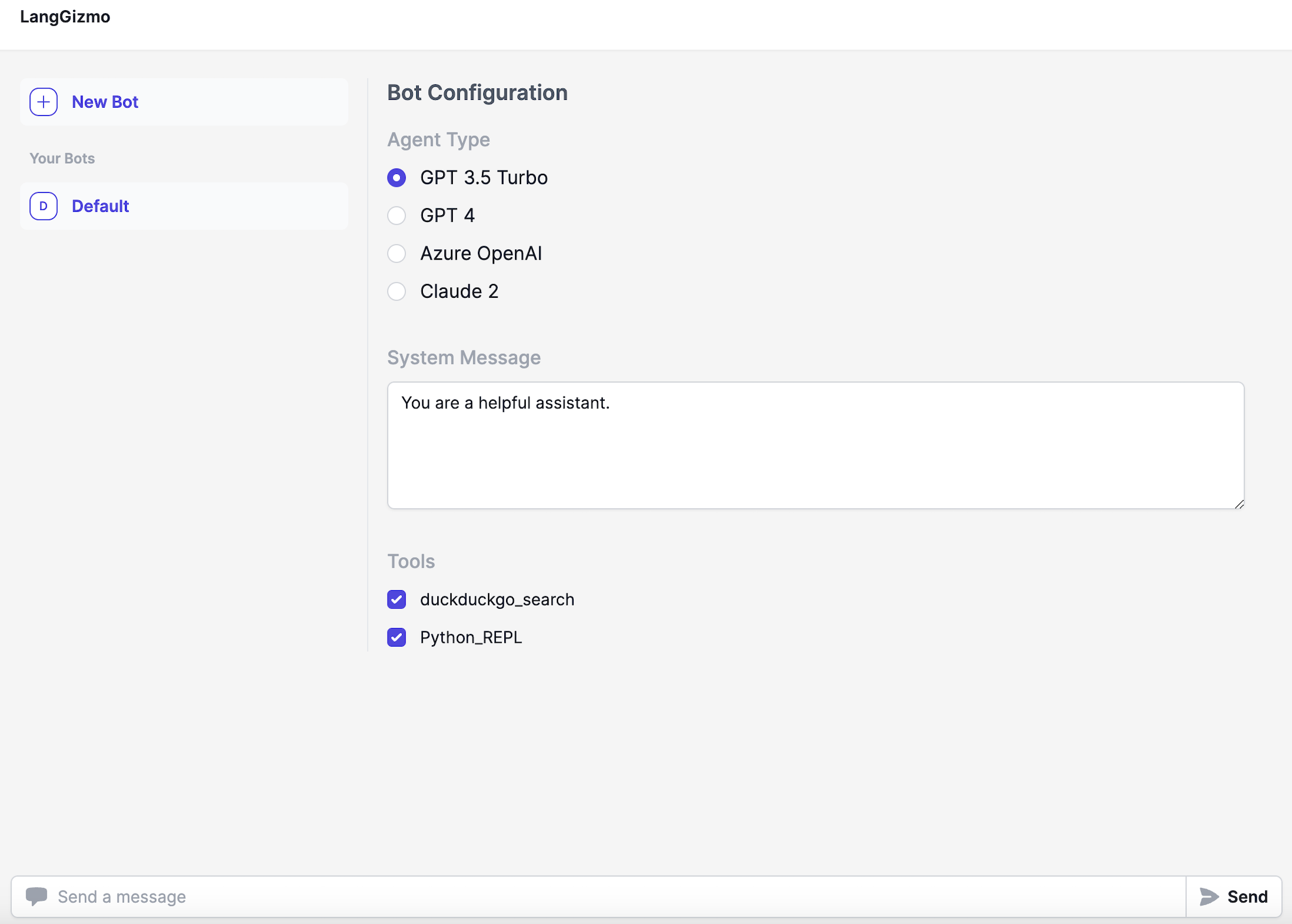
助手
助手可以配备任意数量的工具,并使用LLM来决定何时使用它们。这使它们成为最灵活的选择,但它们只能与较少的模型一起工作得很好,可能不太可靠。
创建助手时,你需要指定几件事。
首先,你选择要使用的语言模型。只有少数几个语言模型可以可靠地使用:GPT-3.5、GPT-4、Claude和Gemini。
其次,你选择要使用的工具。这些可以是预定义的工具或由上传文件构建的检索器。你可以选择任意数量的工具。
认知架构可以被看作是一个循环。首先,调用LLM来确定要采取的行动(如果有的话)。如果它决定采取行动,那么这些行动会被执行,然后循环回去。如果决定不采取任何行动,那么LLM的响应就是最终响应,循环结束。
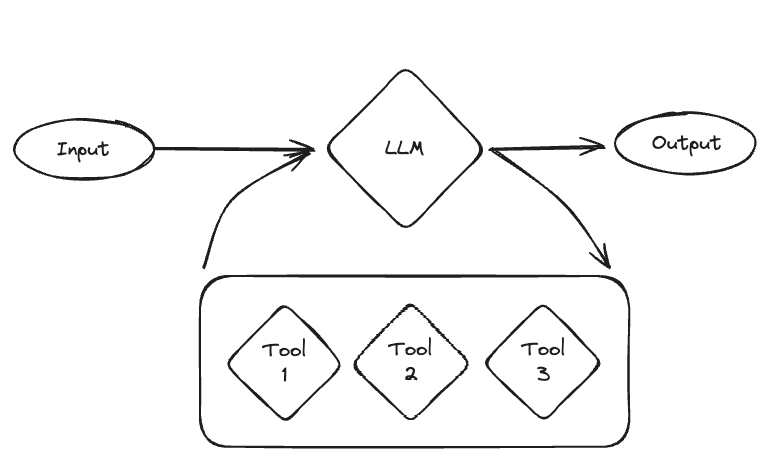
这可以是一个非常强大和灵活的架构。这可能最接近我们人类的运作方式。然而,这些也可能不太可靠,通常只能与性能更好的模型一起工作(即使如此,它们也可能出错)。因此,我们引入了一些更简单的架构。
助手是用LangGraph MessageGraph实现的。MessageGraph是一个将其状态建模为消息列表的图。
RAGBot
GPT商店的一个主要用例是上传文件并让机器人了解这些文件。如何构建一个更专注于这个用例的架构呢?
我们添加了RAGBot - 一个以检索为重点的GPT,具有直接的架构。首先,检索一组文档。然后,这些文档被传递到系统消息中,再单独调用语言模型进行响应。
与助手相比,它更加结构化(但功能较弱)。它总是会查找信息 - 如果你知道你想查找东西,这很好,但如果用户只是想进行正常对话,这可能会浪费资源。同样重要的是,这只查找一次 - 所以如果没有找到正确的结果,就会产生糟糕的结果(相比之下,助手可以决定再次查找)。
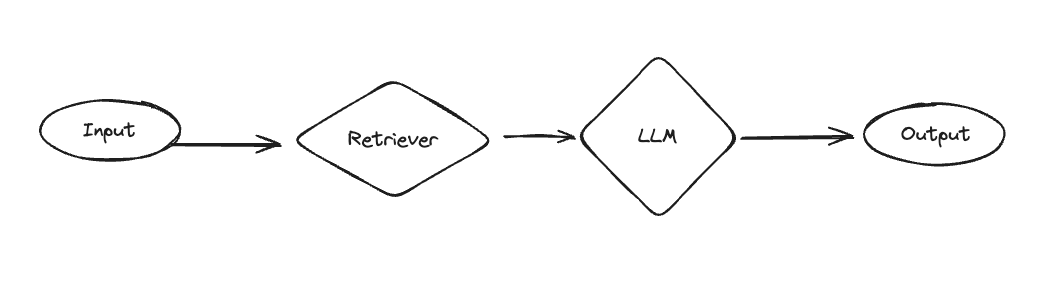 尽管这是一个较为简单的架构,但它有几个优点。首先,由于其简单性,它可以很好地适用于各种模型(包括许多开源模型)。其次,如果你有一个不需要助手灵活性的用例(例如,你知道用户每次都是在查找信息),那么它可以更加专注。第三,与下面的最终架构相比,它可以使用外部知识。
尽管这是一个较为简单的架构,但它有几个优点。首先,由于其简单性,它可以很好地适用于各种模型(包括许多开源模型)。其次,如果你有一个不需要助手灵活性的用例(例如,你知道用户每次都是在查找信息),那么它可以更加专注。第三,与下面的最终架构相比,它可以使用外部知识。
RAGBot 是使用 LangGraph StateGraph 实现的。StateGraph 是一个通用图,可以建模任意状态(即 dict),而不仅仅是消息列表。
ChatBot
最终的架构非常简单 - 只是对语言模型的调用,由系统消息参数化。这允许 GPT 采用不同的角色和特征。这显然不如 Assistants 或 RAGBots(可以访问外部数据/计算源)强大 - 但它仍然有价值!许多流行的 GPT 本质上只是系统消息,而 CharacterAI 也主要依靠系统消息就取得了巨大成功。
ChatBot 是使用 LangGraph StateGraph 实现的。StateGraph 是一个通用图,可以建模任意状态(即 dict),而不仅仅是消息列表。
LLMs
你可以选择使用不同的 LLM。 这利用了 LangChain 的众多集成。 需要注意的是,根据你使用的 LLM,你可能需要改变提示方式。
我们默认提供了四种代理类型:
- "GPT 3.5 Turbo"
- "GPT 4"
- "Azure OpenAI"
- "Claude 2"
当我们有信心它们能很好地工作时,我们会努力添加更多。
如果你想添加自己的 LLM 或代理配置,或想编辑现有的配置,可以在 backend/app/agent_types 中找到它们。
Claude 2
如果使用 Claude 2,你需要设置以下环境变量:
export ANTHROPIC_API_KEY=sk-...
Azure OpenAI
如果使用 Azure OpenAI,你需要设置以下环境变量:
export AZURE_OPENAI_API_BASE=...
export AZURE_OPENAI_API_VERSION=...
export AZURE_OPENAI_API_KEY=...
export AZURE_OPENAI_DEPLOYMENT_NAME=...
Amazon Bedrock
如果使用 Amazon Bedrock,你需要在 ~/.aws/credentials 中有有效的凭证,或设置以下环境变量:
export AWS_ACCESS_KEY_ID=...
export AWS_SECRET_ACCESS_KEY=...
工具
开源的一个重大优势是你可以更容易地添加工具(直接在 Python 中)。
实际上,我们看到大多数团队都定义自己的工具。 在 LangChain 中很容易做到这一点。 有关如何最好地做到这一点的详细信息,请参阅此指南。
如果你想使用一些预配置的工具,包括:
Sema4.ai Action Server
使用 Sema4.ai Action Server 运行基于 AI 的 Python 操作。 不需要服务 API 密钥,但需要定义正在运行的 Action Server 实例的凭证。 这些在创建助手时设置。
Connery Actions
使用 Connery 将 OpenGPTs 连接到现实世界。
需要设置一个环境变量,你可以在 Connery Runner 设置过程中获得:
CONNERY_RUNNER_URL=https://your-personal-connery-runner-url
CONNERY_RUNNER_API_KEY=...
DuckDuckGo 搜索
使用 DuckDuckGo 搜索网络。不需要任何 API 密钥。
Tavily 搜索
使用 Tavily 搜索引擎。需要设置一个环境变量:
export TAVILY_API_KEY=tvly-...
在这里注册 API 密钥。
Tavily 搜索(仅答案)
使用 Tavily 搜索引擎。 这只返回答案,没有支持证据。 当你需要简短回复时(小上下文窗口)很有用。 需要设置一个环境变量:
export TAVILY_API_KEY=tvly-...
在这里注册 API 密钥。
You.com 搜索
使用 You.com 搜索,为 LLM 优化的响应。 需要设置一个环境变量:
export YDC_API_KEY=...
在这里注册 API 密钥。
SEC 文件(Kay.ai)
使用 Kay.ai 搜索 SEC 文件。 需要设置一个环境变量:
export KAY_API_KEY=...
在这里注册 API 密钥。
新闻稿(Kay.ai)
使用 Kay.ai 搜索新闻稿。 需要设置一个环境变量:
export KAY_API_KEY=...
在这里注册 API 密钥。
Arxiv
搜索 Arxiv。不需要任何 API 密钥。
PubMed
搜索 PubMed。不需要任何 API 密钥。
Wikipedia
搜索 Wikipedia。不需要任何 API 密钥。
部署
通过 Cloud Run 部署
1. 构建前端
cd frontend
yarn
yarn build
2. 部署到 Google Cloud Run
你可以使用以下命令部署到 GCP Cloud Run:
首先创建一个 .env.gcp.yaml 文件,内容来自 .env.gcp.yaml.example,并填入相应的值。然后运行:
gcloud run deploy opengpts --source . --port 8000 --env-vars-file .env.gcp.yaml --allow-unauthenticated \
--region us-central1 --min-instances 1
在 Kubernetes 中部署
我们有一个用于将后端部署到 Kubernetes 的 Helm chart。您可以在这里找到更多信息: README.md











