
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档
英文 | 简体中文
Awesome-ChatTTS 是官方推荐的 ChatTTS 资源汇总项目,欢迎在 issues 中推荐或者自荐。
如果觉得本项目对你了解和使用 ChatTTS 有帮助,还请打赏个 ⭐️ 支持一下。
[!NOTE] 以下项目均为社区资源,查看官方信息请到源仓库 2noise/ChatTTS 。
官方简介
https://github.com/libukai/Awesome-ChatTTS/assets/5654585/532bfb80-316a-4244-9b92-301c732e8b63
快速体验
| 网址 | 类型 |
|---|---|
| Original Web | 原版网页版体验 |
| Forge Web | Forge 增强版体验 |
| Linux | Python 安装包 |
| Samples | 音色种子示例 |
| Cloning | 音色克隆体验 |
热门分支
功能增强
| 项目 | Star | 亮点 |
|---|---|---|
| jianchang512/ChatTTS-ui |  | 提供 API 接口,可在第三方应用中调用 |
| 6drf21e/ChatTTS_colab |  | 提供流式输出,支持长音频生成和分角色阅读 |
| lenML/ChatTTS-Forge |  | 提供人声增强和背景降噪,可使用附加提示词 |
| CCmahua/ChatTTS-Enhanced |  | 支持文件批量处理,以及导出 SRT 文件 |
| HKoon/ChatTTS-OpenVoice |  | 配合 OpenVoice 进行声音克隆 |
功能扩展
| 项目 | Star | 亮点 |
|---|---|---|
| 6drf21e/ChatTTS_Speaker |  | 音色角色打标与稳定性评估 |
| AIFSH/ComfyUI-ChatTTS |  | ComfyUi 版本,可作为工作流节点引入 |
| MaterialShadow/ChatTTS-manager |  | 提供了音色管理系统和 WebUI 界面 |
界面说明
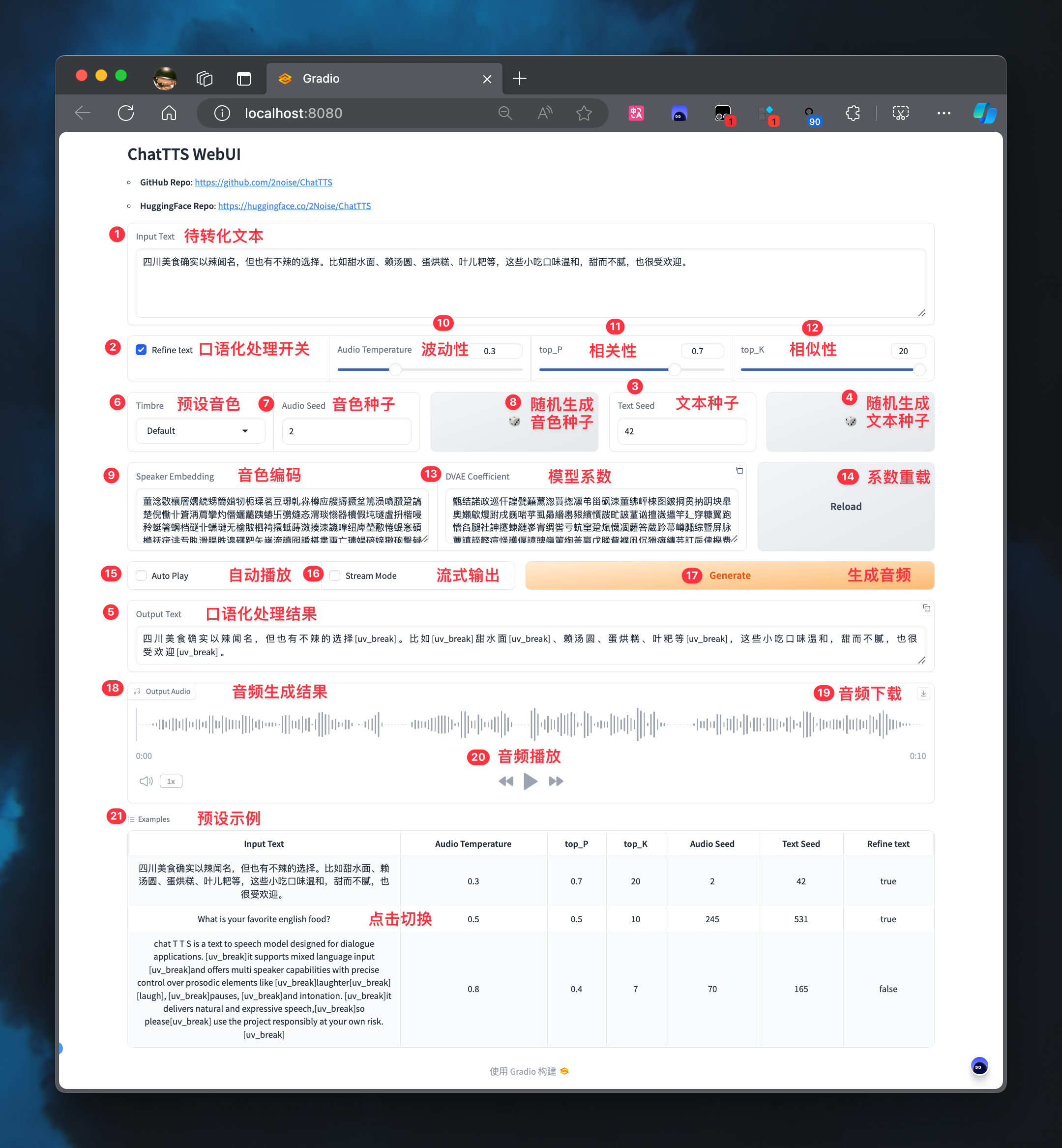
文本控制
- 1. Input Text : 需要转换的文本,支持中文和英文混杂
- 2. Refine text : 是否对文本进行口语化处理
- 3. Text Seed : 配置文本种子值,不同种子对应不同口语化风格
- 4. 🎲 : 随机产生文本种子值
- 5. Output Text : 口语化处理后生成的文本
音色控制
- 6. 音色:预设的音色种子值
- 7. 音频种子:配置音色种子值,不同种子对应不同音色
- 8. 🎲:随机生成音色种子值
- 9. 说话人嵌入:音色码,详见音色控制
情感控制
- 10. 温度:控制音频情感波动性,范围为0-1,数字越大,波动性越大
- 11. top_P:控制音频的情感相关性,范围为0.1-0.9,数字越大,相关性越高
- 12. top_K:控制音频的情感相似性,范围为1-20,数字越小,相似性越高
系数控制
- 13. DVAE系数:模型系数码
- 14. 重新加载:重新加载模型系数
播放控制
- 15. 自动播放:是否在生成音频后自动播放
- 16. 流式模式:是否启用流式输出
- 17. 生成:点击生成音频文件
- 18. 输出音频:音频生成结果
- 19. ↓:点击下载音频文件
- 20. ▶️:点击播放音频文件
示例控制
- 21. 示例:点击切换示例配置
音色控制
经过实际测试,指定音色种子值每次生成spk_emb和重复使用预生成好的spk_emb效果有较显著差异,建议优先使用.pt音色文件或者音色码(字符串表示形式)。
在ChatTTS_Speaker项目中对音色种子进行了初步打标和稳定性评估,可以通过示例来快速选择合适的音色。
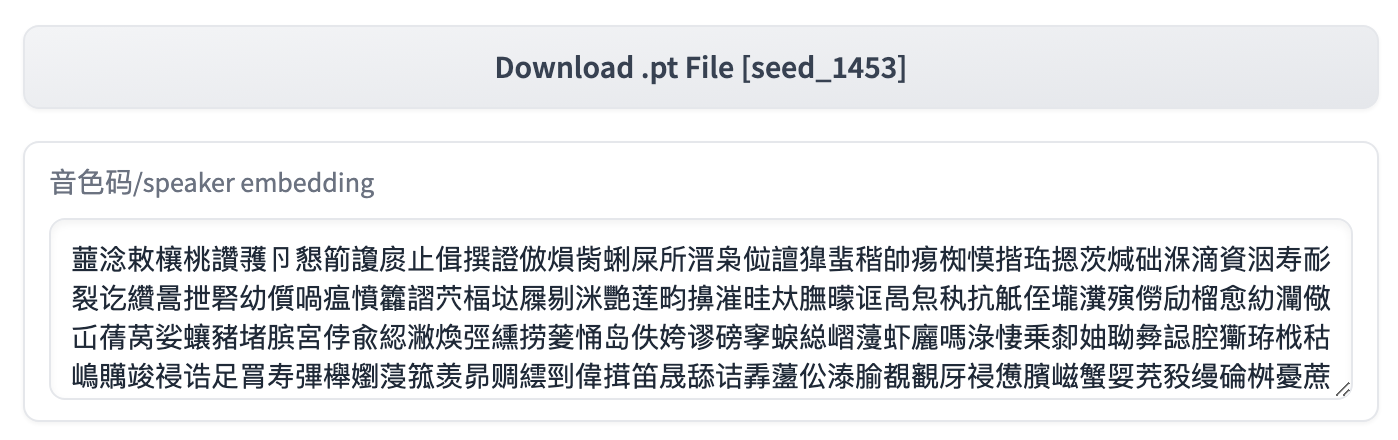
WebUI
在官方WebUI中使用时,可直接将音色码复制之后,替换9. 说话人嵌入中的值,实现音色控制。
Python
在Python脚本中使用时,参考issue#07中的压缩方案实现音色控制。
spk = torch.load("asset/seed_1332_restored_emb.pt", map_location=torch.device('cpu')).detach()
spk_emb_str = compress_and_encode(spk)
params_infer_code = ChatTTS.Chat.InferCodeParams(
spk_emb= spk_emb_str, # 添加采样的说话人
temperature=.0003, # 使用自定义温度
top_P=0.7, # top P解码
top_K=20, # top K解码
)
入门教程
中文教程
英文教程
| 视频 | 亮点 |
|---|---|
| Sam Witteveen | 英文版介绍 |
常见问题
经过近期的迭代,源仓库代码中的问题已经基本解决。如果遇到问题,建议先详细查看官方说明文档中文版,如果还有问题可以继续查看本文档。
模型无法下载
原版项目运行需要从HuggingFace下载对应的模型,如果不能顺畅科学上网,那么就无法完成这一步。作为替代方案,可以从modelscope上下载模型和配置,并配置本地路径。
[!重要] 魔塔上的模型库是由志愿者维护的,不保证所有模型都是最新的,如果有需要请自行验证。
- 在终端中安装modelscope依赖
pip install modelscope
- 修改webui.py中的代码
# 在开头导入依赖,并下载模型和配置
from modelscope import snapshot_download
model_dir = snapshot_download('zlj2546/ChatTTS')
# 第 118 行修改模型路径
ret = chat.load_models('custom', custom_path=model_dir)
IDE 中无法运行
在 IDE 中运行时,由于文件相对路径的问题,导致脚本无法顺利运行。
建议参照官方说明文档快速启动中的指令直接在终端中运行。
确保在执行以下命令时,处于项目根目录下。
1. WebUI 可视化界面
python examples/web/webui.py
2. 命令行交互
生成的音频将保存至
./output_audio_n.mp3
python examples/cmd/run.py "Your text 1." "Your text 2."
语气标签被读出
出现这个问题是因为官方代码处理中文标点符号时覆盖不全,例如 ?、… 等符号没有被处理,导致模型生成时出错。
可以手动删除类似的中文标点符号,或者修改 ChatTTS/utils/infer_utils.py 中的代码,在 103 行的 character_map 的字典中添加缺失的标点符号。
character_map = {
'…': '',
'—': ',',
'_': ',',
'?': ',',
}
GPU 无法使用
GPU 至少需要 4G 显存,否则将强制使用 CPU,相关问题可以参考 ChatTTS-ui 项目中的说明
报错速查
1、load_models() got an unexpected keyword argument 'source'
详见 常见问题 - 模型无法下载
2、cannot import name 'CommitOperationAdd' from 'huggingface_hub'
详见 常见问题 - 模型无法下载
3、 FileNotFoundError:[Erzno 2] No such file or directory: 'C:\\Users\\xxx\\.cache\\huggingface\\hub\\models--2Noise--ChatTTS\\snapshots\
详见 常见问题 - 模型无法下载
4、local variable 'Normalizer' referenced before assignment
需要根据 安装指南 完成环境配置后,再安装 pynini 和 WeTextProcessing 依赖
conda install -c conda-forge pynini=2.1.5 && pip install WeTextProcessing
5、download to Local path D:\pythonlproject\ChatTTS\ChatTTS failed.
在 IDE 中直接执行脚本,会因为文件路径问题报错,详见 常见问题 - IDE 中无法运行
6、ModuleNotFoundError : No module named'Cython'
未找到 Python 执行路径,Windows 设备需要按 教程 配置环境路径











