
 Github
Github 论文
论文Sora: 大规模视觉模型的背景、技术、局限性和机遇综述
🔍 查看我们的论文:"Sora: 大规模视觉模型的背景、技术、局限性和机遇综述"
🔍 查看我们最新的视频生成论文:"Mora: 通过多智能体框架实现通用视频生成"

)
📧 如果您发现任何错误或有任何建议,请通过电子邮件告诉我们:lis221@lehigh.edu
目录
关于
Sora是由OpenAI于2024年2月发布的一款文本到视频生成AI模型。该模型经过训练,可以根据文本指令生成现实或想象场景的视频,并在模拟物理世界方面显示出潜力。基于公开的技术报告和逆向工程,本文对该模型的背景、相关技术、应用、剩余挑战以及文本到视频AI模型的未来方向进行了全面综述。我们首先追溯了Sora的发展历程,并研究了用于构建这个"世界模拟器"的底层技术。然后,我们详细描述了Sora在从电影制作和教育到营销等多个行业中的应用和潜在影响。我们讨论了广泛部署Sora需要解决的主要挑战和局限性,如确保安全和无偏见的视频生成。最后,我们讨论了Sora和视频生成模型的未来发展,以及该领域的进展如何能够实现人机交互的新方式,提高视频生成的生产力和创造力。

更新
- 📄 [2024/02/28] 我们的论文已上传至arXiv,并被Hugging Face选为每日论文。
视觉领域生成式AI的历史
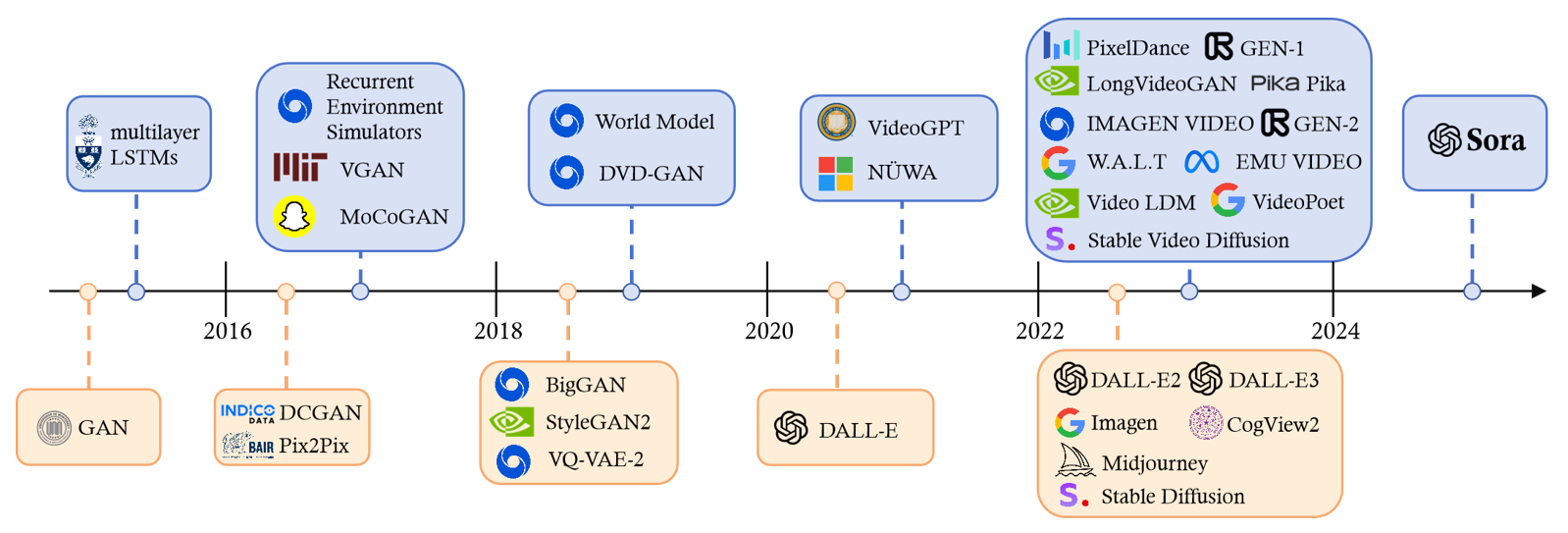
论文列表
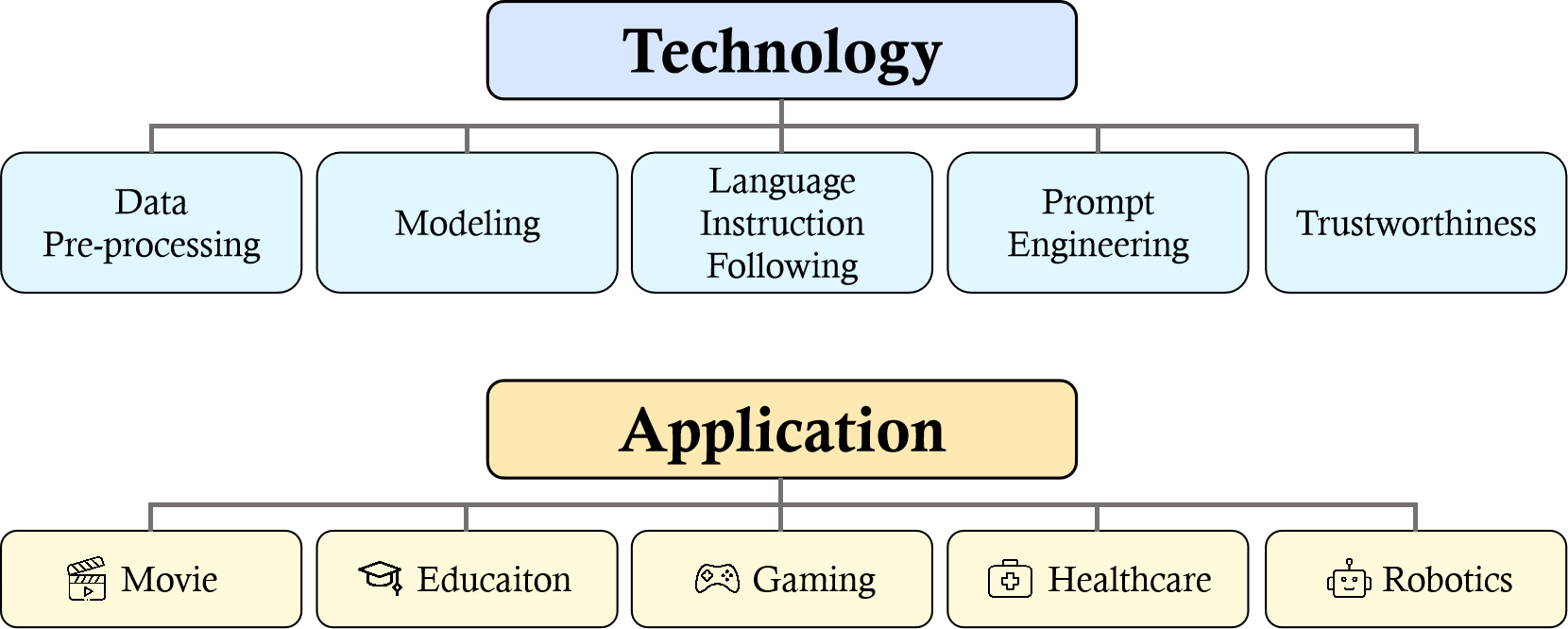
建模
- (JMLR'22) 用于高保真图像生成的级联扩散模型 [论文]
- (ICLR'22) 扩散模型快速采样的渐进式蒸馏 [论文][代码]
- Imagen Video:使用扩散模型的高清视频生成 [论文]
- (CVPR'23) 对齐你的潜在空间:使用潜在扩散模型的高分辨率视频合成 [论文]
- (ICCV'23) 使用 Transformer 的可扩展扩散模型 [论文]
- (CVPR'23) 所有都值得一词:扩散模型的 ViT 骨干网络 [论文][代码]
- (ICCV'23) 掩蔽扩散 Transformer 是强大的图像合成器 [论文][代码]
- (arXiv 2023.12) DiffiT:用于图像生成的扩散视觉 Transformer [论文][代码]
- (CVPR'24) GenTron:深入探索用于图像和视频生成的扩散 Transformer [论文]
- (arXiv 2023.09) LAVIE:使用级联潜在扩散模型的高质量视频生成 [论文][代码]
- (arXiv 2024.01) Latte:用于视频生成的潜在扩散 Transformer [论文][代码]
- (arXiv 2024.03) 扩展校正流 Transformer 以实现高分辨率图像合成 [论文]
语言指令遵循
- 通过更好的描述改进图像生成 [论文]
- (arXiv 2022.05) CoCa:对比描述器是图像-文本基础模型 [论文][代码]
- (arXiv 2022.12) VideoCoCa:从对比描述器零样本迁移的视频-文本建模 [论文]
- (CVPR'23) InstructPix2Pix:学习遵循图像编辑指令 [论文][代码]
- (NeurlPS'23) 视觉指令微调 [论文][代码]
- (ICML'23) mPLUG-2:跨文本、图像和视频的模块化多模态基础模型 [论文][代码]
- (arXiv 2022.05) GIT:用于视觉和语言的生成式图像到文本 Transformer [论文][代码]
- (CVPR'23) Vid2Seq:用于密集视频描述的大规模视觉语言模型预训练 [论文][代码]
提示工程
- (arXiv 2023.10) 释放大型语言模型中提示工程的潜力:全面综述 [论文]
- (arXiv 2023.04) 大型语言模型的提示集成增强 [论文][代码]
- (NeurIPS'23) 优化文本到图像生成的提示 [论文][代码]
- (CVPR'23) VoP:用于跨模态检索的文本-视频协同提示微调 [论文][代码]
- (ICCV'23) Tune-a-Video:图像扩散模型的一次性微调用于文本到视频生成 [论文][代码]
- (CVPR'22) 使用文本和图像提示的图像分割 [论文][代码]
- (ACM Computing Surveys'23) 预训练、提示和预测:自然语言处理中提示方法的系统综述 [论文][代码]
- (EMNLP'21) 参数高效提示微调的规模力量 [论文][代码]
可信度
- (arXiv 2024.02) 对多模态大型语言模型的越狱攻击 [论文][代码]
- (arXiv 2023.09) 大型基础模型幻觉现象调查 [论文][代码]
- (arXiv 2024.01) TrustLLM:大型语言模型的可信度 [论文][代码]
- (ICLR'24) AutoDAN:在对齐的大型语言模型上生成隐蔽的越狱提示 [论文][代码]
- (NeurIPS'23) DecodingTrust:对GPT模型可信度的全面评估 [论文][代码]
- 越狱成功:大型语言模型安全训练如何失效? [论文][代码]
- (arXiv 2023.10) HallusionBench:大型视觉-语言模型中交织的语言幻觉和视觉错觉的高级诊断套件 [论文][代码]
- (arXiv 2023.09) 大型语言模型中的偏见和公平性调查 [论文][代码]
- (arXiv 2023.02) 公平扩散:指导文本到图像生成模型实现公平性 [论文][代码]
应用
电影
- (arXiv 2023.06) MovieFactory:使用大型语言和图像生成模型从文本自动创建电影 [论文]
- (ACM Multimedia'23) MobileVidFactory:基于扩散的自动社交媒体视频生成,从文本为移动设备生成 [论文]
- (arXiv 2024.01) Vlogger:将你的梦想变成视频博客 [论文] [代码]
教育
- (arXiv 2023.09) CCEdit:通过扩散模型进行创意和可控的视频编辑 [论文] [代码]
- (TVCG'24) Make-Your-Video:使用文本和结构指导的定制视频生成 [论文] [代码]
- (ICLR'24) AnimateDiff:无需特定调整即可为个性化文本到图像扩散模型添加动画效果 [论文] [代码]
- (arXiv 2023.07) Animate-a-Story:基于检索增强的视频生成进行故事讲述 [论文] [代码]
- (CVPR'23) 基于潜在流扩散模型的条件图像到视频生成 [论文] [代码]
- (arXiv 2023.11) Animate Anyone:用于角色动画的一致且可控的图像到视频合成 [论文] [代码]
- (CVPR'22) Make It Move:基于文本描述的可控图像到视频生成 [论文] [代码]
游戏
- (AAAI'23) VIDM:视频隐式扩散模型 [论文] [代码]
- (CVPR'23) 投影潜在空间中的视频概率扩散模型 [论文] [代码]
- (CVPR'23) 基于物理驱动的扩散模型从视频合成撞击声音 [论文] [代码]
- (arXiv 2024.01) 基于扩散模型编码器的文本反转技术生成舞蹈音乐 [论文]
医疗保健
- (bioRxiv 2023.11) 用于细胞凋亡预测的视频扩散模型 [论文]
- (PRIME'23) DermoSegDiff:用于皮肤病变描绘的边界感知分割扩散模型 [论文] [代码]
- (ICCV'23) 用于基于骨骼的视频异常检测的多模态运动条件扩散模型 [论文] [代码]
- (arXiv 2023.01) MedSegDiff-V2:基于Transformer的扩散医学图像分割 [论文] [代码]
- (MICCAI'23) 用于医学图像分割的扩散Transformer U-Net [论文]
机器人学
- (IEEE RA-L'23) DALL-E-Bot:将网络规模扩散模型引入机器人技术 [论文]
- (CoRL'22) StructDiffusion:用于新物体语义重排的以物体为中心的扩散 [论文][代码]
- (arXiv 2022.05) 使用扩散进行灵活行为合成的规划 [论文][代码]
- (arXiv 2022.11) 条件生成建模是否足以进行决策? [论文][代码]
- (IROS'23) 运动规划扩散:使用扩散模型学习和规划机器人运动 [论文][代码]
- (ICLR'24) Seer:使用潜在扩散模型进行语言指导的视频预测 [论文][代码]
- (arXiv 2023.02) GenAug:通过生成增强将行为重定向到未见场景 [论文][代码]
- (arXiv 2022.12) CACTI:可扩展多任务多场景视觉模仿学习框架 [论文][代码]
引用
@misc{2024SoraReview,
title={Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models},
author={Yixin Liu and Kai Zhang and Yuan Li and Zhiling Yan and Chujie Gao and Ruoxi Chen and Zhengqing Yuan and Yue Huang and Hanchi Sun and Jianfeng Gao and Lifang He and Lichao Sun},
year={2024},
eprint={2402.17177},
archivePrefix={arXiv},
primaryClass={cs.CV}
}











