
 访问官网
访问官网 Github
Github Huggingface
Huggingfacewhisper-timestamped
多语言自动语音识别,带单词级时间戳和置信度。
描述
Whisper 是一套由OpenAI训练的多语言、稳健的语音识别模型,在多种语言中实现了先进的结果。Whisper模型被训练用于预测语音片段的近似时间戳(大多数时候精度为1秒),但最初不能预测单词时间戳。本仓库提出了一种在使用Whisper模型进行转录时预测单词时间戳并提供更准确的语音片段估计的实现。此外,还会为每个单词和每个片段分配置信度得分。
该方法基于动态时间规整(DTW)应用于交叉注意力权重,如Jong Wook Kim的这个笔记本所示。此笔记本有一些扩展:
- 起始/结束估计更准确。
- 为每个单词分配置信度得分。
- 如果可能(没有光束搜索...),无需额外的推理步骤即可预测单词时间戳(在每个语音片段解码后即时完成单词对齐)。
- 特别注意内存使用:
whisper-timestamped能够处理长文件,与常规使用Whisper模型相比仅需少量额外内存。
whisper-timestamped 是 openai-whisper Python包的扩展,旨在与任何版本的 openai-whisper 兼容。它提供更高效/准确的单词时间戳,以及以下附加功能:
- 在应用Whisper模型之前,可以运行语音活动检测(VAD),以避免由于训练数据中的错误而产生的幻听(例如,在纯静音上预测“谢谢你的观看!”)。 多种VAD方法可用:silero(默认),auditok,auditok:v3.1
- 当未指定语言时,会在输出中提供语言概率。
其他方法的备注
另一种相关的方法是使用预测字符的wav2vec模型来恢复单词级别时间戳,如 whisperX 中成功实现。但是,这些方法有几个缺点,而基于交叉注意力权重的方法如 whisper_timestamped 则没有这些缺点。这些缺点包括:
- 需要找到每种语言对应的一个wav2vec模型,这在Whisper的多语言能力下没法很好地扩展。
- 需要处理(至少)一个额外的神经网络(wav2vec模型),消耗内存。
- 需要在Whisper转录中规范字符以匹配wav2vec模型的字符集。这涉及尴尬的语言依赖转换,如将数字转换为单词(“2”->“two”),符号转换为单词(“%”->“percent”,“€”->“euro(s)”)...
- 在处理语言停顿(填词、犹豫、重复单词...)方面缺乏稳健性,这些通常由Whisper删除。
不需要额外模型的另一种方法是查看在每个(子)单词令牌被预测后由Whisper模型估计的时间戳令牌的概率。这在whisper.cpp和stable-ts中有所实现。然而,这种方法缺乏稳健性,因为Whisper模型并未被训练来在每个单词之后输出有意义的时间戳。Whisper模型倾向于在一定数量的单词被预测后(通常在句子的末尾)才预测时间戳,而在此条件外的时间戳概率分布可能不准确。实际上,这些方法在某些时间段内可能会产生完全不同步的结果(我们观察到了,特别是当有背景音乐时)。此外,Whisper模型的时间戳精度往往被四舍五入到1秒(如许多视频字幕),这对单词来说太不准确,达到更高的精度相当困难。
安装
首次安装
要求:
python3(版本高于或等于3.7,推荐至少3.9)ffmpeg(参见 whisper 仓库上的安装说明)
你可以通过pip安装whisper-timestamped:
pip3 install whisper-timestamped
或通过克隆此仓库并运行安装:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
python3 setup.py install
可能需要的附加包
如果你想绘制音频时间戳和单词之间的对齐图(如此部分所示),你还需要安装matplotlib:
pip3 install matplotlib
如果你想在运行Whisper模型之前使用VAD选项(语音活动检测),你还需要安装torchaudio和onnxruntime:
pip3 install onnxruntime torchaudio
如果你想使用Hugging Face Hub中的微调Whisper模型,你还需要安装transformers:
pip3 install transformers
Docker
可以构建一个大约9GB的docker镜像:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped:latest .
针对CPU的轻量安装
如果你没有GPU(或不想使用它),那么你不需要安装CUDA依赖项。你应该在安装whisper-timestamped 之前只安装一个轻量版本的torch,例如如下:
pip3 install \
torch==1.13.1+cpu \
torchaudio==0.13.1+cpu \
-f https://download.pytorch.org/whl/torch_stable.html
还可以构建一个大约3.5GB的特定docker镜像:
git clone https://github.com/linto-ai/whisper-timestamped
cd whisper-timestamped/
docker build -t whisper_timestamped_cpu:latest -f Dockerfile.cpu .
升级到最新版本
使用pip时,可以使用以下命令将库更新到最新版本:
pip3 install --upgrade --no-deps --force-reinstall git+https://github.com/linto-ai/whisper-timestamped
可以通过运行例如以下命令来使用特定版本的openai-whisper:
pip3 install openai-whisper==20230124
使用方法
Python
在Python中,可以使用函数 whisper_timestamped.transcribe(),这与 whisper.transcribe() 类似:
import whisper_timestamped
help(whisper_timestamped.transcribe)
与 whisper.transcribe() 的主要区别在于输出将包含所有片段的键 "words",并带有单词的开始和结束位置。请注意,单词将包含标点符号。参见以下示例示例输出。
此外,默认解码选项有所不同,以有利于高效解码(贪心解码代替光束搜索,并且没有温度采样回退)。要使用与 whisper 相同的默认设置,请使用 beam_size=5, best_of=5, temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0)。
还有一些与单词对齐相关的附加选项。
一般来讲,如果在Python脚本中导入 whisper_timestamped 代替 whisper 并使用 transcribe(model, ...) 代替 model.transcribe(...),应该可以完成任务:
import whisper_timestamped as whisper
audio = whisper.load_audio("AUDIO.wav")
model = whisper.load_model("tiny", device="cpu")
result = whisper.transcribe(model, audio, language="fr")
import json
print(json.dumps(result, indent = 2, ensure_ascii = False))
请注意,可以使用来自HuggingFace或本地文件夹的微调Whisper模型,通过使用 whisper_timestamped 的 load_model 方法。例如,如果你想使用 whisper-large-v2-nob,只需执行以下操作:
import whisper_timestamped as whisper
model = whisper.load_model("NbAiLab/whisper-large-v2-nob", device="cpu")
# ...
命令行
也可以在命令行中使用 whisper_timestamped,类似于 whisper。参见帮助:
whisper_timestamped --help
与 whisper CLI 的主要区别是:
-
输出文件:
- 输出的JSON包含单词时间戳和置信度得分。参见以下示例示例输出。
- 还有额外的CSV输出格式。
- 对于SRT、VTT、TSV格式,还会保存带有单词时间戳的附加文件。
-
一些默认选项不同:
- 默认情况下没有输出文件夹:使用
--output_dir .对应Whisper默认。 - 默认情况下没有详细信息:使用
--verbose True对应Whisper默认。 - 默认情况下禁用光束搜索解码和温度采样回退,以有利于高效解码。
要设置与Whisper默认相同,可以使用
--accurate(这等同于--beam_size 5 --temperature_increment_on_fallback 0.2 --best_of 5)。
- 默认情况下没有输出文件夹:使用
-
有一些额外的特定选项:
--compute_confidence启用/禁用为每个单词计算置信度得分。--punctuations_with_words决定标点符号是否应与前面的单词一起包含。
处理多文件时,可以使用 tiny 模型并将结果输出到当前文件夹,如Whisper默认所做的示例命令如下:
whisper_timestamped audio1.flac audio2.mp3 audio3.wav --model tiny --output_dir .
请注意,可以使用来自HuggingFace或本地文件夹的微调Whisper模型。例如,如果你想使用 whisper-large-v2-nob 模型,可以简单地执行以下操作:
whisper_timestamped --model NbAiLab/whisper-large-v2-nob <...>
单词对齐图
请注意,可以使用 whisper_timestamped.transcribe() Python函数的 plot_word_alignment 选项或 whisper_timestamped CLI的 --plot 选项查看每段的单词对齐。
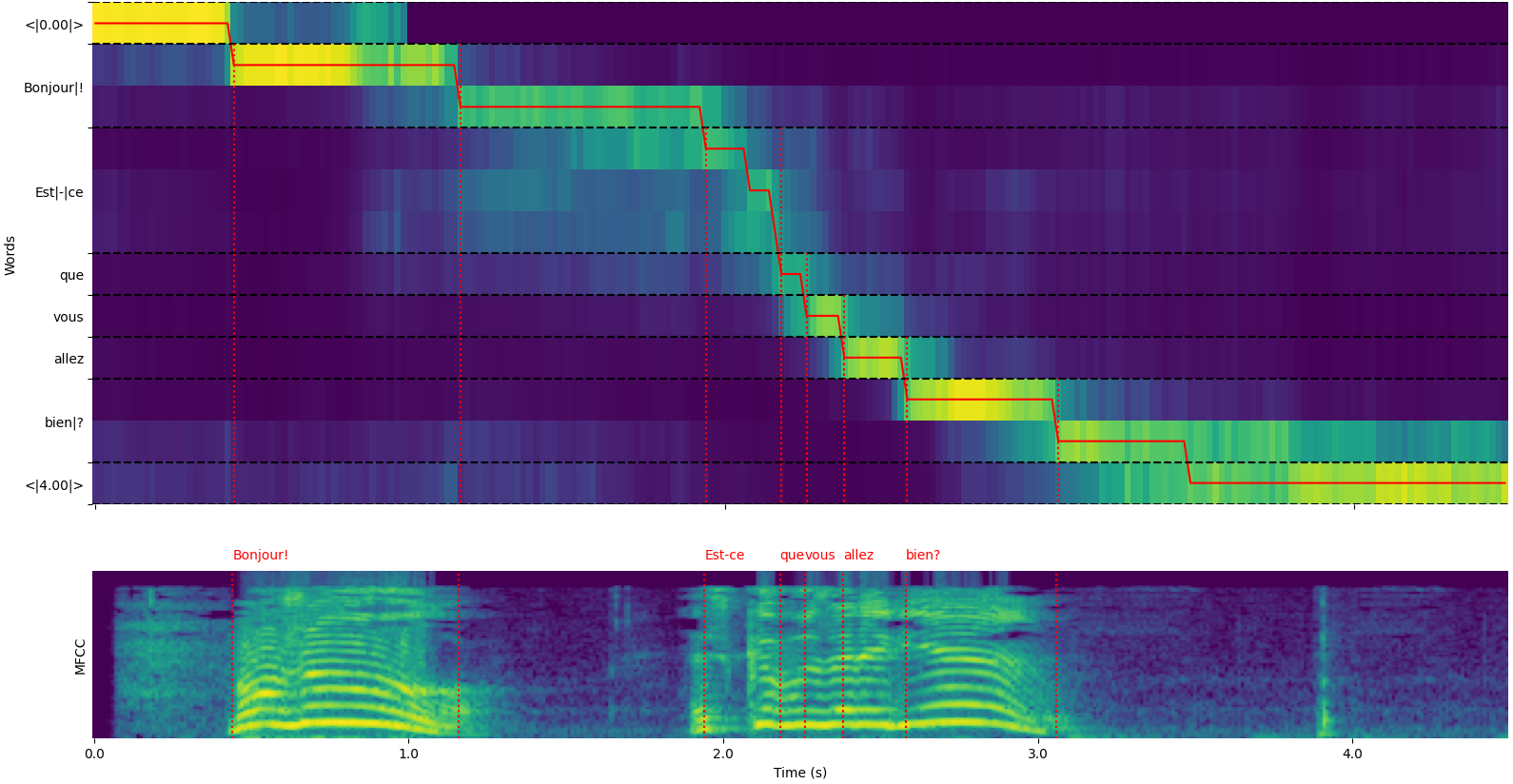
- 上方图表示用于动态时间规整对齐的交叉注意力权重变换。横轴表示时间,纵轴表示预测的令牌,起始和结束处有特殊的时间戳令牌,中间是(子)单词和标点符号。
- 下方图是输入信号的MFCC表示(基于Mel频率倒谱的功能,Whisper使用)。
- 垂直虚线红线表示发现的单词边界(标点符号“粘附”在前一个单词上)。
示例输出
whisper_timestamped.transcribe() 函数的输出是一个python字典,
可以使用CLI以JSON格式查看。
JSON的模式可以在 tests/json_schema.json 中查看。 这里是一个示例输出:
whisper_timestamped AUDIO_FILE.wav --model tiny --language fr
{
"text": " Bonjour! Est-ce que vous allez bien?",
"segments": [
{
"id": 0,
"seek": 0,
"start": 0.5,
"end": 1.2,
"text": " Bonjour!",
"tokens": [ 25431, 2298 ],
"temperature": 0.0,
"avg_logprob": -0.6674491882324218,
"compression_ratio": 0.8181818181818182,
"no_speech_prob": 0.10241222381591797,
"confidence": 0.51,
"words": [
{
"text": "Bonjour!",
"start": 0.5,
"end": 1.2,
"confidence": 0.51
}
]
},
{
"id": 1,
"seek": 200,
"start": 2.02,
"end": 4.48,
"text": " Est-ce que vous allez bien?",
"tokens": [ 50364, 4410, 12, 384, 631, 2630, 18146, 3610, 2506, 50464 ],
"temperature": 0.0,
"avg_logprob": -0.43492694334550336,
"compression_ratio": 0.7714285714285715,
"no_speech_prob": 0.06502953916788101,
"confidence": 0.595,
"words": [
{
"text": "Est-ce",
"start": 2.02,
"end": 3.78,
"confidence": 0.441
},
{
"text": "que",
"start": 3.78,
"end": 3.84,
"confidence": 0.948
},
{
"text": "vous",
"start": 3.84,
"end": 4.0,
"confidence": 0.935
},
{
"text": "allez",
"start": 4.0,
"end": 4.14,
"confidence": 0.347
},
{
"text": "bien?",
"start": 4.14,
"end": 4.48,
"confidence": 0.998
}
]
}
],
"language": "fr"
}
如果语言没有指定(例如没有在 CLI 中使用 --language fr 选项),您会发现多了一个包含语言概率的键:
{
...
"language": "fr",
"language_probs": {
"en": 0.027954353019595146,
"zh": 0.02743500843644142,
...
"fr": 0.9196318984031677,
...
"su": 3.0119704064190955e-08,
"yue": 2.2565967810805887e-05
}
}
可能改进结果的选项
以下是一些默认未启用但可能改进结果的选项。
精确的 Whisper 转录
如前所述,一些解码选项默认是禁用的,以提高效率。然而,这可能会影响转录质量。要使用最佳的选项提供最好的转录结果,请使用以下选项。
- 在 Python 中:
results = whisper_timestamped.transcribe(model, audio, beam_size=5, best_of=5, temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0), ...)
- 在命令行上:
whisper_timestamped --accurate ...
在发送到 Whisper 之前运行语音活动检测(VAD)
如果在没有语音的片段中,Whisper 模型可能会“幻觉”出一些文本。通过运行 VAD 并将语音片段粘合在一起再进行转录可以避免这种情况。这在 whisper-timestamped 中是可能的。
- 在 Python 中:
results = whisper_timestamped.transcribe(model, audio, vad=True, ...)
- 在命令行上:
whisper_timestamped --vad True ...
默认情况下,使用的 VAD 方法是 silero。但也有其他方法可用,例如 silero 的早期版本或 auditok。引入这些方法是因为最新版本的 silero VAD 在一些音频上可能有许多误报(在静音时检测到语音)。
- 在 Python 中:
results = whisper_timestamped.transcribe(model, audio, vad="silero:v3.1", ...)
results = whisper_timestamped.transcribe(model, audio, vad="auditok", ...)
- 在命令行上:
whisper_timestamped --vad silero:v3.1 ...
whisper_timestamped --vad auditok ...
为了查看 VAD 结果,可以使用 whisper_timestamped CLI 的 --plot 选项,或 whisper_timestamped.transcribe() Python 函数的 plot_word_alignment 选项。它将在输入音频信号上显示 VAD 结果如下(x 轴是时间(秒)):
| vad="silero:v4.0" | vad="silero:v3.1" | vad="auditok" |
|---|---|---|
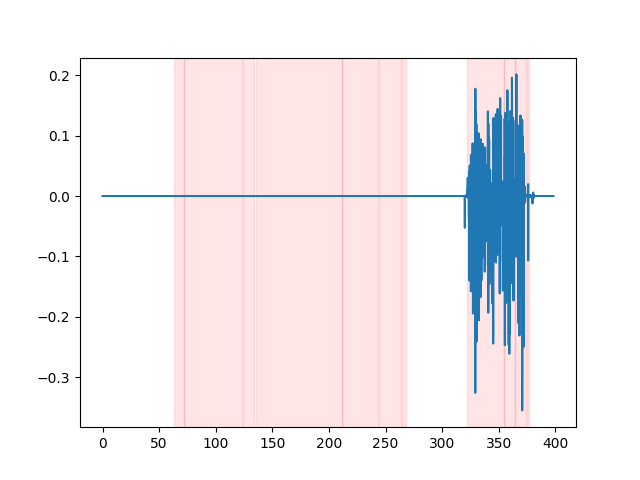 |  | 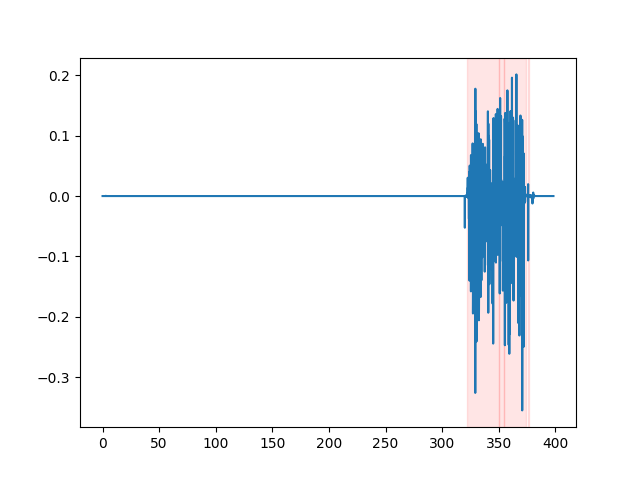 |
检测语言障碍
Whisper 模型倾向于去除语言障碍(填充词、犹豫、重复等)。如果不采取预防措施,未转录的语言障碍会影响后续单词的时间戳:单词开始的时间戳实际上是语言障碍开始的时间戳。whisper-timestamped 可以使用一些启发式方法来避免这种情况。
- 在 Python 中:
results = whisper_timestamped.transcribe(model, audio, detect_disfluencies=True, ...)
- 在命令行上:
whisper_timestamped --detect_disfluencies True ...
**重要提示:**请注意,当使用这些选项时,可能的语言障碍会作为特殊的“[*]”单词出现在转录中。
感谢
- whisper:Whisper 语音识别(MIT 许可证)。
- dtw-python:动态时间规整(GPL v3 许可证)。
引用
如果您在研究中使用此工具,请引用仓库:
@misc{lintoai2023whispertimestamped,
title={whisper-timestamped},
author={Louradour, J{\'e}r{\^o}me},
journal={GitHub repository},
year={2023},
publisher={GitHub},
howpublished = {\url{https://github.com/linto-ai/whisper-timestamped}}
}
以及 OpenAI Whisper 论文:
@article{radford2022robust,
title={Robust speech recognition via large-scale weak supervision},
author={Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya},
journal={arXiv preprint arXiv:2212.04356},
year={2022}
}
以及关于动态时间规整的这篇论文:
@article{JSSv031i07,
title={Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package},
author={Giorgino, Toni},
journal={Journal of Statistical Software},
year={2009},
volume={31},
number={7},
doi={10.18637/jss.v031.i07}
}











