
 Github
Github Huggingface
Huggingface 论文
论文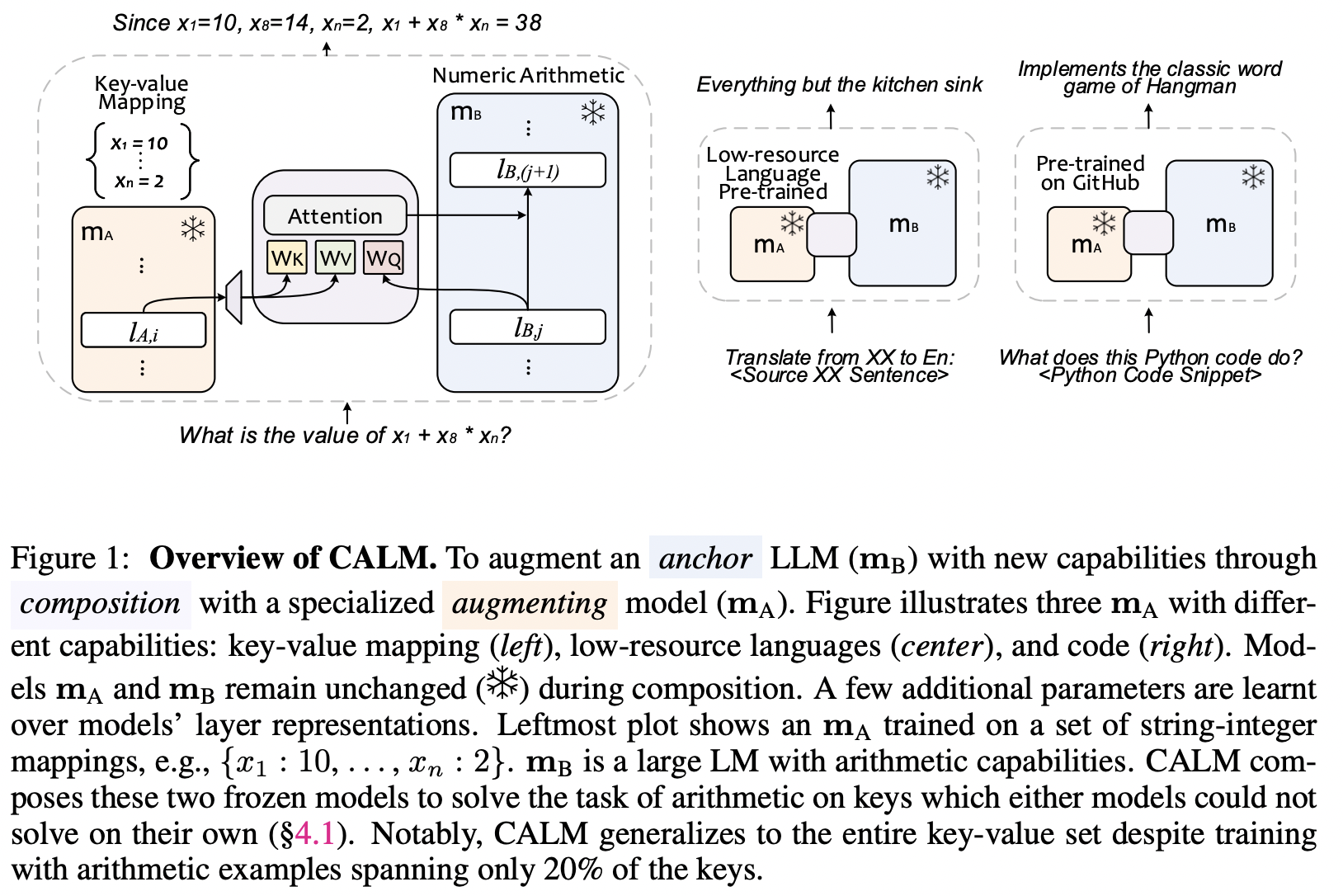
CALM - Pytorch
实现来自Google Deepmind发表的论文LLM增强LLM:通过组合扩展能力中的CALM
可支持任意数量的增强LLM
安装
$ pip install CALM-pytorch
致谢
- 感谢A16Z开源AI资助计划和🤗 Huggingface的慷慨赞助,以及我的其他赞助者,使我能够独立地开源当前的人工智能研究
使用方法
例如使用x-transformers
import torch
from x_transformers import TransformerWrapper, Decoder
augment_llm = TransformerWrapper(
num_tokens = 20000,
max_seq_len = 1024,
attn_layers = Decoder(
dim = 512,
depth = 12,
heads = 8
)
)
anchor_llm = TransformerWrapper(
num_tokens = 20000,
max_seq_len = 1024,
attn_layers = Decoder(
dim = 512,
depth = 2,
heads = 8
)
)
# 导入CALM包装器
from CALM_pytorch import CALM, AugmentParams
calm = CALM(
anchor_llm,
augment_llms = AugmentParams(
model = augment_llm,
connect_every_num_layers = 4
)
)
# 模拟输入
seq = torch.randint(0, 20000, (1, 1024))
mask = torch.ones((1, 1024)).bool()
prompt = torch.randint(0, 20000, (1, 256))
# 前向传播计算微调损失
loss = calm(
seq,
mask = mask,
prompt = prompt
)
loss.backward()
# 经过大量训练后,对组合模型进行提示
generated = calm.generate(
prompt = seq[:, :1],
seq_len = 1024
)
要使用基于🤗 Accelerate的方便的训练器类,只需导入FineTuner并按如下方式使用
trainer = FineTuner(
calm = calm,
dataset = dataset, # 返回一个包含calm输入kwargs的字典 - dict(seq: Tensor, mask: Tensor, prompt: Tensor)。它也可以返回一个元组,此时需要将data_kwargs设置为正确的有序kwarg名称值
batch_size = 16,
num_train_steps = 10000,
learning_rate = 3e-4,
weight_decay = 1e-2,
warmup_steps = 1000,
checkpoint_every = 1000
)
trainer()
# 每1000步会将交叉注意力参数的检查点保存到./checkpoints
要探索多个增强LLM,只需为augment_llm传入一个列表
例如:
calm = CALM(
anchor_llm = anchor_llm,
augment_llm = [AugmentParams(augment_llm1), AugmentParams(augment_llm2)] # 传入一个包含AugmentParams的列表,包装模型和特定于该变压器的其他超参数
)
如果你想探索锚模型和增强模型之间不同类型的连接,只需将连接作为整数对的元组元组传入,指定锚到增强层的编号。
calm = CALM(
anchor_llm = anchor_llm,
augment_llms = (
AugmentParams(
model = augment_llm1,
connections = (
(1, 12), # augment llm1的第1层被anchor llm的第12层关注
(2, 12),
(3, 12),
(4, 12),
),
),
AugmentParams(
model = augment_llm2,
connections = (
(6, 1), # augment llm2的第6层被anchor llm的第1层关注
(6, 2),
(12, 12),
)
)
)
)
带有2个专门的增强LLM和一个视觉变压器的CALM设置
import torch
# pip install vit-pytorch x-transformers
from vit_pytorch.vit import ViT, Attention
from x_transformers import TransformerWrapper, Encoder, Decoder
anchor_llm = TransformerWrapper(
num_tokens = 20000,
max_seq_len = 1024,
attn_layers = Decoder(
dim = 16,
dim_head = 2,
depth = 12,
heads = 8
)
)
augment_llm1 = TransformerWrapper(
num_tokens = 20000,
max_seq_len = 1024,
attn_layers = Encoder(
dim = 16,
dim_head = 2,
depth = 12,
heads = 8
)
)
augment_llm2 = TransformerWrapper(
num_tokens = 20000,
max_seq_len = 1024,
attn_layers = Encoder(
dim = 16,
dim_head = 2,
depth = 12,
heads = 8
)
)
vit = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 256,
depth = 6,
heads = 16,
mlp_dim = 2048
)
# calm
from CALM_pytorch import CALM, AugmentParams, FineTuner
calm = CALM(
anchor_llm = anchor_llm,
augment_llms = (
AugmentParams(
model = augment_llm1,
mask_kwarg = 'mask'
),
AugmentParams(
model = augment_llm2,
mask_kwarg = 'mask'
),
AugmentParams(
model = vit,
input_shape = (3, 256, 256),
hidden_position = 'input',
extract_blocks_fn = lambda vit: [m for m in vit.modules() if isinstance(m, Attention)]
)
),
attn_kwargs = dict(
linear_project_context = True,
pre_rmsnorm = True,
flash = True
)
)
seq = torch.randint(0, 20000, (1, 1024))
mask = torch.ones((1, 1024)).bool()
prompt = (
torch.randint(0, 20000, (1, 256)),
torch.randint(0, 20000, (1, 256)),
torch.randn(1, 3, 256, 256)
)
loss = calm(
seq,
mask = mask,
prompt = prompt
)
loss.backward()
## 待办事项
- [x] 找出如何正确掩蔽增强语言模型的标记
- [x] 使用虚拟输入自动推导模型维度
- [x] 处理微调训练逻辑
- [x] 展示2个或更多注意力网络之间自定义连接的示例
- [x] 如果直接传入锚定和增强变换器块模块(无需提取函数),通过两个网络运行虚拟输入,并使用钩子正确排序它们
- [x] 修复x-transformers的示例,因为在x-transformers中,深度实际上是深度的2倍,从注意力和前馈网络之后获取隐藏状态
- [x] 在精细指定隐藏位置时,如果传入的变换器块本身未排序,请确保重新排序
- [x] 扩展到多个增强语言模型列表
- [x] 完整的连接自定义
- [x] 每个增强语言模型的自定义增强层数
- [x] 使简单的视觉变换器工作
- [x] 重构,使提取函数、掩码关键字参数和其他相关超参数分组在{[augment_llm_name]: {augment_llm_related_hparams}}的字典下 - 使用数据类
- [x] 展示示例
- [x] 处理采样时缓存增强隐藏状态。暂时忽略锚定KV缓存
- [x] 用于推理时不释放记录器保存的输出的逻辑
- [x] 管理交叉注意力块状态,以从记录器中弹出保存的输出
- [x] 将增强前向传播移到一个共享方法中,并为锚定制定采样方法
- [ ] 能够仅使用模块名称进行连接
- [ ] 展示一个示例,使用<a href="https://github.com/lucidrains/audiolm-pytorch">hubert或wav2vec</a>包装器赋予语言模型听力能力
- [ ] 处理一个包装器或函数,该函数接受序列和提示长度,并自动推导CALM的输入
- [ ] 添加一个选项,用于自注意力路径,其中记忆标记关注所有增强语言模型的隐藏状态,类似于<a href="https://github.com/lucidrains/zorro-pytorch">Zorro</a>中的做法
## 引用
```bibtex
@inproceedings{Bansal2024LLMAL,
title = {LLM Augmented LLMs: Expanding Capabilities through Composition},
author = {Rachit Bansal and Bidisha Samanta and Siddharth Dalmia and Nitish Gupta and Shikhar Vashishth and Sriram Ganapathy and Abhishek Bapna and Prateek Jain and Partha Pratim Talukdar},
year = {2024},
url = {https://api.semanticscholar.org/CorpusID:266755751}
}











