
 访问官网
访问官网 Github
Github 论文
论文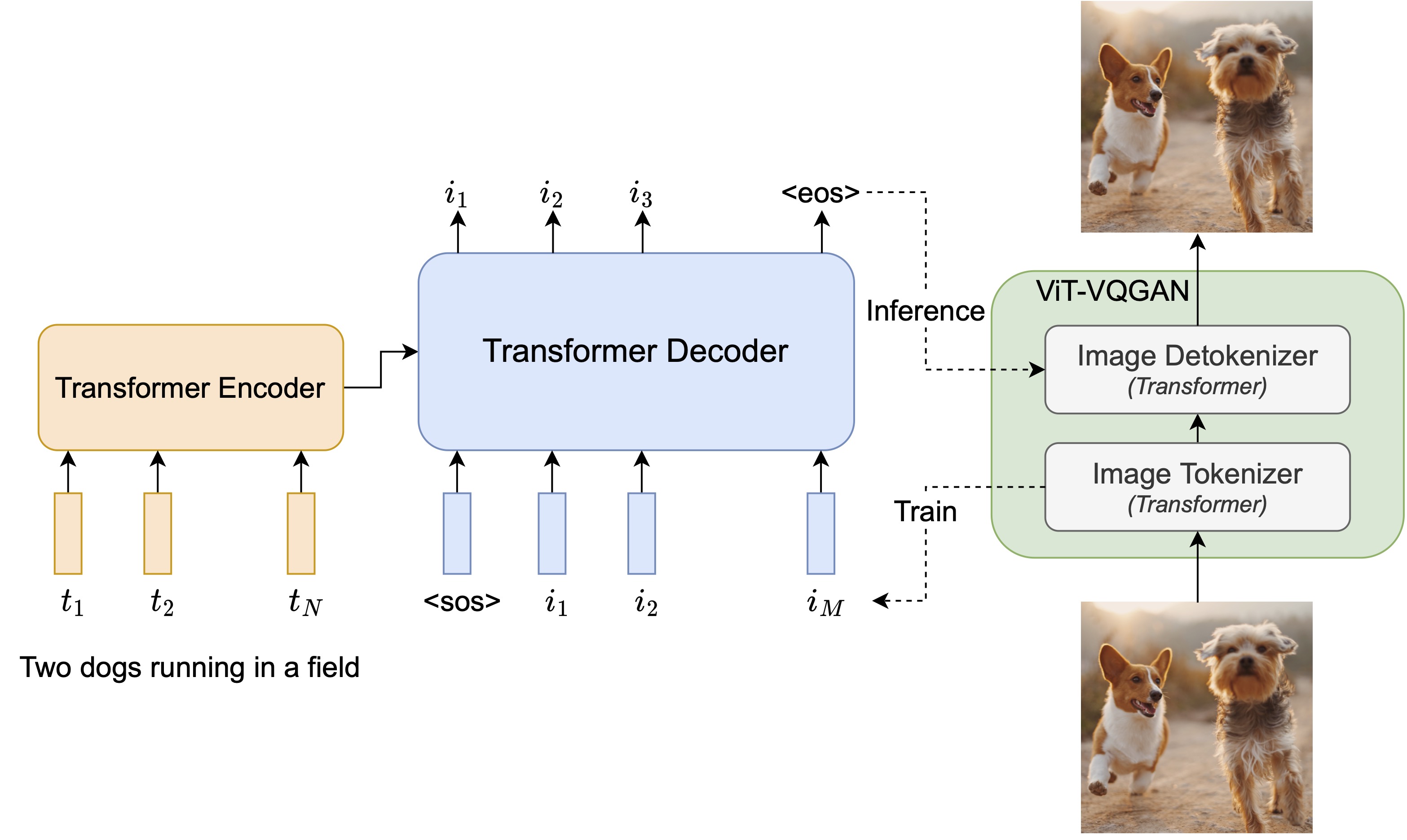
Parti - Pytorch
Parti是Google纯注意力机制的文本到图像神经网络的Pytorch实现。项目页面
本仓库还包含ViT VQGan VAE的可用训练代码。它还包含一些来自视觉transformer文献的额外修改,以实现更快的训练。
如果您有兴趣与LAION社区一起参与复制工作,请加入

安装
$ pip install parti-pytorch
使用方法
首先,您需要训练您的Transformer VQ-GAN VAE
from parti_pytorch import VitVQGanVAE, VQGanVAETrainer
vit_vae = VitVQGanVAE(
dim = 256, # 维度
image_size = 256, # 目标图像大小
patch_size = 16, # 图像中相互关注的patch大小
num_layers = 3 # 层数
).cuda()
trainer = VQGanVAETrainer(
vit_vae,
folder = '/path/to/your/images',
num_train_steps = 100000,
lr = 3e-4,
batch_size = 4,
grad_accum_every = 8,
amp = True
)
trainer.train()
然后
import torch
from parti_pytorch import Parti, VitVQGanVAE
# 首先实例化您的ViT VQGan VAE
# 一个由transformer组成的VQGan VAE
vit_vae = VitVQGanVAE(
dim = 256, # 维度
image_size = 256, # 目标图像大小
patch_size = 16, # 图像中相互关注的patch大小
num_layers = 3 # 层数
).cuda()
vit_vae.load_state_dict(torch.load(f'/path/to/vae.pt')) # 您需要加载指数移动平均的VAE
# 然后将ViT VqGan VAE插入到您的Parti中,如下所示
parti = Parti(
vae = vit_vae, # vit vqgan vae
dim = 512, # 模型维度
depth = 8, # 深度
dim_head = 64, # 注意力头维度
heads = 8, # 注意力头数
dropout = 0., # dropout
cond_drop_prob = 0.25, # 条件dropout,用于无分类器引导
ff_mult = 4, # 前馈扩展因子
t5_name = 't5-large', # 您的T5名称
)
# 准备您的训练文本和图像
texts = [
'一个孩子在发现半吃的苹果里有虫子时尖叫',
'蜥蜴在沙漠中用两只脚奔跑',
'醒来后看到迷幻景观',
'浅水中闪闪发光的贝壳'
]
images = torch.randn(4, 3, 256, 256).cuda()
# 将其输入到您的parti实例中,将return_loss设置为True
loss = parti(
texts = texts,
images = images,
return_loss = True
)
loss.backward()
# 在大量数据上长时间进行这个操作
# 然后...
images = parti.generate(texts = [
'远处跃出水面的鲸鱼',
'年轻女孩吹灭生日蛋糕上的蜡烛',
'蓝色和绿色火花的烟花'
], cond_scale = 3., return_pil_images = True) # 无分类器引导的条件缩放
# List[PILImages] (256 x 256 RGB)
实际上,在扩大规模时,您会想要预先将文本编码为token及其各自的掩码
from parti_pytorch.t5 import t5_encode_text
images = torch.randn(4, 3, 256, 256).cuda()
text_token_embeds, text_mask = t5_encode_text([
'一个孩子在发现半吃的苹果里有虫子时尖叫',
'蜥蜴在沙漠中用两只脚奔跑',
'醒来后看到迷幻景观',
'浅水中闪闪发光的贝壳'
], name = 't5-large', output_device = images.device)
# 存储在某处,然后用数据加载器加载
loss = parti(
text_token_embeds = text_token_embeds,
text_mask = text_mask,
images = images,
return_loss = True
)
loss.backward()
致谢
-
感谢StabilityAI的赞助,以及我的其他赞助商,使我能够独立地开源人工智能。
-
感谢🤗 Huggingface提供transformers库和便利的T5语言模型文本编码方法。
待办事项
- 为parti自回归transformer添加2d相对位置偏置
- 如果有效,引用vit vqgan中采用的所有来自视觉transformer文献的技术
- 获取可用的vit vqgan-vae训练器代码,因为需要训练判别器
- 在判别器中使用crossformer嵌入层作为初始卷积
- 使用指定的t5预编码文本
- parti的训练代码
- 推理缓存
- 使用Coca进行自动过滤 https://github.com/lucidrains/CoCa-pytorch
- 引入论文中提到的超分辨率卷积网络,包括训练代码
- 以卷积样式模式初始化2d相对位置偏置
- 考虑在vit-vqgan末尾添加一个小型类nerf MLP,类似于 https://arxiv.org/abs/2107.04589
引用
@inproceedings{Yu2022Pathways
title = {Pathways Autoregressive Text-to-Image Model},
author = {Jiahui Yu*, Yuanzhong Xu†, Jing Yu Koh†, Thang Luong†, Gunjan Baid†, Zirui Wang†, Vijay Vasudevan†, Alexander Ku†, Yinfei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge†, Yonghui Wu*},
year = {2022}
}
@article{Shleifer2021NormFormerIT,
title = {NormFormer:利用额外归一化改进的Transformer预训练},
author = {Sam Shleifer 和 Jason Weston 和 Myle Ott},
journal = {ArXiv},
year = {2021},
volume = {abs/2110.09456}
}
@article{Sankararaman2022BayesFormerTW,
title = {BayesFormer:具有不确定性估计的Transformer},
author = {Karthik Abinav Sankararaman 和 Sinong Wang 和 Han Fang},
journal = {ArXiv},
year = {2022},
volume = {abs/2206.00826}
}
@article{Lee2021VisionTF,
title = {小规模数据集的视觉Transformer},
author = {Seung Hoon Lee 和 Seunghyun Lee 和 Byung Cheol Song},
journal = {ArXiv},
year = {2021},
volume = {abs/2112.13492}
}
@article{Chu2021DoWR,
title = {视觉Transformer真的需要显式位置编码吗?},
author = {Xiangxiang Chu 和 Bo Zhang 和 Zhi Tian 和 Xiaolin Wei 和 Huaxia Xia},
journal = {ArXiv},
year = {2021},
volume = {abs/2102.10882}
}
@article{So2021PrimerSF,
title = {Primer:搜索高效的语言建模Transformer},
author = {David R. So 和 Wojciech Ma'nke 和 Hanxiao Liu 和 Zihang Dai 和 Noam M. Shazeer 和 Quoc V. Le},
journal = {ArXiv},
year = {2021},
volume = {abs/2109.08668}
}
@inproceedings{Wang2021CrossFormerAV,
title = {CrossFormer:基于跨尺度注意力的多功能视觉Transformer},
author = {Wenxiao Wang 和 Lulian Yao 和 Long Chen 和 Binbin Lin 和 Deng Cai 和 Xiaofei He 和 Wei Liu},
year = {2021}
}
@misc{mentzer2023finite,
title = {有限标量量化:简化的VQ-VAE},
author = {Fabian Mentzer 和 David Minnen 和 Eirikur Agustsson 和 Michael Tschannen},
year = {2023},
eprint = {2309.15505},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
@misc{yu2023language,
title = {语言模型胜过扩散模型 -- 分词器是视觉生成的关键},
author = {Lijun Yu 和 José Lezama 和 Nitesh B. Gundavarapu 和 Luca Versari 和 Kihyuk Sohn 和 David Minnen 和 Yong Cheng 和 Agrim Gupta 和 Xiuye Gu 和 Alexander G. Hauptmann 和 Boqing Gong 和 Ming-Hsuan Yang 和 Irfan Essa 和 David A. Ross 和 Lu Jiang},
year = {2023},
eprint = {2310.05737},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}











