
 访问官网
访问官网 Github
Github Huggingface
Huggingface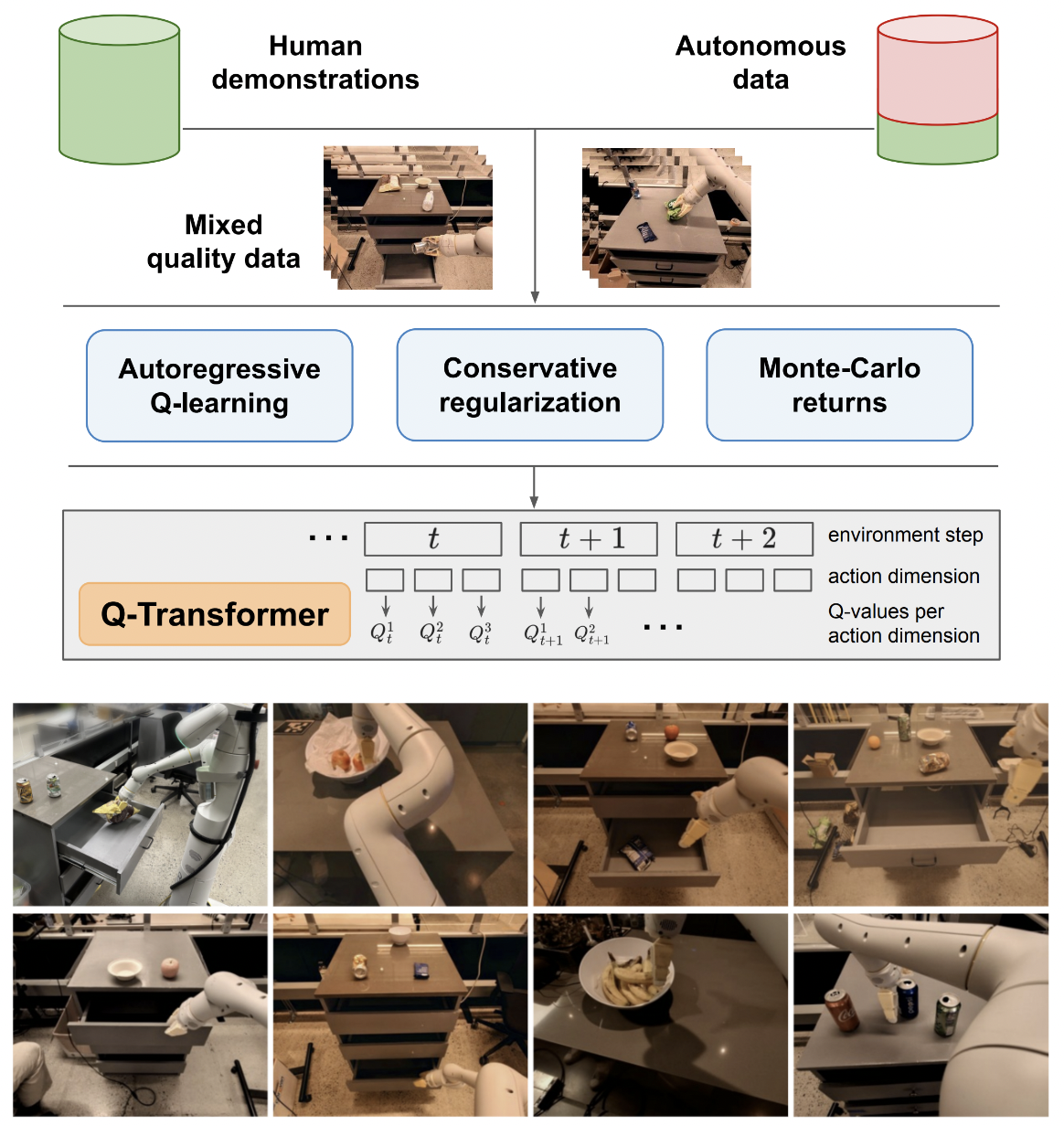
Q-transformer
Google Deepmind 提出的 Q-Transformer 实现,一种可扩展的离线强化学习方法,通过自回归 Q 函数实现。
为了最终与提出的多动作自回归 Q 学习进行比较,我将保留单一动作 Q 学习的逻辑。这也可以作为我自己和公众的教育资料。
安装
$ pip install q-transformer
使用方法
import torch
from q_transformer import (
QRoboticTransformer,
QLearner,
Agent,
ReplayMemoryDataset
)
# 注意力模型
model = QRoboticTransformer(
vit = dict(
num_classes = 1000,
dim_conv_stem = 64,
dim = 64,
dim_head = 64,
depth = (2, 2, 5, 2),
window_size = 7,
mbconv_expansion_rate = 4,
mbconv_shrinkage_rate = 0.25,
dropout = 0.1
),
num_actions = 8,
action_bins = 256,
depth = 1,
heads = 8,
dim_head = 64,
cond_drop_prob = 0.2,
dueling = True
)
# 你需要通过重写 BaseEnvironment 来提供自己的环境
from q_transformer.mocks import MockEnvironment
env = MockEnvironment(
state_shape = (3, 6, 224, 224),
text_embed_shape = (768,)
)
# env.init() 应返回指令和初始状态:Tuple[str, Tensor[*state_shape]]
# env(actions) 应返回奖励、下一个状态和完成标志:Tuple[Tensor[()], Tensor[*state_shape], Tensor[()]]
# agent 是一个类,允许 q-model 与环境交互,生成用于学习的回放记忆数据集
agent = Agent(
model,
environment = env,
num_episodes = 1000,
max_num_steps_per_episode = 100,
)
agent()
# 在回放记忆数据集上对模型进行 Q 学习
q_learner = QLearner(
model,
dataset = ReplayMemoryDataset(),
num_train_steps = 10000,
learning_rate = 3e-4,
batch_size = 4,
grad_accum_every = 16,
)
q_learner()
# 经过大量学习后
# 你的机器人应该能更好地选择最优动作
video = torch.randn(2, 3, 6, 224, 224)
instructions = [
'把桌子上的那个苹果拿给我',
'请把黄油递过来'
]
actions = model.get_optimal_actions(video, instructions)
致谢
- 感谢 StabilityAI、A16Z 开源 AI 资助计划和 🤗 Huggingface 的慷慨赞助,以及我的其他赞助商,让我能够独立地开源当前的人工智能研究。
待办事项
-
首先朝着单一动作支持的方向努力
-
提供无批量归一化的maxvit变体,如SOTA天气模型metnet3中所做
-
添加可选的深度对偶架构
-
添加n步Q学习
-
构建保守正则化
-
实现论文中的主要提议(在最后一个动作之前使用自回归离散动作,仅在最后给予奖励)
-
改进解码器头部变体,不在帧和学习的标记阶段连接先前的动作。换言之,使用经典的编码器-解码器
- 允许对精细帧/学习的标记进行交叉注意力
-
使用轴向旋转嵌入和sigmoid门控(用于不关注任何内容)重做maxvit。通过此更改为maxvit启用快速注意力
-
构建一个简单的数据集创建器类,接收环境和模型,返回可被
ReplayDataset接受的文件夹- 完成基本环境循环
- 将记忆存储到指定文件夹中的内存映射文件
- 创建接收文件夹的
ReplayDataset- 1个时间步选项
- n个时间步
-
正确处理多个指令
-
展示一个简单的端到端示例,与其他所有仓库风格相同
-
处理无指令情况,利用CFG库中的空调节器
-
缓存动作解码的kv
-
对于探索,允许精细随机化一部分动作,而不是一次性随机化所有动作
- 还允许基于Gumbel分布的动作采样,并逐步降低Gumbel噪声
-
咨询一些强化学习专家,确定是否有解决妄想偏差的新进展
-
探索是否可以使用随机化的动作顺序进行训练 - 顺序可以作为条件在注意力层之前连接或相加
- 提供一个改进变体,其中第一个动作标记建议动作顺序。所有动作并非平等,有些可能需要更多地关注过去的动作
-
实现简单的束搜索函数以获得最优动作
-
改进对过去动作和时间步状态的交叉注意力,采用transformer-xl方式(带结构化记忆丢弃)
-
探索本文的主要思想是否适用于语言模型
引用
@inproceedings{qtransformer,
title = {Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions},
authors = {Yevgen Chebotar and Quan Vuong and Alex Irpan and Karol Hausman and Fei Xia and Yao Lu and Aviral Kumar and Tianhe Yu and Alexander Herzog and Karl Pertsch and Keerthana Gopalakrishnan and Julian Ibarz and Ofir Nachum and Sumedh Sontakke and Grecia Salazar and Huong T Tran and Jodilyn Peralta and Clayton Tan and Deeksha Manjunath and Jaspiar Singht and Brianna Zitkovich and Tomas Jackson and Kanishka Rao and Chelsea Finn and Sergey Levine},
booktitle = {7th Annual Conference on Robot Learning},
year = {2023}
}
@inproceedings{dao2022flashattention,
title = {闪光注意力:具有IO感知的快速且内存高效的精确注意力机制},
author = {陶, 崔 和 傅, 丹尼尔 Y. 和 尔蒙, 斯特凡诺 和 鲁德拉, 阿特里 和 雷, 克里斯托弗},
booktitle = {神经信息处理系统进展},
year = {2022}
}











