
 Github
Github Huggingface
Huggingface 论文
论文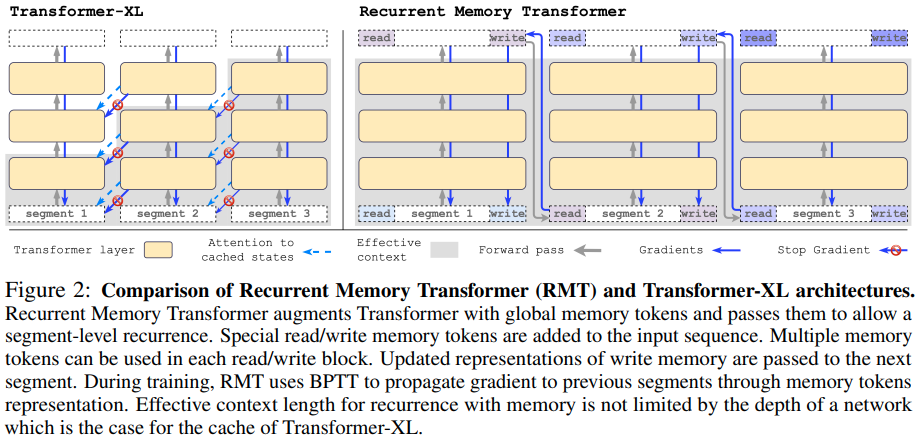
循环记忆 Transformer - Pytorch 实现
在 Pytorch 中实现循环记忆 Transformer (openreview)。他们最近发表了一篇简短的后续论文,证明它至少能够复制 100 万个 token 的信息。
我坚信 RMT 会比 AdA(仅是一个 Transformer-XL)成为更强大的强化学习代理 - 更新:循环记忆决策 Transformer
致谢
- 感谢 Stability 和 🤗 Huggingface 慷慨赞助,使我能够致力于开源前沿人工智能研究
安装
$ pip install recurrent-memory-transformer-pytorch
使用方法
import torch
from recurrent_memory_transformer_pytorch import RecurrentMemoryTransformer
model = RecurrentMemoryTransformer(
num_tokens = 20000, # token 数量
num_memory_tokens = 128, # 记忆 token 数量,这将决定传递给未来的信息瓶颈
dim = 512, # 模型维度
depth = 6, # transformer 深度
causal = True, # 是否自回归
dim_head = 64, # 每个头的维度
heads = 8, # 头数
seq_len = 1024, # 段的序列长度
use_flash_attn = True # 是否使用快速注意力
)
x = torch.randint(0, 256, (1, 1024))
logits1, mem1, _ = model(x) # (1, 1024, 20000), (1, 128, 512), None
logits2, mem2, _ = model(x, mem1) # (1, 1024, 20000), (1, 128, 512), None
logits3, mem3, _ = model(x, mem2) # (1, 1024, 20000), (1, 128, 512), None
# 依此类推 ...
使用 XL 记忆
import torch
from recurrent_memory_transformer_pytorch import RecurrentMemoryTransformer
model = RecurrentMemoryTransformer(
num_tokens = 20000,
num_memory_tokens = 128,
dim = 512,
depth = 6,
causal = True,
dim_head = 64,
heads = 8,
seq_len = 1024,
use_flash_attn = True,
use_xl_memories = True, # 将此设置为 True
xl_mem_len = 512 # 可以比 seq_len 短 - 我认为只需要一点过去的信息就能防止大部分 RMT 记忆记住紧邻的前文
)
x = torch.randint(0, 256, (1, 1024))
logits1, mem1, xl_mem1 = model(x) # (1, 1024, 20000), (1, 128, 512), [(2, 1, 512, 512)]
logits2, mem2, xl_mem2 = model(x, mem1, xl_memories = xl_mem1) # (1, 1024, 20000), (1, 128, 512), [(2, 1, 512, 512)]
logits3, mem3, xl_mem3 = model(x, mem2, xl_memories = xl_mem2) # (1, 1024, 20000), (1, 128, 512), [(2, 1, 512, 512)]
# 依此类推 ...
在极长序列上训练
import torch
from recurrent_memory_transformer_pytorch import (
RecurrentMemoryTransformer,
RecurrentMemoryTransformerWrapper
)
model = RecurrentMemoryTransformer(
num_tokens = 256,
num_memory_tokens = 128,
dim = 512,
depth = 6,
seq_len = 1024,
use_flash_attn = True,
causal = True
)
model = RecurrentMemoryTransformerWrapper(model).cuda()
seq = torch.randint(0, 256, (4, 65536)).cuda() # 极长序列,实际上,他们从 1 个段开始到大约 7-8 个段进行课程学习
loss = model(seq, memory_replay_backprop = True) # 来自 memformer 论文的内存高效训练
待办事项
-
将记忆回放反向传播移至 torch.function,测试双向,然后在实际问题上测试
-
使旋转嵌入与 xl 记忆正常工作
-
添加 xl 记忆,分离
-
提供关闭旋转嵌入、绝对位置嵌入的方法,并添加 token 移位
-
将因果掩蔽记忆设为可选
-
添加来自 memformer 论文的记忆回放反向传播技术
-
相对位置编码
替代方案
引用
@inproceedings{bulatov2022recurrent,
title = {Recurrent Memory Transformer},
author = {Aydar Bulatov and Yuri Kuratov and Mikhail Burtsev},
booktitle = {Advances in Neural Information Processing Systems},
editor = {Alice H. Oh and Alekh Agarwal and Danielle Belgrave and Kyunghyun Cho},
year = {2022},
url = {https://openreview.net/forum?id=Uynr3iPhksa}
}
@misc{bulatov2023scaling,
title = {Scaling Transformer to 1M tokens and beyond with RMT},
author = {Aydar Bulatov and Yuri Kuratov and Mikhail S. Burtsev},
year = {2023},
eprint = {2304.11062},
archivePrefix = {arXiv},
primaryClass = {cs.CL}
}
@inproceedings{dao2022flashattention,
title = {Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author = {Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{\'e}, Christopher},
booktitle = {Advances in Neural Information Processing Systems},
year = {2022}
}
@misc{shazeer2020glu,
title = {GLU Variants Improve Transformer},
author = {Noam Shazeer},
year = {2020},
url = {https://arxiv.org/abs/2002.05202}
}
@misc{su2021roformer,
title = {RoFormer: Enhanced Transformer with Rotary Position Embedding},
author = {Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu},
year = {2021},
eprint = {2104.09864},
archivePrefix = {arXiv},
primaryClass = {cs.CL}
}
@inproceedings{Wu2020MemformerAM,
title = {Memformer: 一种用于序列建模的记忆增强型Transformer},
author = {吴清阳 and 兰振中 and 钱堃 and 顾静 and Alborz Geramifard and 俞舟},
booktitle = {AACL/IJCNLP},
year = {2020}
}
@software{peng_bo_2021_5196578,
author = {彭博},
title = {BlinkDL/RWKV-LM: 0.01},
month = {8月},
year = {2021},
publisher = {Zenodo},
version = {0.01},
doi = {10.5281/zenodo.5196578},
url = {https://doi.org/10.5281/zenodo.5196578}
}
@misc{ding2021cogview,
title = {CogView: 通过Transformer掌握文本到图像的生成},
author = {丁明 and 杨卓艺 and 洪文毅 and 郑文迪 and 周畅 and 尹达 and 林俊阳 and 邹旭 and 邵周 and 杨红霞 and 唐杰},
year = {2021},
eprint = {2105.13290},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
@software{Dayma_DALLE_Mini_2021,
author = {Boris Dayma and Suraj Patil and Pedro Cuenca and Khalid Saifullah and Tanishq Abraham and Phúc Lê Khắc and Luke Melas and Ritobrata Ghosh},
doi = {10.5281/zenodo.5146400},
license = {Apache-2.0},
month = {7月},
title = {{DALL·E Mini}},
url = {https://github.com/borisdayma/dalle-mini},
version = {v0.1-alpha},
year = {2021}}
@inproceedings{anonymous2022normformer,
title = {NormFormer: 通过额外归一化改进的Transformer预训练},
author = {匿名},
booktitle = {提交至第十届国际学习表示会议},
year = {2022},
url = {https://openreview.net/forum?id=GMYWzWztDx5},
note = {审核中}
}
@misc{ding2021erniedoc,
title = {ERNIE-Doc: 一种回顾性长文档建模Transformer},
author = {丁思宇 and 商骏远 and 王硕欢 and 孙宇 and 田昊 and 吴华 and 王海峰},
year = {2021},
eprint = {2012.15688},
archivePrefix = {arXiv},
primaryClass = {cs.CL}
}
@article{Xie2023ResiDualTW,
title = {ResiDual: 具有双重残差连接的Transformer},
author = {谢书芳 and 张会帅 and 郭俊良 and 谭旭 and 边江 and Hany Hassan Awadalla and Arul Menezes and 秦涛 and 严睿},
journal = {ArXiv},
year = {2023},
volume = {abs/2304.14802}
}











