<div align="center">
<h2><font color="red"> 🕺🕺🕺 Follow-Your-Pose 💃💃💃 </font></center> <br> <center>使用无姿态视频的姿态引导文本到视频生成(AAAI 2024)</h2>
[马悦*](https://mayuelala.github.io/), [何迎青*](https://github.com/YingqingHe), [覃小东](http://vinthony.github.io/), [王信涛](https://xinntao.github.io/), [陈思然](https://github.com/Sranc3), [单莹](https://scholar.google.com/citations?hl=zh-CN&user=4oXBp9UAAAAJ), [李秀](https://scholar.google.com/citations?user=Xrh1OIUAAAAJ&hl=zh-CN), 和 [陈祺峰](https://cqf.io)
<a href='https://arxiv.org/abs/2304.01186'><img src='https://yellow-cdn.veclightyear.com/35dd4d3f/d5acd9b5-114c-4379-96a5-7a9754e7984e.01186-red'></a>
<a href='https://follow-your-pose.github.io/'><img src='https://yellow-cdn.veclightyear.com/35dd4d3f/eff904cd-a2f3-4817-88af-f16197991608.png'></a> [](https://colab.research.google.com/github/mayuelala/FollowYourPose/blob/main/quick_demo.ipynb) [](https://huggingface.co/spaces/YueMafighting/FollowYourPose) [](https://openxlab.org.cn/apps/detail/houshaowei/FollowYourPose)  [](https://github.com/mayuelala/FollowYourPose)
</div>
<!--  -->
<table class="center">
<td><img src="https://yellow-cdn.veclightyear.com/35dd4d3f/d1203ce6-b94f-427b-a1d0-a1b9f2a35493.gif"></td>
<td><img src="https://yellow-cdn.veclightyear.com/35dd4d3f/9608c69f-e496-4ff2-b41e-ff509f4b82c1.gif"></td>
<tr>
<td width=25% style="text-align:center;">"男人坐在公园的椅子上"</td>
<td width=25% style="text-align:center;">"钢铁侠在街头"</td>
</tr>
<td><img src="https://yellow-cdn.veclightyear.com/35dd4d3f/d82eb45c-cc70-4abb-af64-ed2df73af985.gif"></td>
<td><img src="https://yellow-cdn.veclightyear.com/35dd4d3f/256e4517-dea6-4a4b-83fc-31de556e6cce.gif"></td>
<tr>
<td width=25% style="text-align:center;">"风暴兵在健身房"</td>
<td width=25% style="text-align:center;">"宇航员,地球背景,卡通风格"</td>
</tr>
</table >
## 💃💃💃 演示视频
https://github.com/mayuelala/FollowYourPose/assets/38033523/e021bce6-b9bd-474d-a35a-7ddff4ab8e75
## 💃💃💃 摘要
<b>简述:我们调整了文本到图像生成模型(例如稳定扩散)以从姿态和文本描述生成人物视频。</b>
<details><summary>点击查看完整摘要</summary>
> 生成文本可编辑和姿态可控的人物视频在创建各种数字人类时有着迫切的需求。然而,这项任务受限于缺乏包含视频-姿态字幕对和视频生成先验模型的综合数据集。在本研究中,我们设计了一种新颖的两阶段训练方案,可以利用容易获得的数据集(例如图像-姿态对和无姿态视频)和预训练的文本到图像(T2I)模型来获取姿态可控的人物视频。具体来说,在第一阶段中,仅使用关键点-图像对进行可控的文本到图像生成。我们学习了一个零初始化的卷积编码器来编码姿态信息。在第二阶段,通过添加可学习的时间自注意力和改良的跨帧自注意力模块,我们通过无姿态视频数据集来微调上述网络的运动。通过我们的新设计,我们的方法成功生成了连续可姿态控的人物视频,同时保持了预训练的T2I模型的编辑和概念组合能力。代码和模型将公开发布。
</details>
## 🕺🕺🕺 更新日志
- **[2024.03.15]** 🔥 🔥 🔥 我们发布了第二版跟随者 [Follow-Your-Click](https://follow-your-click.github.io/),这是第一个实现区域图像动画的框架。现在就试试吧!请给我们一个星星!⭐️⭐️⭐️ 😄
- **[2023.12.09]** 🔥 论文被AAAI 2024录取!
- **[2023.08.30]** 🔥 发布一些新结果!
- **[2023.07.06]** 🔥 发布了`浦源内容平台 demo`新版本 [](https://openxlab.org.cn/apps/detail/houshaowei/FollowYourPose)! 感谢上海AI实验室的支持!
- **[2023.04.12]** 🔥 发布本地gradio演示,您可以在本地运行它,只需A100/3090显卡即可。
- **[2023.04.11]** 🔥 发布`huggingface demo`中的一些案例。
- **[2023.04.10]** 🔥 发布`huggingface demo`新版本 [](https://huggingface.co/spaces/YueMafighting/FollowYourPose),支持`原始视频`和`骨架视频`作为输入。享受它吧!
- **[2023.04.07]** 发布`huggingface demo`的第一个版本。享受跟随您姿态的乐趣吧!您需要下载[skeleton video](https://github.com/mayuelala/FollowYourPose/tree/main/pose_example)或通过[mmpose](https://mmpose.readthedocs.io/en/latest/model_zoo_papers/backbones.html#hrnet-cvpr-2019)制作自己的骨架视频。另外,以`视频格式`为输入的第二版即将发布。
- **[2023.04.07]** 发布`colab notebook` [](https://colab.research.google.com/github/mayuelala/FollowYourPose/blob/main/quick_demo.ipynb) 并更新安装`requirements`!
- **[2023.04.06]** 发布`代码`,`配置`和`检查点`!
- **[2023.04.03]** 发布论文和项目页面!
## 💃💃💃 HuggingFace 演示
<table class="center">
<td><img src="https://yellow-cdn.veclightyear.com/35dd4d3f/98e377e7-90ad-4f3f-9c83-a9d8120900f0.png"></td>
<td><img src="https://yellow-cdn.veclightyear.com/35dd4d3f/adb66a97-bb37-4c06-af40-ef5a7eb61f32.png'></td>
</tr>
</table>
## 🎤🎤🎤 待办事项
- [X] 发布代码、配置和检查点
- [X] Colab
- [X] Hugging face gradio 示例
- [ ] 发布更多应用
## 🍻🍻🍻 设置环境
我们的方法使用cuda11、accelerator和xformers在8个A100上训练。
conda create -n fupose python=3.8
conda activate fupose
pip install -r requirements.txt
`xformers` 推荐用于A100 GPU以节省内存和运行时间。
<details><summary>点击查看 xformers 安装 </summary>
我们发现其安装不太稳定。您可以尝试以下轮子:
```bash
wget https://github.com/ShivamShrirao/xformers-wheels/releases/download/4c06c79/xformers-0.0.15.dev0+4c06c79.d20221201-cp38-cp38-linux_x86_64.whl
pip install xformers-0.0.15.dev0+4c06c79.d20221201-cp38-cp38-linux_x86_64.whl
我们的环境类似于Tune-A-video(官方 , 非官方)。您可以参阅他们以获取更多细节。
## 💃💃💃 训练
我们修复了 Tune-a-video 中的错误,并在 8 台 A100 上微调 stable diffusion-1.4。
要为文本到视频生成微调文本到图像的扩散模型,请运行以下命令:
```bash
TORCH_DISTRIBUTED_DEBUG=DETAIL accelerate launch \
--multi_gpu --num_processes=8 --gpu_ids '0,1,2,3,4,5,6,7' \
train_followyourpose.py \
--config="configs/pose_train.yaml"
🕺🕺🕺 推理
一旦训练完成,运行推理:
TORCH_DISTRIBUTED_DEBUG=DETAIL accelerate launch \
--gpu_ids '0' \
txt2video.py \
--config="configs/pose_sample.yaml" \
--skeleton_path="./pose_example/vis_ikun_pose2.mov"
你可以使用 mmpose 制作姿态视频,我们通过 HRNet 检测骨架。你只需要运行视频演示以获得姿态视频。记得将背景替换为黑色。
💃💃💃 本地 Gradio 演示
你可以在本地运行 Gradio 演示,所需设备为 A100/3090。
python app.py
然后演示将在本地 URL http://0.0.0.0:Port 上运行。
🕺🕺🕺 权重
[Stable Diffusion] Stable Diffusion 是一种潜在的文本到图像扩散模型,能够根据任何文本输入生成逼真的图像。预训练的 Stable Diffusion 模型可以从 Hugging Face 下载(例如,Stable Diffusion v1-4)。
[FollowYourPose] 我们还提供了我们的预训练检查点在 Huggingface。你可以下载它们并放入 checkpoints 文件夹中,以通过我们的模型进行推理。
FollowYourPose
├── checkpoints
│ ├── followyourpose_checkpoint-1000
│ │ ├──...
│ ├── stable-diffusion-v1-4
│ │ ├──...
│ └── pose_encoder.pth
💃💃💃 结果
我们展示了与各种姿态序列和文本提示相关的结果。
注意:该 Github 页面上的 mp4 和 gif 文件已压缩。请查看我们的 项目页面 以获取原始视频结果的 mp4 文件。
 |  |  |
| "特朗普,在山上" | "男人,在山上" | "宇航员,在山上" |
 |  |  |
| "女孩,简单背景" | "钢铁侠,在沙滩上" | "绿巨人,在山上" |
 | 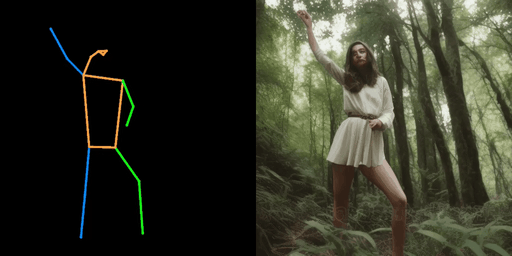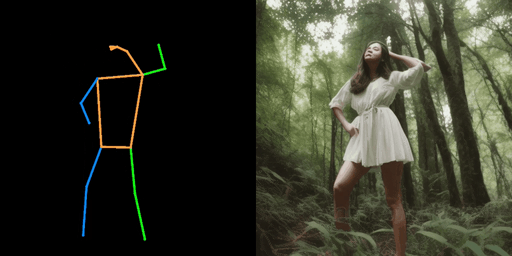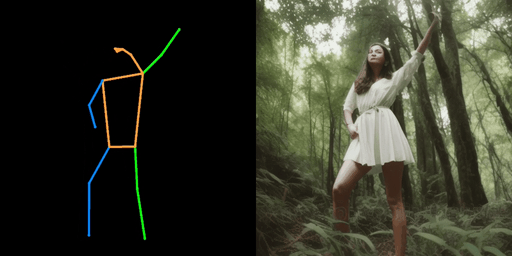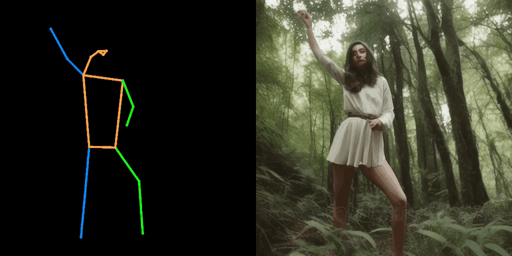 |  |
| "警察,在街上" | "女孩,在森林里" | "钢铁侠,在街上" |
 |  | 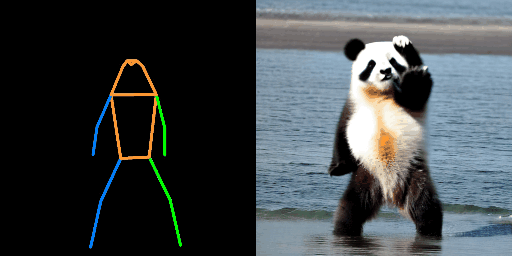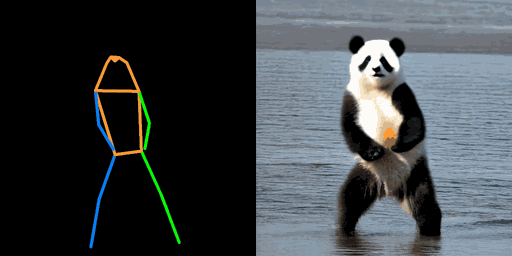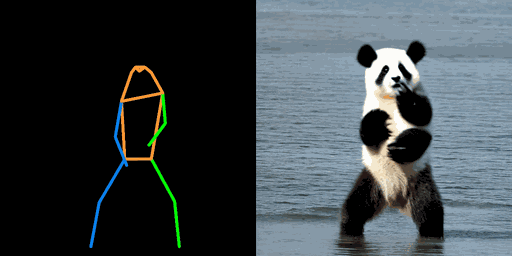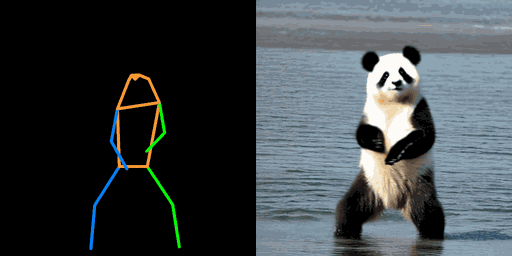 |
| "机器人,在撒哈拉沙漠" | "钢铁侠,在沙滩上" | "熊猫,在海上" |
 |  |  |
|
| "一个男子在公园中,梵高风格" | "消防员在沙滩上" | "蝙蝠侠,棕色背景" |
 |  |  |
|
| "绿巨人,在海上" | "超人,在森林里" | "钢铁侠,在雪地里" |
 |  |  |
|
| "一个男子在森林里,Minecraft 造型" | "一个男子在海上,日落时分" | "詹姆斯·邦德,灰色简单背景" |
 |  |  |
|
| “在海上的熊猫。” | “在海上的暴风兵。” | “在月球上的宇航员。” |
 | 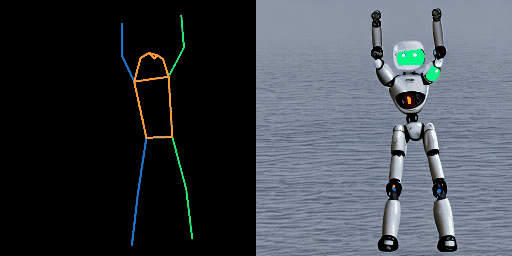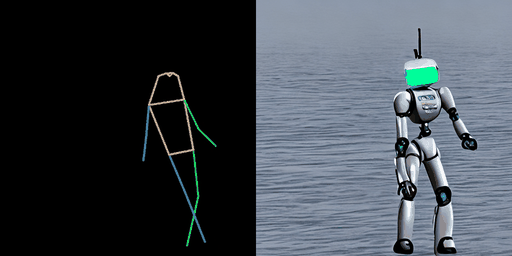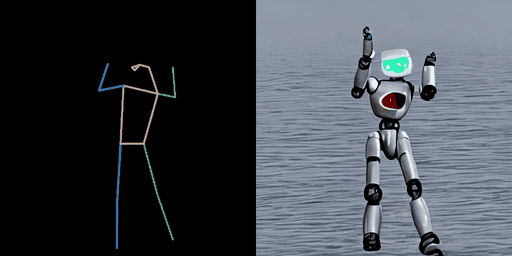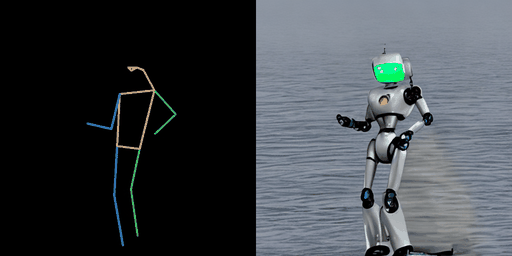 |  |
|
| “在月球上的宇航员。” | “在南极洲的机器人。” | “在海滩上的钢铁侠。” |
 | 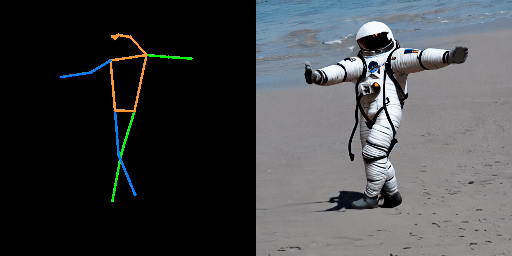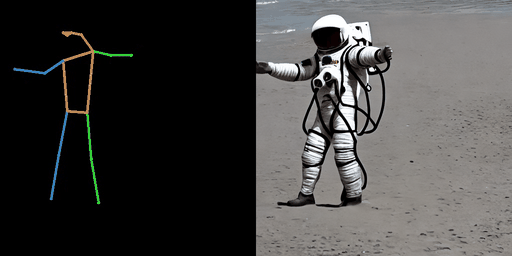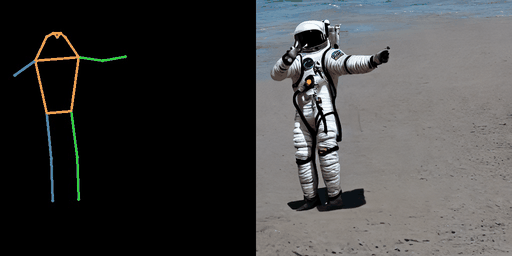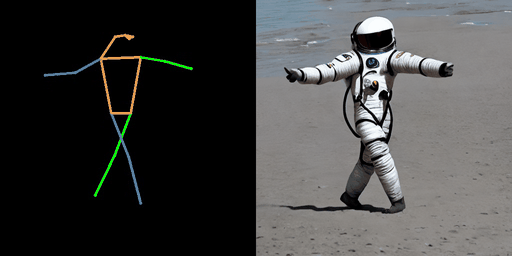 |  |
|
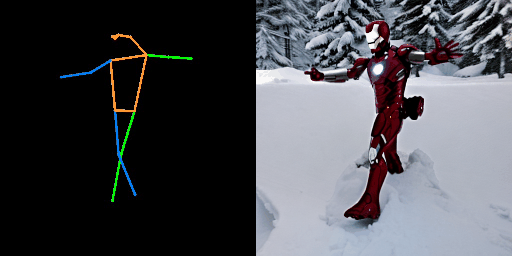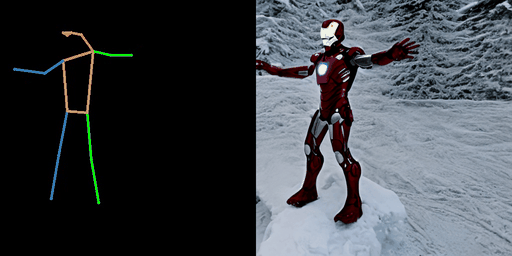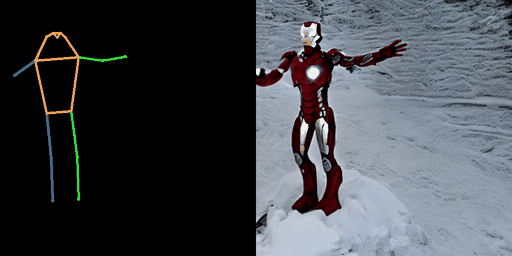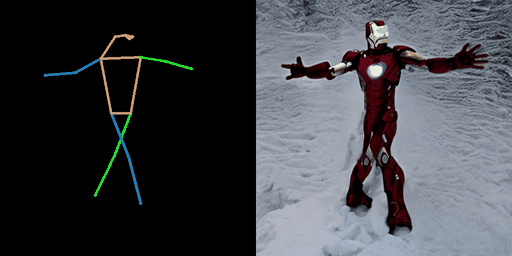
| “在沙漠中的奥巴马” | “在海滩上的宇航员。” | “在雪地上的钢铁侠。” |
 |  |  |
|
| “在海上的暴风兵。” | “在海滩上的钢铁侠。” | “在月球上的宇航员。” |
 |  |  |
|
| “在海滩上的宇航员。” | “在森林中的超人。” | “在海滩上的钢铁侠。” |
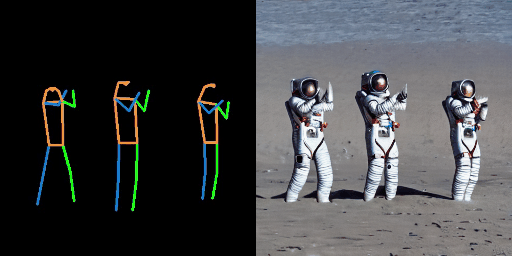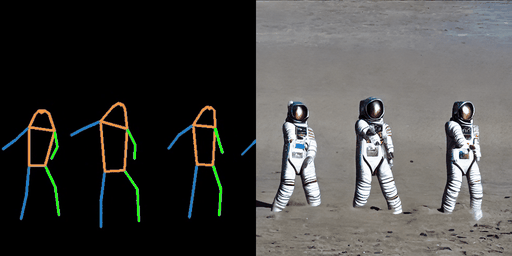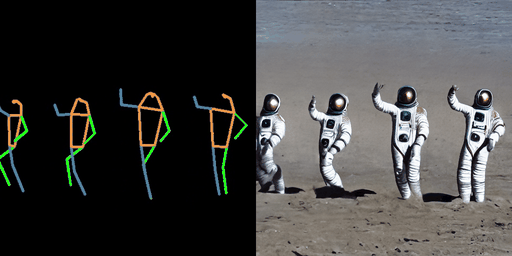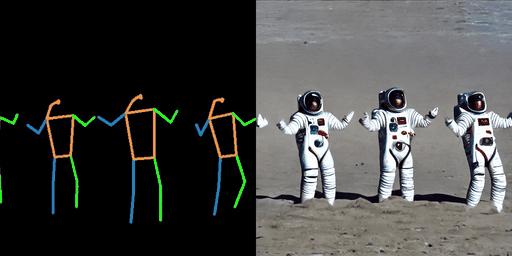 |  |  |
|
| “在海滩上的宇航员。” | “在南极洲的机器人。” | “在海滩上的暴风兵。” |

 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文










