
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文VideoComposer
VideoComposer: 具有运动可控性的组合式视频合成的官方代码库
更多示例请查看项目主页。
我们正在寻找有才华、有动力和富有想象力的研究人员加入我们的团队。如果您感兴趣,请随时发送您的简历至邮箱yingya.zyy@alibaba-inc.com
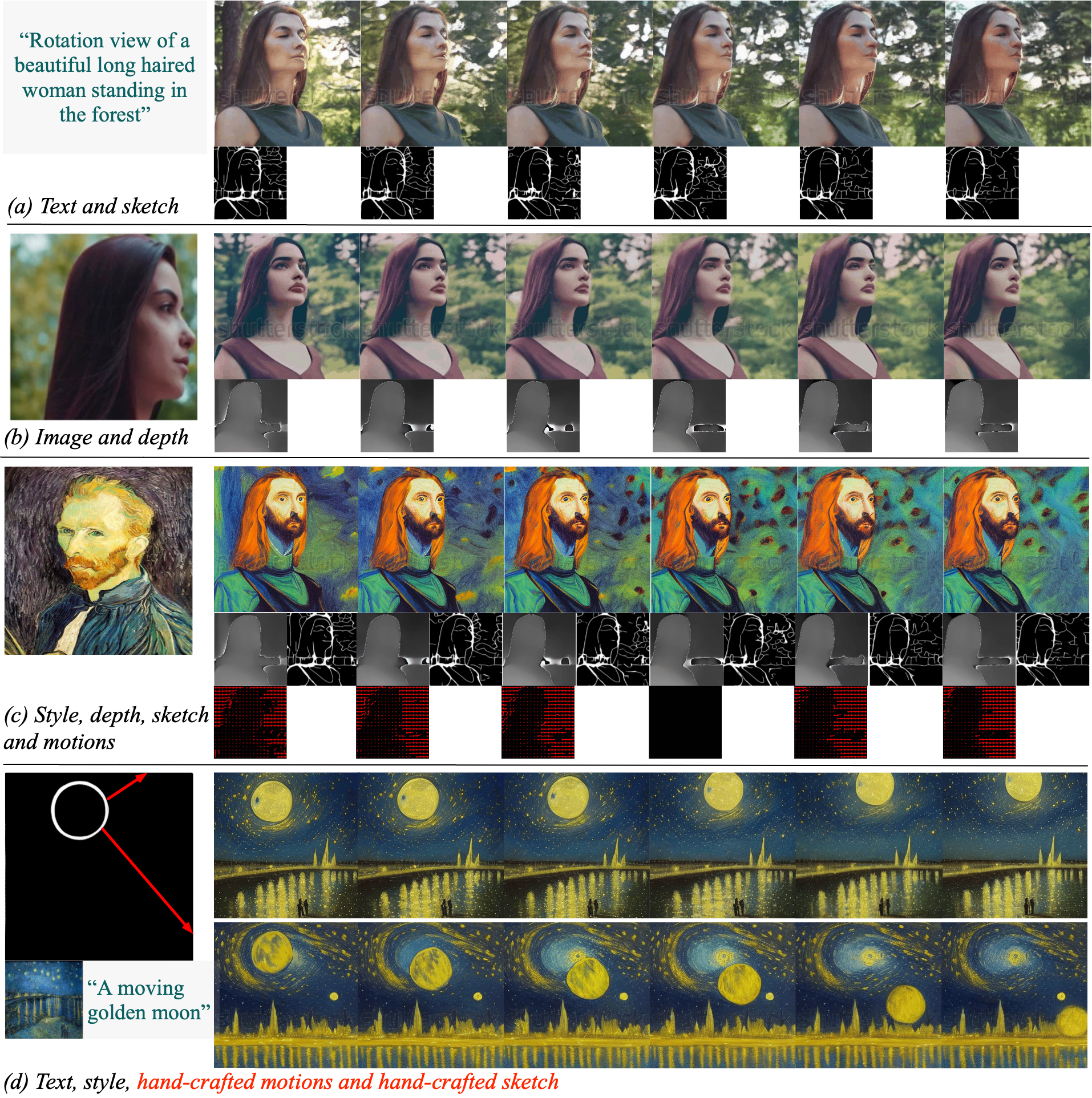
VideoComposer是一个可控的视频扩散模型,允许用户灵活地同时控制合成视频中的空间和时间模式,可以通过各种形式进行控制,如文本描述、草图序列、参考视频,甚至简单的手工制作动作和手绘图。
🔥新闻!!!
- [2023.10] 我们发布了高质量的I2VGen-XL模型,请参考网页
- [2023.08] 我们在ModelScope上发布了Gradio用户界面
- [2023.07] 我们发布了无水印的预训练模型,请参考模型卡片
待办事项
- 发布我们的技术论文和网页。
- 发布代码和预训练模型。
- 在ModelScope和Hugging Face上发布Gradio用户界面。
- 在ModelScope上发布可生成8秒无水印视频的预训练模型
方法
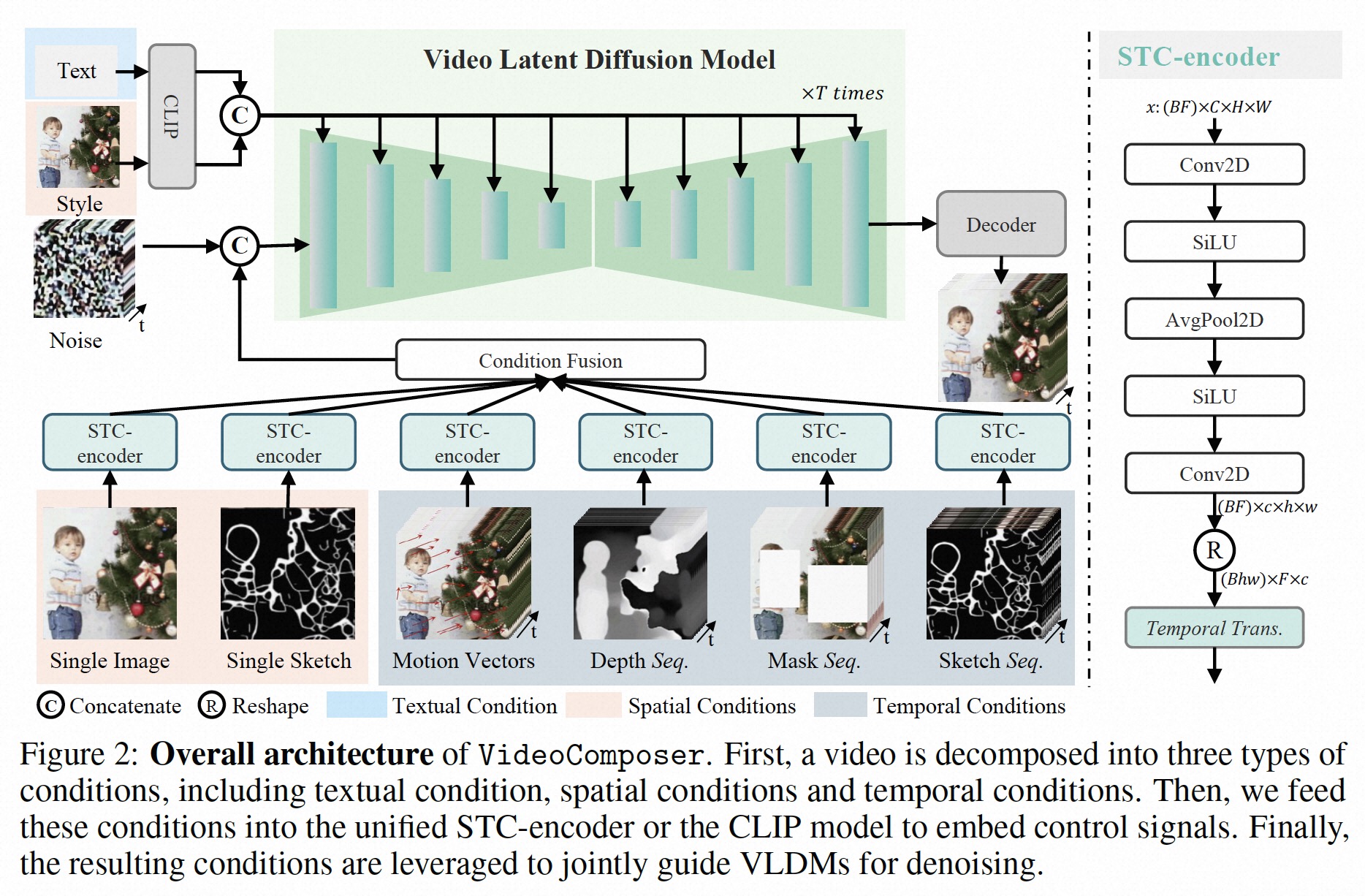
自行运行
1. 安装
要求:
- Python==3.8
- ffmpeg(用于运动矢量提取)
- torch==1.12.0+cu113
- torchvision==0.13.0+cu113
- open-clip-torch==2.0.2
- transformers==4.18.0
- flash-attn==0.2
- xformers==0.0.13
- motion-vector-extractor==1.0.6(用于运动矢量提取)
您也可以使用以下命令创建与我们相同的环境:
conda env create -f environment.yaml
2. 下载模型权重
通过以下命令下载所有模型权重:
!pip install modelscope
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('damo/VideoComposer', cache_dir='model_weights/', revision='v1.0.0')
接下来,按照下面显示的文件结构将这些模型放在model_weights文件夹中。
|--model_weights/
| |--non_ema_228000.pth
| |--midas_v3_dpt_large.pth
| |--open_clip_pytorch_model.bin
| |--sketch_simplification_gan.pth
| |--table5_pidinet.pth
| |--v2-1_512-ema-pruned.ckpt
您也可以从它们的原始项目中下载其中一些:
- "midas_v3_dpt_large.pth"在MiDaS
- "open_clip_pytorch_model.bin"在Open Clip
- "sketch_simplification_gan.pth"和"table5_pidinet.pth"在Pidinet
- "v2-1_512-ema-pruned.ckpt"在Stable Diffusion
为方便起见,我们在本仓库中提供了下载链接。
3. 运行
在这个项目中,我们提供了两种实现方式,可以帮助您更好地理解我们的方法。
3.1 使用自定义输入进行推理
您可以使用以下命令运行代码:
python run_net.py\
--cfg configs/exp02_motion_transfer.yaml\
--seed 9999\
--input_video "demo_video/motion_transfer.mp4"\
--image_path "demo_video/moon_on_water.jpg"\
--input_text_desc "A beautiful big moon on the water at night"
结果保存在outputs/exp02_motion_transfer-S09999文件夹中:
![]()
![]()
在某些情况下,如果您注意到颜色差异有显著变化,可以使用风格条件来调整颜色分布,使用以下命令。这在某些情况下可能会有帮助。
python run_net.py\
--cfg configs/exp02_motion_transfer_vs_style.yaml\
--seed 9999\
--input_video "demo_video/motion_transfer.mp4"\
--image_path "demo_video/moon_on_water.jpg"\
--style_image "demo_video/moon_on_water.jpg"\
--input_text_desc "A beautiful big moon on the water at night"
python run_net.py\
--cfg configs/exp03_sketch2video_style.yaml\
--seed 8888\
--sketch_path "demo_video/src_single_sketch.png"\
--style_image "demo_video/style/qibaishi_01.png"\
--input_text_desc "Red-backed Shrike lanius collurio"

python run_net.py\
--cfg configs/exp04_sketch2video_wo_style.yaml\
--seed 144\
--sketch_path "demo_video/src_single_sketch.png"\
--input_text_desc "枝头上有一只红背伯劳(lanius collurio)"


python run_net.py\
--cfg configs/exp05_text_depths_wo_style.yaml\
--seed 9999\
--input_video demo_video/video_8800.mp4\
--input_text_desc "一条闪闪发光的半透明鱼在一个小玻璃碗里游泳,碗里有多彩的石头,这条鱼看起来像玻璃做的"


python run_net.py\
--cfg configs/exp06_text_depths_vs_style.yaml\
--seed 9999\
--input_video demo_video/video_8800.mp4\
--style_image "demo_video/style/qibaishi_01.png"\
--input_text_desc "一条闪闪发光的半透明鱼在一个小玻璃碗里游泳,碗里有多彩的石头,这条鱼看起来像玻璃做的"


3.2 对视频进行推理
你可以使用以下命令运行代码:
python run_net.py \
--cfg configs/exp01_vidcomposer_full.yaml \
--input_video "demo_video/blackswan.mp4" \
--input_text_desc "一只黑天鹅在水中游泳" \
--seed 9999
这个命令将提取输入视频的不同条件,如深度、草图和运动向量,用于后续的视频生成,这些条件会保存在"outputs"文件夹中。任务列表在inference_multi.py中预定义。
除了上述用例,你还可以使用这个代码和模型探索更多可能性。请注意,由于扩散模型生成的样本具有多样性,你可以尝试不同的种子来生成更好的结果。
我们希望你喜欢使用它!😀
BibTeX
如果这个仓库对你有用,请引用我们的技术论文。
@article{2023videocomposer,
title={VideoComposer: Compositional Video Synthesis with Motion Controllability},
author={Wang, Xiang* and Yuan, Hangjie* and Zhang, Shiwei* and Chen, Dayou* and Wang, Jiuniu, and Zhang, Yingya, and Shen, Yujun, and Zhao, Deli and Zhou, Jingren},
booktitle={arXiv preprint arXiv:2306.02018},
year={2023}
}
致谢
我们要感谢几个先前工作对VideoComposer开发的贡献。这包括但不限于Composer、ModelScopeT2V、Stable Diffusion、OpenCLIP、WebVid-10M、LAION-400M、Pidinet和MiDaS。我们致力于在尊重这些原始贡献的基础上进行进一步的发展。
免责声明
这个开源模型是在WebVid-10M和LAION-400M数据集上训练的,仅用于研究/非商业用途。我们还使用内部视频数据训练了更强大的模型,这些模型可能在未来使用。











